

Python中的一些特殊函数
1. 过滤函数filter
定义:filter 函数的功能相当于过滤器。调用一个布尔函数bool_func来迭代遍历每个列表中的元素;返回一个使bool_func返回值为true的元素的序列。
a=[0,1,2,3,4,5,6,7] b=filter(None, a) print b
输出结果:[1, 2, 3, 4, 5, 6, 7]
2. 映射和归并函数map/reduce
这里说的map和reduce是Python的内置函数,不是Goggle的MapReduce架构。
2.1 map函数
map函数的格式:map( func, seq1[, seq2...] )
Python函数式编程中的map()函数是将func作用于列表中的每一个元素,并用一个列表给出返回值。如果func为None,作用等同于一个zip()函数。
下图是当列表只有一个的时候,map函数的工作原理图:
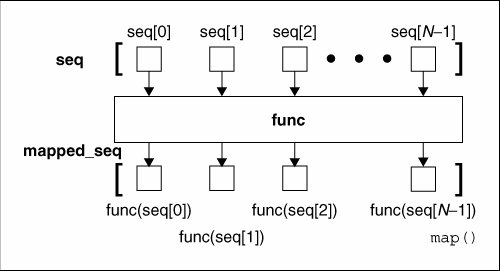
举个简单的例子:将列表中的元素全部转换为None。
map(lambda x : None,[1,2,3,4])
输出:[None,None,None,None]。
当列表有多个时,map()函数的工作原理图:

也就是说每个seq的同一位置的元素在执行过一个多元的func函数之后,得到一个返回值,这些返回值放在一个结果列表中。
下面的例子是求两个列表对应元素的积,可以想象,这是一种可能会经常出现的状况,而如果不是用map的话,就要使用一个for循环,依次对每个位置执行该函数。
print map( lambda x, y: x * y, [1, 2, 3], [4, 5, 6] ) # [4, 10, 18]
上面是返回值是一个值的情况,实际上也可以是一个元组。下面的代码不止实现了乘法,也实现了加法,并把积与和放在一个元组中。
print map( lambda x, y: ( x * y, x + y), [1, 2, 3], [4, 5, 6] ) # [(4, 5), (10, 7), (18, 9)]
还有就是上面说的func是None的情况,它的目的是将多个列表相同位置的元素归并到一个元组,在现在已经有了专用的函数zip()了。
print map( None, [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)] print zip( [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
注意:不同长度的多个seq是无法执行map函数的,会出现类型错误。
2.2 reduce函数
reduce函数格式:reduce(func, seq[, init]).
reduce函数即为化简,它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的func函数。在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
简单来说,可以用这样一个形象化的式子来说明:
reduce(func, [1,2,3])=func(func(1,2), 3)
reduce函数的工作原理图如下所示:

举个例子来说,阶乘是一个常见的数学方法,Python中并没有给出一个阶乘的内建函数,我们可以使用reduce实现一个阶乘的代码。
n = 5 print reduce(lambda x, y: x * y, range(1, n + 1)) # 120
那么,如果我们希望得到2倍阶乘的值呢?这就可以用到init这个可选参数了。
m = 2 n = 5 print reduce( lambda x, y: x * y, range( 1, n + 1 ), m ) # 240
3. 装饰器@
3.1 什么是装饰器(函数)?
定义:装饰器就是一函数,用来包装函数的函数,用来修饰原函数,将其重新赋值给原来的标识符,并永久的丧失原函数的引用。
3.2 装饰器的用法
先举一个简单的装饰器的例子:

#-*- coding: UTF-8 -*-
import time
def foo():
print 'in foo()'
# 定义一个计时器,传入一个,并返回另一个附加了计时功能的方法
def timeit(func):
# 定义一个内嵌的包装函数,给传入的函数加上计时功能的包装
def wrapper():
start = time.clock()
func()
end =time.clock()
print 'used:', end - start
# 将包装后的函数返回
return wrapper
foo = timeit(foo)
foo()
输出:
in foo() used: 2.38917518359e-05
python中专门为装饰器提供了一个@符号的语法糖,用来简化上面的代码,他们的作用一样。上述的代码还可以写成这样(装饰器专有的写法,注意符号“@”):
#-*- coding: UTF-8 -*-
import time
# 定义一个计时器,传入一个,并返回另一个附加了计时功能的方法
def timeit(func):
# 定义一个内嵌的包装函数,给传入的函数加上计时功能的包装
def wrapper():
start = time.clock()
func()
end =time.clock()
print 'used:', end - start
# 将包装后的函数返回
return wrapper
@timeit
def foo():
print 'in foo()'
#foo = timeit(foo)
foo()
其实对装饰器的理解,我们可以根据它的名字来进行,主要有三点:
1)首先装饰器的特点是,它将函数名作为输入(这说明装饰器是一个高阶函数);
2)通过装饰器内部的语法将原来的函数进行加工,然后返回;
3)原函数通过装饰器后被赋予新的功能,新函数覆盖原函数,以后再调用原函数,将会起到新的作用。
说白了,装饰器就相当于是一个函数加工厂,可以将函数进行再加工,赋予其新的功能。
装饰器的嵌套:
#!/usr/bin/python
# -*- coding: utf-8 -*-
def makebold(fn):
def wrapped():
return "<b>" + fn() + "</b>"
return wrapped
def makeitalic(fn):
def wrapped():
return "<i>" + fn() + "</i>"
return wrapped
@makebold
@makeitalic
def hello():
return "hello world"
print hello()
输出结果:
<b><i>hello world</i></b>
为什么是这个结果呢?
1)首先hello函数经过makeitalic 函数的装饰,变成了这个结果<i>hello
world</i>
2)然后再经过makebold函数的装饰,变成了<b><i>hello
world</i></b>,这个理解起来很简单。
4. 匿名函数lamda
4.1 什么是匿名函数?
在Python,有两种函数,一种是def定义,一种是lambda函数。
定义:顾名思义,即没有函数名的函数。Lambda表达式是Python中一类特殊的定义函数的形式,使用它可以定义一个匿名函数。与其它语言不同,Python的Lambda表达式的函数体只能有唯一的一条语句,也就是返回值表达式语句。
4.2 匿名函数的用法
lambda的一般形式是关键字lambda,之后是一个或者多个参数,紧跟的是一个冒号,之后是一个表达式:
lambda是一个表达式,而不是一个语句。
lambda主体是一个单一的表达式,而不是一个代码块。
举一个简单的例子,假如要求两个数之和,用普通函数或匿名函数如下:
1)普通函数: def func(x,y):return x+y
2)匿名函数: lambda x,y: x+y
再举一例:对于一个列表,要求只能包含大于3的元素。
1)常规方法:
L1 = [1,2,3,4,5]
L2 = []
for i in L1:
if i>3:
L2.append(i)
2)函数式编程实现: 运用filter,给其一个判断条件即可
def func(x): return x>3 filter(func,[1,2,3,4,5])
3)运用匿名函数,则更加精简,一行就可以了:
filter(lambda x:x>3,[1,2,3,4,5])
总结: 从中可以看出,lambda一般应用于函数式编程,代码简洁,常和reduce,filter等函数结合使用。此外,在lambda函数中不能有return,其实“:”后面就是返回值。
为什么要用匿名函数?
1) 使用Python写一些执行脚本时,使用lambda可以省去定义函数的过程,让代码更加精简。
2) 对于一些抽象的,不会别的地方再复用的函数,有时候给函数起个名字也是个难题,使用lambda不需要考虑命名的问题。
匿名函数的一个典型用法:
用List的内建函数list.sort进行排序:
list.sort(func=None, key=None, reverse=False)
% 排序
L = [2,3,1,4] L.sort() L [1,2,3,4] % 逆序排序 L = [2,3,1,4] L.sort(reverse=True) L [4,3,2,1]
对list的某一列进行排序有两种方法,一种是自己定义排序方法,取代默认的func;另一种是修改key。这两种方法均可结束匿名函数来简洁的实现。
使用匿名函数对list数据第二列进行排序(自定义排序逻辑,相当于修改func参数,参数x,y表示不属于同一行):
L = [('b',6),('a',1),('c',3),('d',4)]
L.sort(lambda x,y:cmp(x[1],y[1]))
L
[('a', 1), ('c', 3), ('d', 4), ('b', 6)]
第二种方法(使用key参数,对每一行的第二列排序):
L = [('b',6),('a',1),('c',3),('d',4)]
L.sort(key=lambda x:x[1])
L
[('a', 1), ('c', 3), ('d', 4), ('b', 6)]
使用匿名函数先对第二列进行排序,在对第一列进行排序(先对某一行的第2列进行排序,再对第1列进行排序):
L = [('d',2),('a',4),('b',3),('c',2)]
L.sort(key=lambda x:(x[1],x[0]))
L
[('c', 2), ('d', 2), ('b', 3), ('a', 4)]

