
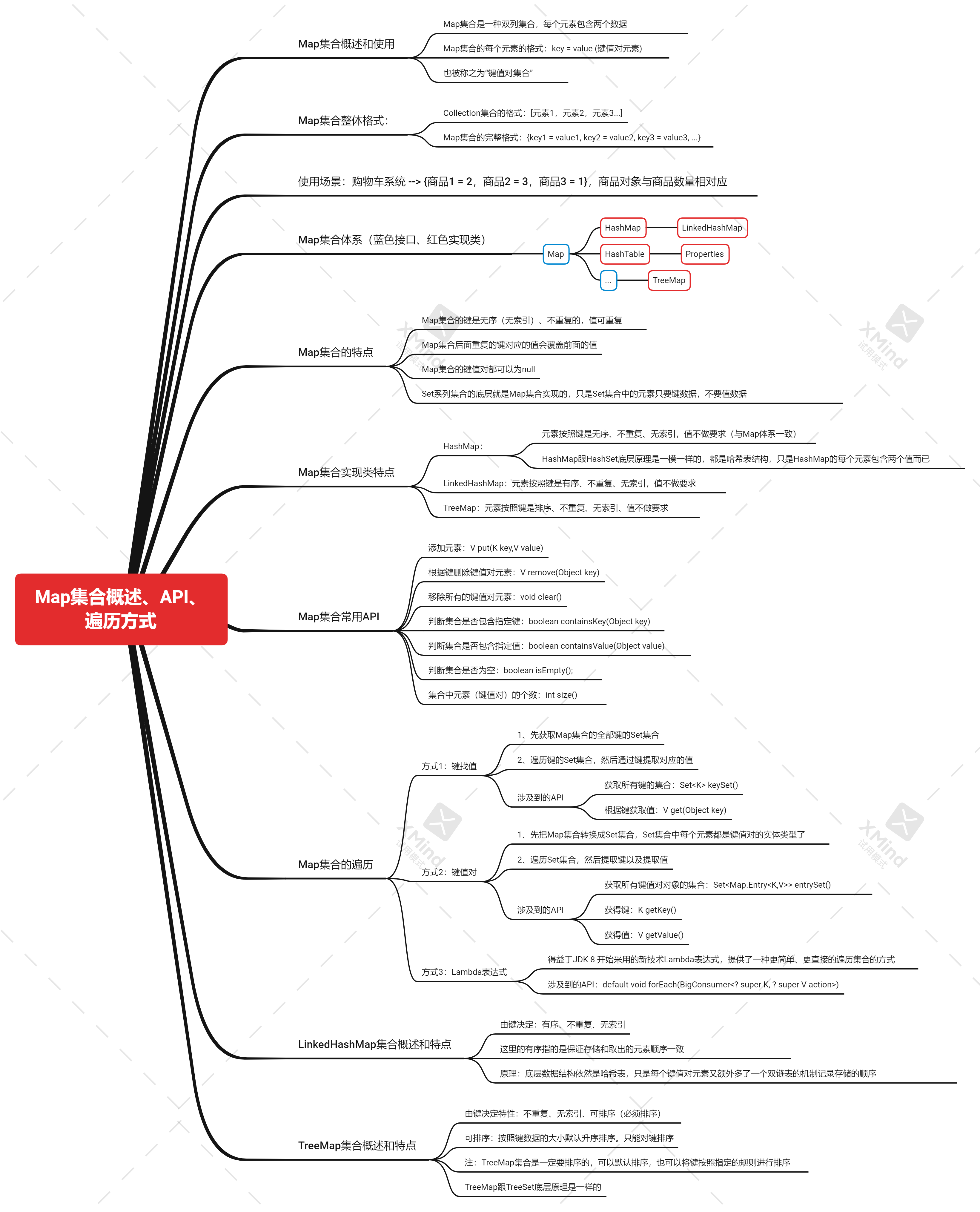
Java中Map集合概述、API、遍历方式
Map集合实现类的特点:
- HashMap:元素按照键是无序、不重复、无索引,值不做要求(与Map体系一致);
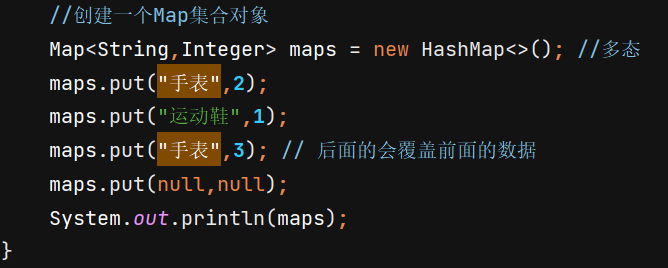
示例运行结果:

- LinkedHashMap:元素按照键是有序、不重复、无索引,值不做要求
由于上边的HashMap集合是采用多态的方式写的,因此此处我们仅需修改一处代码即可实现LinkedHashMap样例:

示例运行结果:
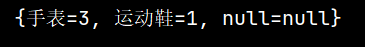
Map集合的概述以及常用的API:
1 import java.util.Collection;
2 import java.util.HashMap;
3 import java.util.Map;
4 import java.util.Set;
5
6 public class MapDemo {
7 public static void main(String[] args) {
8 Map<String,Integer> maps = new HashMap<>();
9 maps.put("Java",3);
10 maps.put("C#",2);
11 maps.put("HTML",1);
12 maps.put("MySQL",3);
13 maps.put("JavaScript",5);
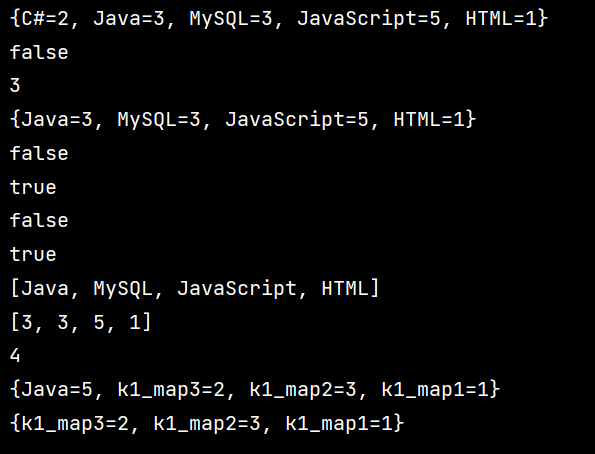
14 System.out.println(maps);
15 //清空集合
16 // maps.clear();
17 // System.out.println(maps);
18 //判断集合是否为空
19 System.out.println(maps.isEmpty());
20 //根据键获取对应值
21 System.out.println(maps.get("Java"));
22 //根据键删除整个元素
23 maps.remove("C#");
24 System.out.println(maps);
25 //判断是否包含某个键
26 System.out.println(maps.containsKey("html"));
27 System.out.println(maps.containsKey("HTML"));
28 //判断是否包含某个值
29 System.out.println(maps.containsValue(6));
30 System.out.println(maps.containsValue(3));
31 //获取所有的键
32 Set<String> keys = maps.keySet();
33 System.out.println(keys);
34 //获取所有的值
35 Collection<Integer> values = maps.values();
36 System.out.println(values);
37 //集合的大小
38 System.out.println(maps.size());
39 //合并其它的Map集合
40 Map<String,Integer> map1 = new HashMap<>();
41 map1.put("k1_map1",1);
42 map1.put("k1_map2",3);
43 map1.put("k1_map3",2);
44 Map<String,Integer> map2 = new HashMap<>();
45 map2.put("Java",5);
46 map2.putAll(map1);
47 System.out.println(map2); //把map1的元素拷贝一份放置到map2中
48 System.out.println(map1);
49 }
50 }
示例运行结果:
Map集合遍历
- 方式1:键找值
1 import java.util.HashMap;
2 import java.util.Map;
3 import java.util.Set;
4
5 public class MapDemo1 {
6 public static void main(String[] args) {
7 Map<String,Integer> maps = new HashMap<>();
8 maps.put("Java",3);
9 maps.put("C#",2);
10 maps.put("HTML",1);
11 maps.put("MySQL",3);
12 maps.put("JavaScript",5);
13 //键找值,1、获取集合中所有的键
14 Set<String> keys = maps.keySet();
15 //2、遍历每个键,根据键提取对应的值
16 for (String key : keys) {
17 System.out.println(key + "--->" + maps.get(key));
18 }
19 }
20 }
示例运行结果:
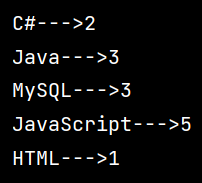
- 方式2:键值对
1 import java.util.HashMap;
2 import java.util.Map;
3 import java.util.Set;
4
5 public class MapDemo2 {
6 public static void main(String[] args) {
7 Map<String,Integer> maps = new HashMap<>();
8 maps.put("Java",3);
9 maps.put("C#",2);
10 maps.put("HTML",1);
11 maps.put("MySQL",3);
12 maps.put("JavaScript",5);
13 Set<Map.Entry<String, Integer>> entries = maps.entrySet();
14 for (Map.Entry<String, Integer> entry : entries) {
15 String key = entry.getKey();
16 int value = entry.getValue();
17 System.out.println(key + "--->" + value);
18 }
19 }
20 }
示例运行结果:
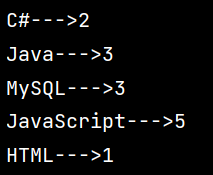
- 方式3:Lambda表达式
1 import java.util.HashMap;
2 import java.util.Map;
3 import java.util.function.BiConsumer;
4
5 public class MapDemo3 {
6 public static void main(String[] args) {
7 Map<String,Integer> maps = new HashMap<>();
8 maps.put("Java",3);
9 maps.put("C#",2);
10 maps.put("HTML",1);
11 maps.put("MySQL",3);
12 maps.put("JavaScript",5);
13 // maps.forEach(new BiConsumer<String, Integer>() {
14 // @Override
15 // public void accept(String key, Integer value) {
16 // System.out.println(key + "--->" + value);
17 // }
18 // });
19 maps.forEach((s, integer) -> System.out.println(s + "->" + integer));
20 }
21 }
- Map集合案例--统计投票人数
- 需求:某个班级有80名学生,现在需要组成秋游活动,班长提供了四个景点依次是A、B、C、D,每个学生只能选择一个景点,请统计出最终那个景点想去的人最多。
分析:
- 将80个学生的选择数据拿到程序中去。
- 定义一个Map集合用于存储最终统计的结果。
- 遍历80个学生选择的数据,看Map集合中是否存在,不存在存入“数据=1”
1 import java.util.HashMap;
2 import java.util.Map;
3 import java.util.Random;
4
5 public class MapTest {
6 public static void main(String[] args) {
7 //定义一个数组用于存储生成的四种选择
8 String[] selects = {"A","B","C","D"};
9 //随机数生成一组80个字符的字符串
10 Random random = new Random();
11 StringBuilder sb = new StringBuilder();
12 for (int i = 0; i < 80; i++) {
13 sb.append(selects[random.nextInt(4)]);
14 }
15 System.out.println(sb);
16 //定义一个Map集合{选项=人数}
17 Map<Character,Integer> maps = new HashMap<>();
18 //遍历方法一
19 //遍历80个学生的选择<方法一>
20 for (int i = 0; i < sb.length(); i++) {
21 char ch = sb.charAt(i);
22 //说明改选择不是第一次出现
23 if(maps.containsKey(ch)){
24 maps.put(ch,maps.get(ch) + 1);
25 }else {
26 //第一次出现改选择
27 maps.put(ch,1);
28 }
29 }
30 System.out.println(maps);
31 //遍历方法二(更加优化),先初始化maps集合,后边计算时可根据键直接增加选项的次数
32 // maps.put('A',0);
33 // maps.put('B',0);
34 // maps.put('C',0);
35 // maps.put('D',0);
36
37 //遍历80个学生的选择
38 // for (int i = 0; i < sb.length(); i++) {
39 // char ch = sb.charAt(i);
40 // maps.put(ch,maps.get(ch)+1);
41 // }
42 // System.out.println(maps);
43 }
44 }
示例运行结果:

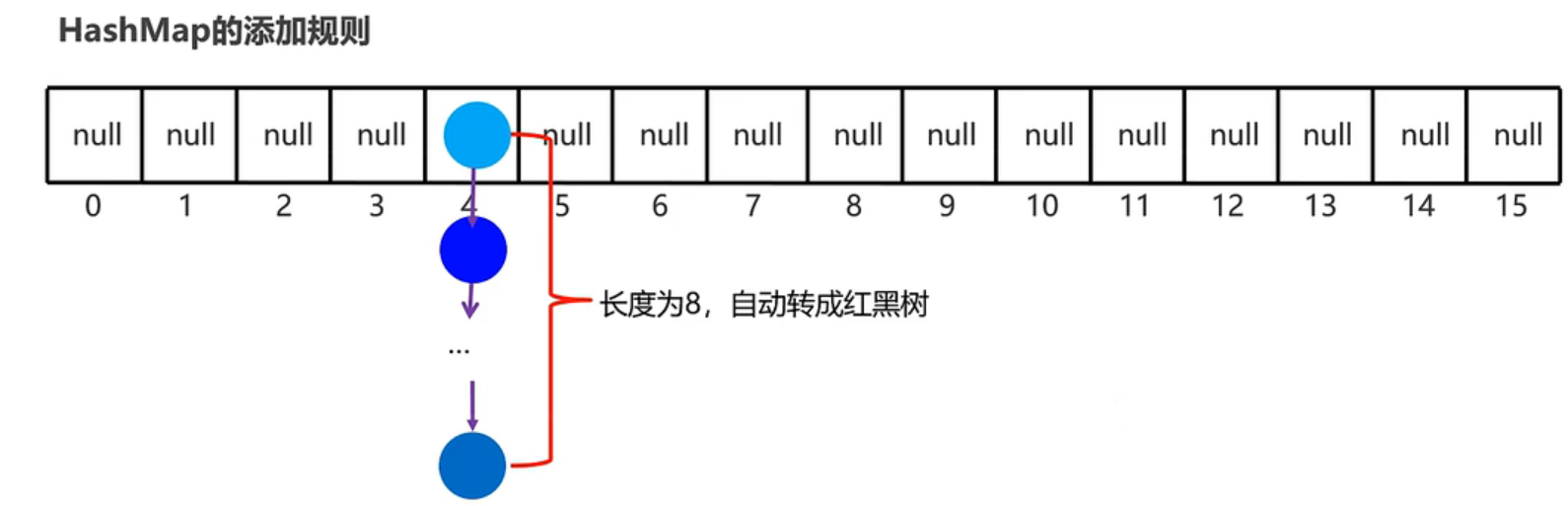
- HashMap底层原理:实际上,Set系列集合的底层就是Map实现的,只是Set集合中的元素只要键数据,不要值数据而已:
- 由键决定:无序、不重复、无索引。HashMap底层是哈希表结构;
- 依赖hashCode方法和equals方法保证键的唯一性;
- 如果键要存储的是自定义的对象,需要重写hashCode和equals方法;
- 基于哈希表,增删查改性能都较好

1 import com.companyName.d1_set.Student;
2
3 import java.util.HashMap;
4 import java.util.Map;
5
6 public class HashMapDemo {
7 public static void main(String[] args) {
8 Map<Student,String> stus = new HashMap<>();
9 Student s1 = new Student("Jack",21,'男');
10 Student s2 = new Student("Jack",21,'男');
11 Student s3 = new Student("Rose",20,'女');
12
13 System.out.println(s1.hashCode());
14 System.out.println(s2.hashCode());
15 System.out.println(s3.hashCode());
16
17 stus.put(s1,"美国");
18 stus.put(s2,"加拿大");
19 stus.put(s3,"古巴");
20
21 System.out.println(stus);
22 }
23 }
示例运行结果:

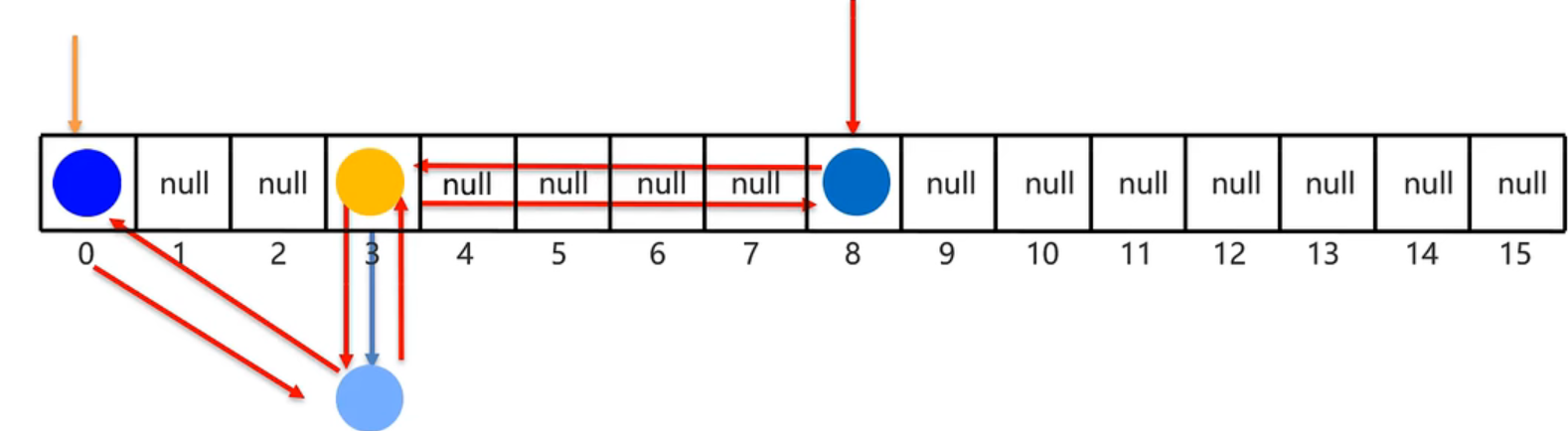
- LinkedHashMap集合底层数据结构:
TreeSet & TreeMap:

从源码中可以看到:TreeSet集合底层就是用TreeMap集合实现的
TreeMap集合排序方法:
- 方式一
- 类自定义比较规则:
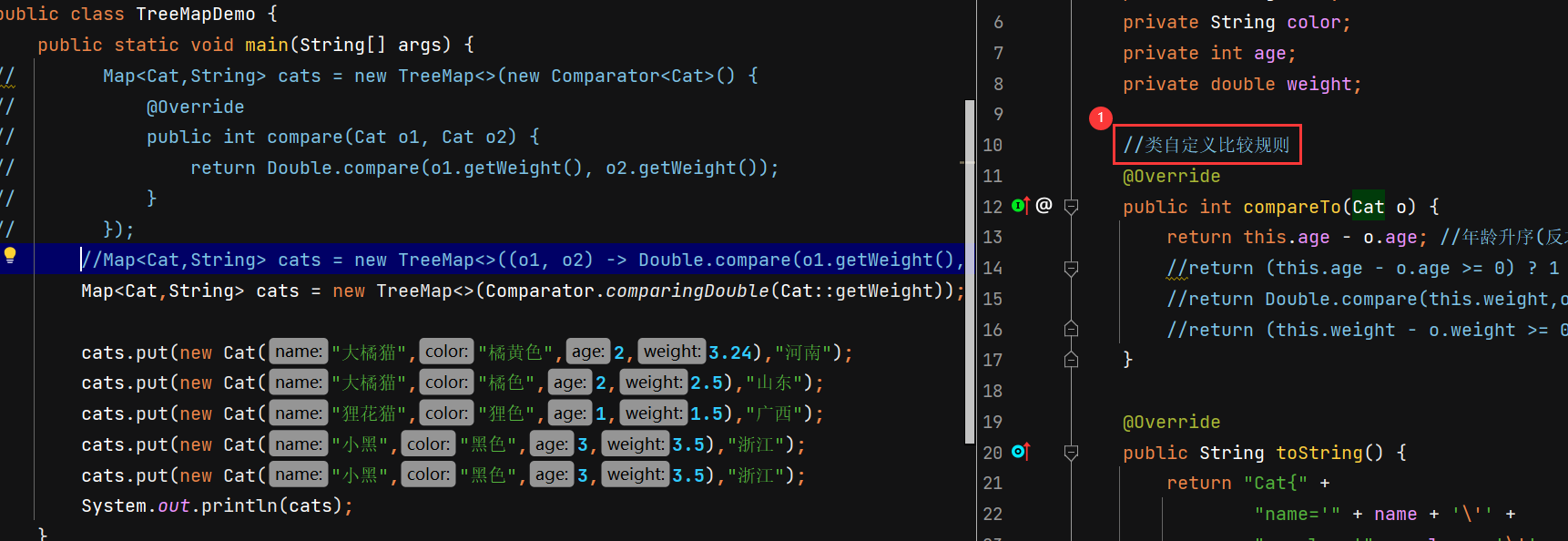
- 方式二
- 集合自带比较器:
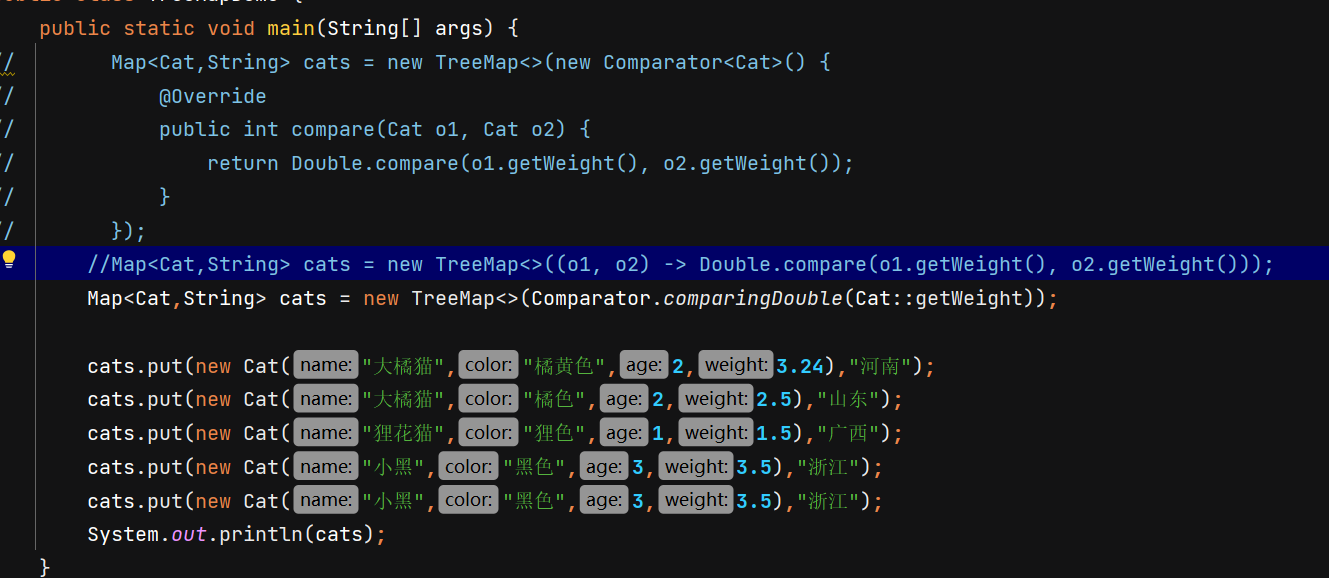
示例运行结果:


- 补充知识:集合的嵌套
- 案例:Map集合案例--统计投票人数
- 需求:某个班级有多名学生,现在需要组成秋游活动,班长提供了4个景点依次是A、B、C、D,每个学生可以选择多个景点,请统计出最终那个景点想去的人最多。
分析:
- 将学生选择的数据拿到程序中去,需要记住每个学生选择的情况;
- 定义Map集合用于存储最终统计的结果。
❌错误方法演示:
1 import java.util.*;
2
3 public class MapTest {
4 public static void main(String[] args) {
5 Map<String, Set<String>> maps = new HashMap<>();
6
7 //Set集合保存每个学生的选项
8 Set<String> sets1 = new HashSet<>();
9 Collections.addAll(sets1,"A","B","D");
10 maps.put("高锋",sets1);
11
12 Set<String> sets2 = new HashSet<>();
13 Collections.addAll(sets2,"B","D");
14 maps.put("韩寒",sets2);
15
16 Set<String> sets3 = new HashSet<>();
17 Collections.addAll(sets3,"A","C","D");
18 maps.put("赵冰",sets3);
19 System.out.println(maps);
20
21 //遍历集合统计元素
22 Map<String,Integer> ret = new HashMap<>();
23 ret.put("A",0);
24 ret.put("B",0);
25 ret.put("C",0);
26 ret.put("D",0);
27 //取出maps集合中嵌套的所有值,即内部的Set集合中的所有元素
28
29 List<String> values = maps.values();
30 }
31 }
本来想着用Set集合保存每个学生选择的景点以防止有一个景点被重选的,但是发现在第29行取出所有集合中元素的时候只能用Set类型的集合接收,而Set集合又是去重复的,这样做显然不合适,所以用
List集合更合适(从前端选择进行控制不能一个选项多选),可以保留重复的选项。

✔示例:
1 import java.util.*;
2
3 public class MapTest {
4 public static void main(String[] args) {
5 Map<String, List<String>> maps = new HashMap<>();
6
7 //Set集合保存每个学生的选项
8 List<String> list1 = new ArrayList<>();
9 Collections.addAll(list1,"A","B","D");
10 maps.put("高锋",list1);
11
12 List<String> list2 = new ArrayList<>();
13 Collections.addAll(list2,"B","D");
14 maps.put("韩寒",list2);
15
16 List<String> list3 = new ArrayList<>();
17 Collections.addAll(list3,"A","C","D");
18 maps.put("赵冰",list3);
19 System.out.println(maps);
20
21 //遍历集合统计元素
22 Map<String,Integer> ret = new HashMap<>();
23 ret.put("A",0);
24 ret.put("B",0);
25 ret.put("C",0);
26 ret.put("D",0);
27 //取出maps集合中嵌套的所有值,即内部的Set集合中的所有元素
28 Collection<List<String>> values = maps.values();
29 for (List<String> value : values) { // [A, B, D], [A, C, D], [B, D]
30 for (String s : value) { //逐个遍历集合中每个元素
31 ret.put(s,ret.get(s)+1);
32 }
33 }
34 System.out.println(ret);
35 }
36 }
示例运行结果:


