进程
多道技术
首先多道技术的目的是为了提升CPU利用率,降低程序等待时间。
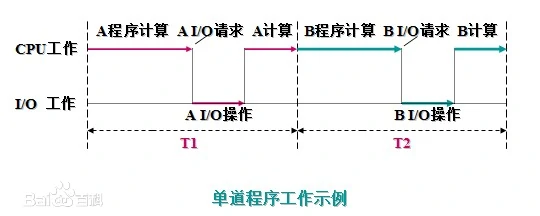
串行
在没有使用多道技术时,程序的执行是串行的——多个任务排队执行,上一个任务结束时才开始执行下一个任务,总耗时就是多个任务完整时间叠加。
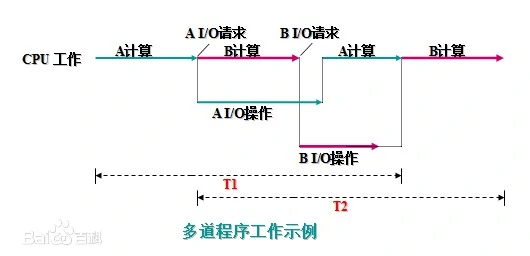
多道
使用了多道技术后,计算机内存中会同时存放几道相互独立的程序,在一个程序执行过程中,利用空闲提前准备,缩短总的执行时间并且还能提高CPU利用率。
CPU在两种情况下会被拿走:
- 程序遇到IO操作,CPU自动切走运行其他程序。
- 程序长时间占用CPU,系统发现之后也会强行切走CPU,保证其他程序也可以使用。
进程理论
程序是一堆没有被执行的代码(死的),进程是正在运行的程序(活的)。有了进程这个概念就可以更加精确的描述出一些实际状态。
进程调度算法发展史
1.先来先服务
那个程序先执行就会先运行完这个程序,然后再去执行下一个,如果第一个进程需要100h才能执行完毕,那么第二个进程就需要等待100h,所以这个算法对短作业不太友好。
2.短作业优先
会优先执行那些耗时短的进程。如果短作业有好几个,长作业就会到最好执行,所以对长作业不太友好。
3.时间片轮转法与多级反馈队列
时间片轮转法:先公平的将CPU分给每个人执行。
多级反馈队列:根据作业长短的不同再合理分配CPU执行时间。

总的来说,进程调度算法的目的就是为了能够让单核的计算机也能够做到运行多个程序。
并发与并行
并发
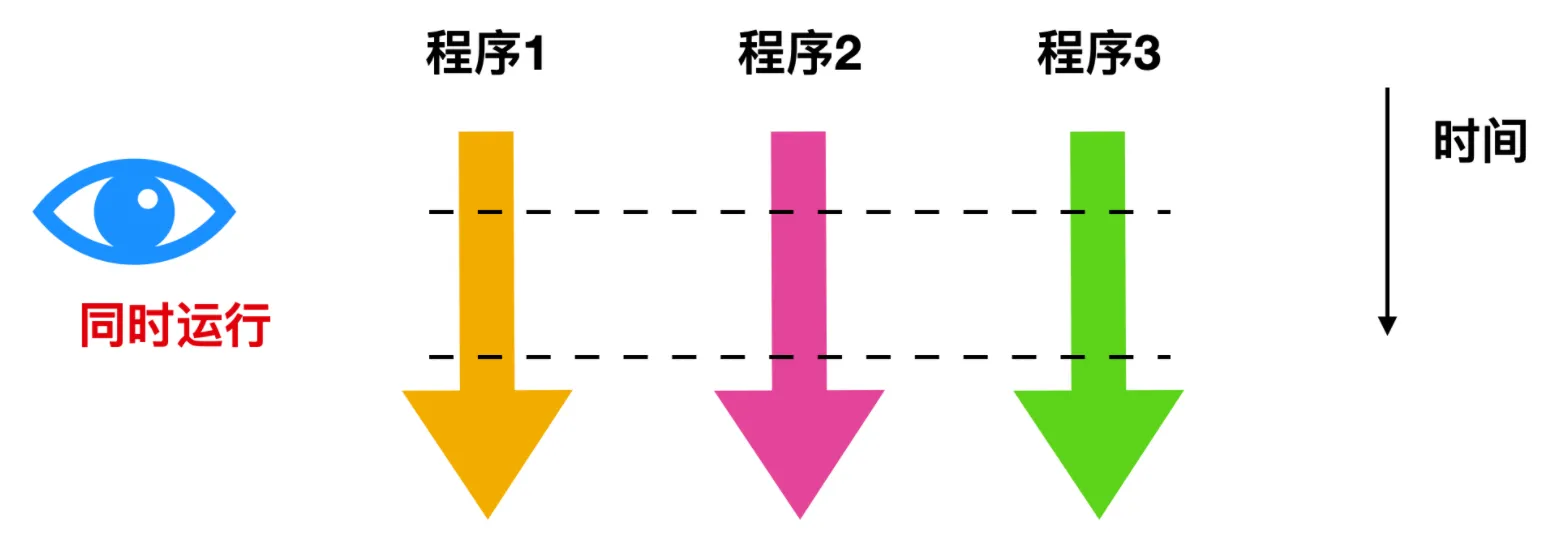
并发是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
简单的来说就是程序看上去像同时在执行就可以称之为是并发。
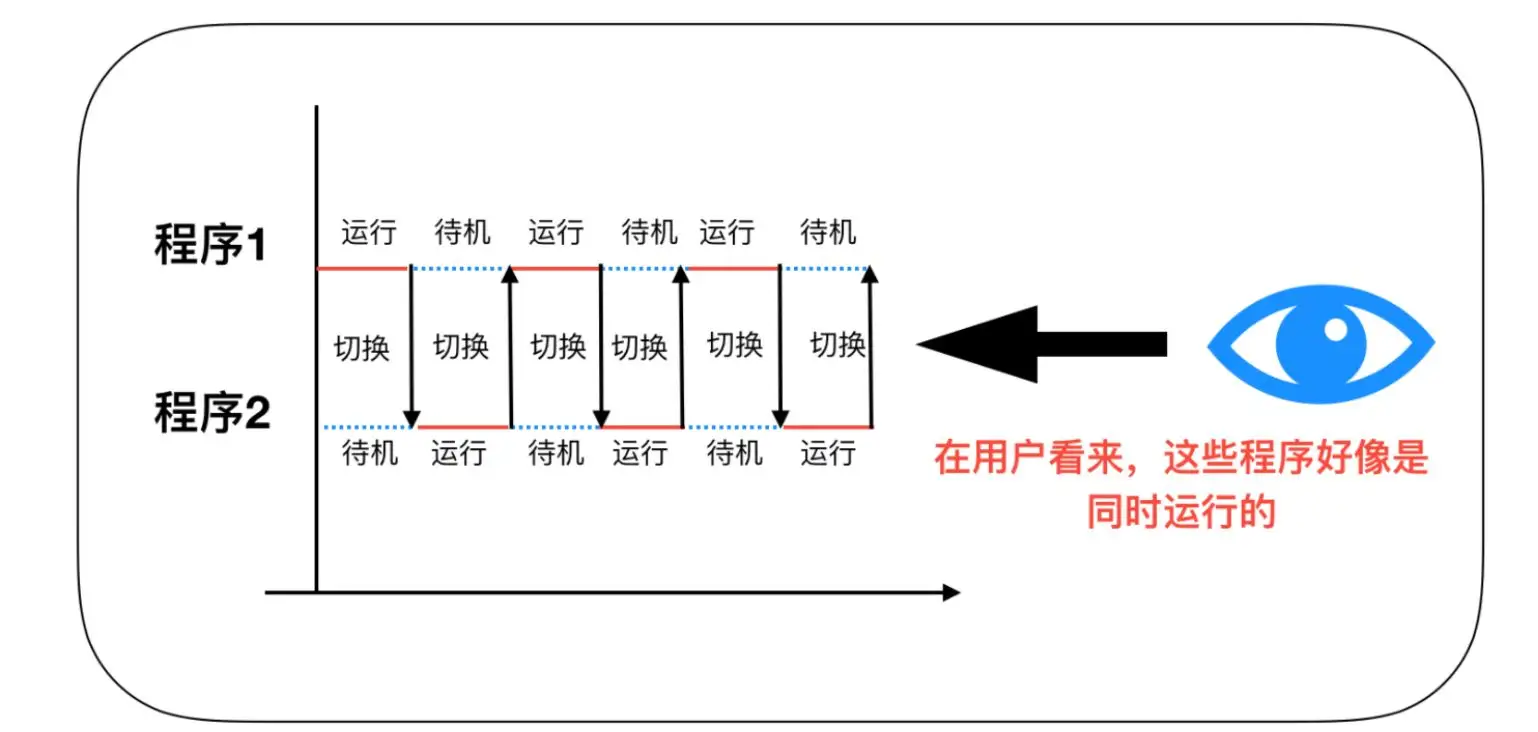
并行
并行是指在同一个时间段内,两个或多个程序执行,有时间上的重叠,必须同一时间同时运行才可以称之为并行。单核计算机肯定不能实现并行,必须要有多个CPU才能实现并行的效果。
拓展:高并发与高并行
高并发:如果我说我们写的软件可以支持1个亿的并发量,那么一个亿的用户来了之后都可以感觉到自己被服务着。
高并行:如果我说我们写的软件可以支持1个亿的并行量,这种明显是不可能的,这句话的言外之意就是计算机有一亿个CPU,这是目前做不到的。
同步与异步
同步指的是提交完任务之后原地等待任务的返回结果,期间不做任何事情。比如我喊你吃饭,你没有听到我就一直喊,喊道你回应我为止。
异步指的是提交完任务之后不愿地等待任务的结果,直接去做其他事情,有结果自动提醒。比如我喊你吃饭,我就去饭店了,不管你来不来。
阻塞与非阻塞
一个进程是有着三个状态的。
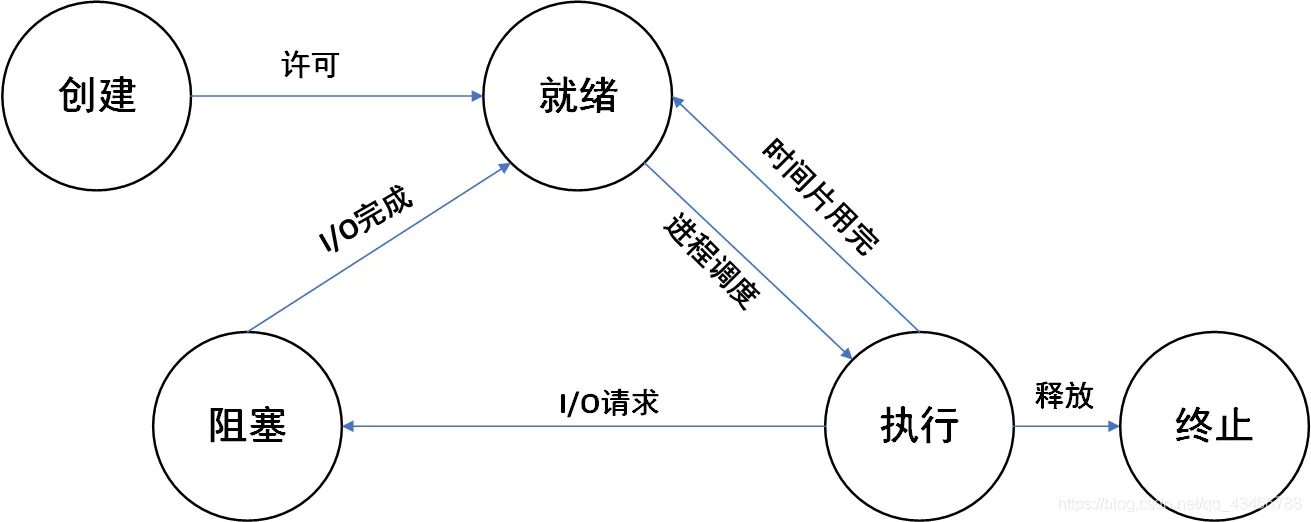
就绪态:程序之进入运行态之前肯定要处于就绪状态。
运行态:程序被CPU执行着。
阻塞态:程序执行过程中有IO操作,程序会等待。
阻塞就是处于阻塞态,非阻塞就是处于就绪态和运行态,所以如果想要尽可能的提升程序执行效率,就要想办法让我们的程序一直处于就绪态和运行态,就是不要有IO操作。
同步异步与阻塞非阻塞总结
同步异步是用来描述任务的提交方式,阻塞非阻塞是用来描述任务的执行状态,所以我们可以结合出四种情况:
同步阻塞:相当于在银行排队办理业务,期间不做任何事。
同步非阻塞:相当于银行排队办理业务,期间喝水吃东西,但是人还在队列中
异步阻塞:相当于通过银行叫号方式等待办理业务,等待时在椅子上坐着,但是不做任何事。
异步非阻塞:相当于通过银行叫号方式等待办理业务,等待时在椅子上坐着,期间喝水吃东西办公。这个状态就是程序运行的极致。
进程创建
创建的进程有两种方法:一种是直接双击一个应用图标;另一种是使用代码创建;

代码创建进程
可以使用Process方法创建进程,Process(target=函数名, args=(函数需要的参数))。
在windows中这种方式创建进程的代码必须写在__main__子代码中,否则会直接报错。在其他系统里就不需要写在__main__子代码中了。
from multiprocessing import Process
import time
def task(name):
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
# 创建一个进程对象
p = Process(target=task, args=('tom',))
# 告诉操作系统创建一个新的进程,启动进程
p.start()
print('主进程正在运行')
time.sleep(3)
print('主进程运行完毕')
可以使用重写Process类创建对象的方式创建进程,run方法是必须要重写的,因为创建的进程执行的就是run方法里面的代码。
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, username):
self.username = username
# 需要执行一下父类的方法,防止出现其他问题
super().__init__()
def run(self):
print('%s is running' % self.username)
time.sleep(3)
print('%s is over' % self.username)
if __name__ == '__main__':
p = MyProcess('tom')
p.start()
print('主进程正在运行')
time.sleep(3)
print('主进程运行完毕')
实现并发
让一个服务端可以与多个客户端同时交互。
服务端(Server)
import socket
from multiprocessing import Process
# 把与客户端交互写成函数
def task(sock):
while True:
msg = sock.recv(1024)
print(msg.decode('utf8'))
sock.send(b'from server')
if __name__ == '__main__':
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
client, addr = server.accept()
p = Process(target=task, args=(client, ))
p.start()
客户端(Client)
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
s = input('发送给服务端的消息:')
send_msg = 'from client: %s' % s
client.send(send_msg.encode('utf8'))
msg = client.recv(1024)
print(msg.decode('utf8'))
join方法
子进程的执行与主进程的执行是同时执行的,那么有没有什么办法可以让主进程执行放在子进程后呢?
进程对象有一个join方法,它的作用是让主进程代码等待子进程代码运行完毕再执行。
from multiprocessing import Process
import time
def task(name):
print(f'子进程:{name} is running')
time.sleep(3)
print(f'子进程:{name} is over')
if __name__ == '__main__':
p = Process(target=task, args=('tom', ))
p.start()
p.join()
print('主进程开始')
time.sleep(1)
print('主进程结束')
执行结果:
子进程:tom is running
子进程:tom is over
主进程开始
主进程结束
如果多个子进程同时用join方法,子进程之间都是异步执行的,互不干涉,主进程开始执行的时间是耗时最长的子进程结束时间。
from multiprocessing import Process
import time
def task(name, n):
print(f'{name} is running')
time.sleep(n)
print(f'{name} is over')
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1))
p2 = Process(target=task, args=('tony', 2))
p3 = Process(target=task, args=('kevin', 3))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
end_time = time.time() - start_time
print('主进程', f'总耗时:{end_time}')
"""
执行结果:
jason is running
kevin is running
tony is running
jason is over
tony is over
kevin is over
主进程 总耗时:3.134154796600342
"""
如果是一个start一个join交替执行,那么总耗时就是各个任务耗时的总和。
from multiprocessing import Process
import time
def task(name, n):
print(f'{name} is running')
time.sleep(n)
print(f'{name} is over')
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1))
p2 = Process(target=task, args=('tony', 2))
p3 = Process(target=task, args=('kevin', 3))
start_time = time.time()
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
end_time = time.time() - start_time
print('主进程', f'总耗时:{end_time}')
"""
执行结果:
jason is running
jason is over
tony is running
tony is over
kevin is running
kevin is over
主进程 总耗时:6.306329250335693
"""