python之常见内置模块
re模块
在python中是无法使用正则表达式的,所以我们需要借助re模块。
导入re模块
import re
findall()方法
"""
语法结构:
re.findall(正则表达式, 待匹配字符串)
"""
# 作用:返回所有符合条件的数据,并且组织成了列表
res = re.findall('a.', 'ab1cata1b')
print(res) # 输出:['ab', 'at', 'a1']
search()方法
"""
语法结构:
re.search(正则表达式, 待匹配字符串)
"""
# 作用:查找到一个符合条件的数据就结束,没有则返回None
res = re.search('a.', 'ab1cata1b')
print(res) # <_sre.SRE_Match object; span=(0, 2), match='ab'>
# 需要调用group()输出,没有符合条件调用会报错
print(res.group()) # 输出:ab
match()方法
"""
语法结构:
re.match(正则表达式, 待匹配字符串)
"""
# 作用:从字符串的开头匹配,如果没有则直接返回。相当于给正则表达式自动添加了'^'符号
res = re.match('a.', 'ab1cata1b')
print(res) # <_sre.SRE_Match object; span=(0, 2), match='ab'>
# 需要调用group()输出,没有符合条件调用会报错
print(res.group()) # 输出:ab
finditer()方法
"""
语法结构:
re.finditer(正则表达式, 待匹配字符串)
"""
# 作用:与findall相同,但是返回值是一个迭代器对象
res = re.finditer('a.', 'ab1cata1b')
print(res) # <callable_iterator object at 0x0000028A08A7C400>
"""返回的是一个迭代器对象"""
compile()方法
"""
语法结构:
re.compile(正则表达式)
"""
# 作用:提前包装好后续需要经常使用的正则表达式
obj = re.compile('a.')
print(re.findall(obj,'ab1cata1b'))
"""写一遍之后,直接反复调用即可"""

re模块补充说明
在正则表达式中,'()'的作用是进行分组,但是在re模块中,正则表达式中的'()'代表着其他的意思。

1、在findall()方法中,匹配到值会优先返回括号内的值
import re
res = re.findall('a(b)c', 'abc|a1bc|d|abc|2')
print(res) # 输出:['b', 'b']
"""匹配时先忽略括号,有结果时返回括号内的值"""
# 如果有多个括号
res = re.findall('(a)(b)c', 'abc|a1bc|d|abc|2')
print(res) # 输出:[('a', 'b'), ('a', 'b')]
"""匹配时先忽略括号,有结果时把括号内的值组成元组存到列表中"""
# 如果想让'()'表示在正则表达式中的意义,可以在括号里加'?:'
res = re.findall('a(?:b)c', 'abc|a1bc|d|abc|2')
print(res) # 输出:['abc', 'abc']
2、在search()方法中,具有分组的功能
import re
res = re.search('a(b)c', 'abc|a1bc|d|abc|2')
print(res) # <_sre.SRE_Match object; span=(0, 3), match='abc'>
print(res.group()) # 输出:abc
print(res.group(0)) # 0是默认值,输出内容与不加参数一致
print(res.group(1)) # 输出:b
"""可以给group()添加参数输出括号的值,但是参数不能超过括号的个数"""
# 如果有多个括号
res = re.search('(a)(b)(c)', 'abc|a1bc|d|abc|2')
print(res.group(1)) # 输出:a
print(res.group(2)) # 输出:b
print(res.group(3)) # 输出:c
print(res.group(4)) # 报错,超出括号分组的个数了
"""可以给group()添加参数按顺序输出"""
# 分组后可以给每个组起别名
res = re.search('(?P<name1>a)(?P<name2>b)c', 'abc|a1bc|d|abc|2')
print(res.group('name1')) # 输出:a
print(res.group('name2')) # 输出:b
"""?P<别名>放在括号中,<>内的名称就是别名"""
# 如果想让'()'表示在正则表达式中的意义,可以在括号里加'?:'
res = re.search('a(?:b)c', 'abc|a1bc|d|abc|2')
print(res.group(1)) # 报错,没有分组的内容
3、括号在match()、search()、finditer()中用法相同
4、括号在findall()、compile()中用法相同
collections模块
除了基本数据类型外,collections模块提供了额外的数据类型。
1、namedtuple(),生成一个可以从名字访问值的元组
from collections import namedtuple
# 生成一个叫做"坐标"的元组,传列表类型表示把列表中的值当作元组的key
point = namedtuple('坐标', ['x', 'y'])
# 传值要与列表元素个数对应
p1 = point(1, 2)
p2 = point(5, 6)
print(p1, p2) # 输出:坐标(x=1, y=2) 坐标(x=5, y=6)
# 按照名字来取值
print(p1.x) # 输出:1
print(p2.y) # 输出:6
# 也可以传字符串类型,每个key用空格隔开
person = namedtuple('人物', '姓名 age')
p1 = person('jason', 18)
p2 = person('kevin', 28)
print(p1, p2) # 输出:人物(姓名='jason', age=18) 人物(姓名='kevin', age=28)
print(p1.姓名, p1.age) # 输出:jason 18
2、deque(),双端队列,首尾都可以进出数据
from collections import deque
q = deque([1, 2, 3])
print(q) # 输出:deque([1, 2, 3])
q.append(4) # 默认从尾部添加数据
print(q) # 输出:deque([1, 2, 3, 4])
q.appendleft(0) # 从首部添加数据
print(q) # 输出:deque([0, 1, 2, 3, 4])
q.pop() # 默认从尾部弹出数据
print(q) # 输出:deque([0, 1, 2, 3])
q.popleft() # 从首部弹出数据
print(q) # 输出:deque([1, 2, 3])
3、OrderedDict(),生成一个有序字典
# 基本数据类型的字典是无序的
d1 = dict([('a', 1), ('b', 2), ('c', 3)])
d2 = dict([('b', 2), ('c', 3), ('a', 1)])
print(d1 == d2) # 输出:True
# 生成有序字典
from collections import OrderedDict
od1 = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
od2 = OrderedDict([('b', 2), ('c', 3), ('a', 1)])
print(od1 == od2) # 输出:False
"""
有序字典的方法与普通的字典类型相同
注意:给有序字典添加键值对是按顺序添加的
"""
4、defaultdict(),给字典的值设置一个默认值
from collections import defaultdict
# 设置默认值为列表类型
my_dict = defaultdict(list)
# 给列表添加值
my_dict['k1'].append('aaa')
# 不传值默认生成空列表
my_dict['k2']
print(my_dict) # 输出:defaultdict(<class 'list'>, {'k1': ['aaa'], 'k2': []})
print(my_dict['k2']) # 输出:[]
5、Counter(),统计所有字符出现的次数,返回的值可以当字典使用
from collections import Counter
res1 = 'asdbnbasdbanba'
r1 = Counter(res1)
print(r1) # 输出:Counter({'a': 4, 'b': 4, 's': 2, 'd': 2, 'n': 2})
print(r1.get('a')) # 输出:4
res2 = ['a', 45, 'qq', 2, 2, 'a']
r2 = Counter(res2)
print(r2) # 输出:Counter({'a': 2, 2: 2, 45: 1, 'qq': 1})

queue模块
简单讲解,生成队列
import queue
q = queue.Queue(3) # 最大只能放三个元素
# 存放元素
q.put(11)
q.put(22)
q.put(33)
"""此时队列满了,继续添加会原地等待,直到队列空出位置"""
# 获取元素
print(q.get()) # 输出:11
print(q.get()) # 输出:22
print(q.get()) # 输出:33
"""此时队列空了,继续获取会原地等待,直到队列有数据"""
time模块
和时间有关系的计算我们就要用到这个模块。

常用方法(sleep()、time())
import time
time.sleep(10) # 括号内为程序停止时间,单位为秒
time.time() # 获取当前时间戳
time模块有三种表示时间的格式:时间戳、结构化时间、格式化时间。
-
时间戳:
距离1970年1月1日0时0分0秒至此相差的秒数,使用time.time()可以获取时间戳。
-
结构化时间:
结构化时间中有9个元素,分别有着不同的意义,使用time.localtime()可以获取结构化时间。
import time t = time.localtime() print(t) # 输出:time.struct_time(tm_year=2022, tm_mon=3, tm_mday=29, tm_hour=16, tm_min=43, tm_sec=12, tm_wday=1, tm_yday=88, tm_isdst=0)索引 属性 值 0 tm_year(年) 比如2011 1 tm_mon(月) 1 - 12 2 tm_mday(日) 1 - 31 3 tm_hour(时) 0 - 23 4 tm_min(分) 0 - 59 5 tm_sec(秒) 0 - 60 6 tm_wday(星期) 0 - 6(0表示周一) 7 tm_yday(一年中的第几天) 1 - 366 8 tm_isdst(是否是夏令时) 默认为0 -
格式化时间:
我们可以最直观看懂的时间格式,使用time.strftime()可以获取格式化时间。
import time t = time.strftime("%Y-%m-%d %X") print(t) # 输出:2022-03-29 16:45:37特殊符号表
符号 意义 %y 两位数的年份表示(00 - 99) %Y 四位数的年份表示(000 - 9999) %m 月份(01 - 12) %d 月内中的一天(0 - 31) %H 24小时制小时数(0 - 23) %I 12小时制小时数(01 - 12) %M 分钟数(00 - 59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001 - 366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身 只需要记住常用的即可。
时间格式的转换
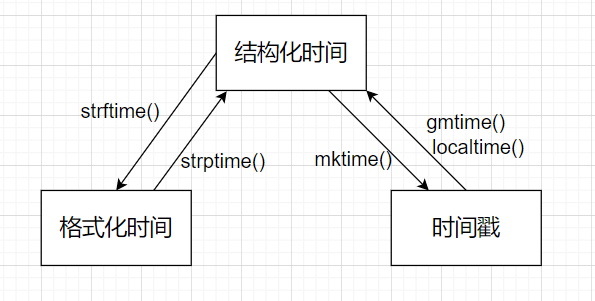
时间戳<==>结构化时间
# 时间戳-->结构化时间
time.gmtime(时间戳) # 返回结构化时间
time.localtime(时间戳) # 返回结构化时间
"""上述的方法返回的结构化时间是UTC时间"""
# 结构化时间-->时间戳
time.mktime(结构化时间) # 返回时间戳
格式化时间<==>结构化时间
# 结构化时间-->格式化时间
time.strftime(格式定义,结构化时间) # 结构化时间参数若不传,则显示当前时间
# 格式化时间-->结构化时间
time.strptime(格式化时间,对应的格式)
datetime模块
导入模块
import datetime
获取当前年月日
dt = datetime.date.today()
print(dt) # 输出:2022-03-29
# 获取年份
print(dt.year) # 输出:2022
# 获取月份
print(dt.month) # 输出:3
# 获取天数
print(dt.day) # 输出:29
# 获取星期(0-6),星期一开始
print(dt.weekday()) # 输出:1
# 获取星期(1-7),星期一开始
print(dt.isoweekday()) # 输出:2
获取当前年月日,时分秒
dt = datetime.datetime.today()
# 或者
dt = datetime.datetime.now()
print(dt) # 输出:2022-03-29 17:25:12.431065
# 获取年份
print(dt.year) # 输出:2022
# 获取月份
print(dt.month) # 输出:3
# 获取天数
print(dt.day) # 输出:29
# 获取时
print(dt.hour) # 输出:17
# 获取分
print(dt.minutes) # 输出:25
# 获取秒
print(dt.second) # 输出:12
# 获取星期(0-6),星期一开始
print(dt.weekday()) # 输出:1
# 获取星期(1-7),星期一开始
print(dt.isoweekday()) # 输出:2
时间差timedelta()
# 获取当前时间
date_time = datetime.datetime.today()
print(date_time) # 输出:2022-03-29 17:34:11.180282
# 括号内可以是多种时间选项,这里是四天的意思,hour=3代表3小时等等...
time_delta = datetime.timedelta(days=4)
print(date_time + time_delta) # 输出:2022-04-02 17:34:11.180282
自定义datetime()
dt = datetime.datetime(2001, 7, 28, 12, 12)
print(dt) # 输出:2001-07-28 12:12:00
datetime()也可以转成格式化时间,转换方法与结构化转格式化时间相同。
random模块
random模块讲究的就是一个随机。
导入模块
import random
产生[0,1)的随机小数
print(random.random())
产生[2.3,3.5)的随机小数
print(random.uniform(2.3,3.5))
产生[2,10]的随机整数
print(random.randint(2,10))
随机打乱数据集
l = [1, 2, 3, 4, 5]
random.shuffle(l)
print(l)
从数据集随机选择一个
l = [1, 2, 3, 4, 5]
print(random.choice(l))
随机指定个数抽样
l = [1, 2, 3, 4, 5]
# 从l中随机取2个
print(random.sample(l, 2))
os模块
os模块主要是与操作系统打交道。
导入os模块
import os
创建单层文件夹,路径必须要存在
os.mkdir(路径/文件夹名)
"""不写路径就是在当前目录创建文件夹"""
创建多层文件夹,路径不存在会自动创建文件夹
os.makedirs(路径/文件夹名/文件夹名...)
"""不写路径就是在当前目录创建文件夹"""
删除一层空的文件夹
os.rmdir(路径/文件夹名)
"""不写路径就是在当前目录删除文件夹"""
删除多层空文件夹,删除一层文件夹后,如果上一级的文件夹是空的,会一直删除上一级文件夹直到文件夹不为空
os.removedirs(路径/文件夹名)
"""不写路径就是在当前目录删除文件夹"""
查看某个路径下所有的文件名称
os.listdir(路径)
"""不写路径就是在当前目录"""
删除文件(无法删除文件夹)
os.remove(文件名)
"""不写路径就是在当前目录"""
重命名文件(无法重命名文件夹)
os.rename(文件名,新文件名)
"""不写路径就是在当前目录"""
返回当前路径
os.getcwd()
改变当前路径
os.chdir(路径)
返回当前执行文件所在的绝对路径
os.path.dirname(__file__) # 固定搭配
# 每嵌套一层就会往上一层路径
os.path.dirname(os.path.dirname(__file__))
返回当前执行文件自身的路径
os.path.abspath(__file__) # 固定搭配
判断文件是否存在(可以判断文件夹和文件)
os.path.exists(路径)
判断路径是否是一个文件夹
os.path.isdir(路径)
判断路径是否是一个文件
os.path.isfile(路径)
拼接成路径
os.path.join(路径1, 路径2)
"""路径2最好不要用绝对路径"""
返回文件大小(单位:字节),如果路径是文件夹,返回值为0
os.path.getsize(路径)
判断路径是否是一个文件夹
os.path.isdir(路径)
在cmd窗口执行括号内的命令,直接显示
os.system(命令)
# 如
os.system('dir') # 获取当前目录信息
在cmd窗口执行括号内的命令,获取执行结果
os.popen(命令).read()
把执行文件与所在路径分开存储在元组中
os.path.split(__file__) # 固定搭配
文件时间问题
os.path.getatime(path) # 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间

sys模块
sys模块主要是跟python解释器打交道
导入模块
import sys
以列表形式返回当前执行文件所在的sys.path
sys.path
自定义命令行操作
sys.argv
"""
在cmd窗口中执行py文件:python py文件 命令1 命令2 ...
输出:[py文件名, 命令1, 命令2, ...]
"""
sys.argv[0] # 返回py文件名
sys.argv[1] # 返回第一个命令
sys.argv[2] # 返回第二个命令
...
返回解释器版本信息
sys.version
获取平台信息
sys.platform
正常退出程序后输出内容
sys.exit(内容) # 程序正常退出才会输出
json模块
json是什么?
json是一个序列化模块,主要用于跨语言传输数据。json格式的数据是不同编程语言之间数据交互的媒介,基本上每个编程语言都能识别json格式的数据,识别的过程叫做反序列化。
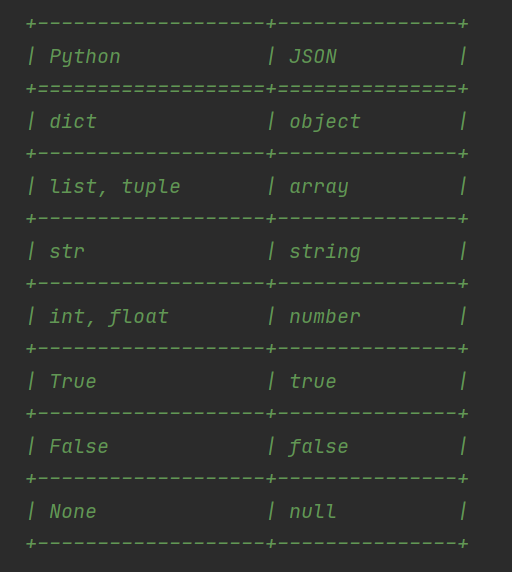
json本质上是字符串类型的,在python中,它的格式与字典极其相似。
字典的数据格式:
{'username':'abc','age':18}
json数据格式:
{"username": "abc", "age": 18}
可以看到,它们的区别就在引号上,双引号是json格式数据独有的标志符号。
json模块
导入
import json
序列化:将数据转换成json格式字符串
json.dumps(要序列化的数据)
# 案例
d = {'username': 'abc', 'age': 18}
res = json.dumps(d)
print(res, type(res))
# 输出:{"username": "abc", "age": 18} <class 'str'>
反序列化:将json格式字符串转换成对应的数据类型
json.loads(要反序列化的数据)
# 案例
d = '{"username": "abc", "age": 18}'
res = json.loads(d)
print(res, type(res))
# 输出:{'username': 'abc', 'age': 18} <class 'dict'>
将数据转成json格式字符串后写入文件
json.dump(要序列化的数据, 文件名)
# 案例
d = {"username": "abc", "age": 18} # json格式数据
with open(r'a.txt','w',encoding='utf8') as f:
json.dump(d, f)
将存储json格式字符串的文件读取后转成对应的数据类型
json.load(文件名)
# 案例
with open(r'a.txt','r',encoding='utf8') as f:
print(json.load(f))
可以被序列化的数据类型可以查看JSONEncoder的源码
subprocess模块
subprocess模块可以实现远程操作其他计算机的功能,会在cmd窗口执行命令,动态获取命令执行并返回结果。
导入模块
import subprocess
run()方法
subprocess.run(args, *, stdin=None, input=None, stdout=None,
stderr=None, capture_output=False, shell=False, cwd=None,
timeout=None, check=False, encoding=None, errors=None,
text=None, env=None, universal_newlines=None)
来自菜鸟教程:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:缓冲区大小。当创建标准流的管道对象时使用,默认-1。
0:不使用缓冲区
1:表示行缓冲,仅当universal_newlines=True时可用,也就是文本模式
正数:表示缓冲区大小
负数:表示使用系统默认的缓冲区大小。 - stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在 Unix 平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- shell:如果该参数为 True,将通过操作系统的 shell 执行指定的命令。
- cwd:用于设置子进程的当前目录。
- env:用于指定子进程的环境变量。如果 env = None,子进程的环境变量将从父进程中继承。
Popen()方法
subprocess.Popen(args, bufsize=-1, executable=None, stdin=None,
stdout=None, stderr=None, preexec_fn=None, close_fds=True,
shell=False, cwd=None, env=None, universal_newlines=False,
startupinfo=None, creationflags=0,restore_signals=True,
start_new_session=False, pass_fds=(),
*, encoding=None, errors=None)
# 执行ls命令
res = subprocess.Popen('ls',shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
# 获取正确命令执行之后的结果
res.stdout.read().decode('utf8')
# 获取错误命令执行之后的结果
res.stderr.read().decode('utf8')
来自菜鸟教程:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:缓冲区大小。当创建标准流的管道对象时使用,默认-1。
0:不使用缓冲区
1:表示行缓冲,仅当universal_newlines=True时可用,也就是文本模式
正数:表示缓冲区大小
负数:表示使用系统默认的缓冲区大小。 - stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在 Unix 平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- shell:如果该参数为 True,将通过操作系统的 shell 执行指定的命令。
- cwd:用于设置子进程的当前目录。
- env:用于指定子进程的环境变量。如果 env = None,子进程的环境变量将从父进程中继承。
hashlib模块
加密的概念
加密,是以某种特殊的算法改变原有的数据,当其他人获得数据时,也无法了解数据的内容。简单的来说,就是将明文(人看得懂)数据通过一些手段变成密文数据(人看不懂),密文数据的表现形式一般都是一串没有规则的字符串。
模块详解
hashlib模块提供了一些加密数据的算法,比如:MD5,SHA1等等,这里我只讲解MD5算法在hashlib模块中的基本用法。
1.导入模块
import hashlib
2.MD5算法,最好赋值给一个变量名,以便后续操作
md5 = hashlib.md5()
3.加密数据(数据要bytes类型)
md5.update(数据)
4.获取加密后的数据
print(md5.hexdigest())
举例说明
一、
import hashlib
# 实例化
md5 = hashlib.md5()
# 加密bytes类型数据
md5.update(b'hello')
# 获取加密后的数据
print(md5.hexdigest()) # 输出:5d41402abc4b2a76b9719d911017c592
二、
import hashlib
# 实例化
md5 = hashlib.md5()
# 分开加密,但是效果与一起加密一样的
md5.update(b'he')
md5.update(b'llo')
# 获取加密后的数据
print(md5.hexdigest()) # 输出:5d41402abc4b2a76b9719d911017c592
加密补充
- 加密之后的结果是无法直接解密的,唯一解密的方法就是用穷举法,反复的试,看看自己的数据加密后是否和需要解密的数据一样。
- 如果想增加解密的难度,可以加一下干扰项数据一起加密,如我把数据解密后,在添加一段加密'123'的代码,md5.update(b'123')。
- 还可以用动态的干扰项,如用户名的一部,当前时间等等一起进行加密处理。
- 如果需要加密的数据过大,可以把数据进行切片读取并加密的操作。

logging模块
logging模块也就是所谓的日志模块,就是记录程序的各个环境信息,便于后续的查看。
日志按照重要程度分为五个级别(由低到高):debug-->info-->warning-->error-->critical。
默认只有达到warning警告级别及以上才会记录日志。
import logging
# 不会打印这块代码的内容
logging.debug('debug message')
logging.info('info message')
# 只会打印下面代码的内容
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
基本使用
import logging
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8', )
# 所有的格式不需要记忆 后续几乎都是拷贝加修改
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler, ],
level=logging.info
)
logging.error('FBI WARNING')
配置参数
来源:https://www.cnblogs.com/Dominic-Ji/articles/16046931.html#_label14
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
针对日志模块,我们只需要听流程思路,最后复制粘贴即可,无需详细记忆
logging模块详解
主要组成部分
- logger对象,用于产生日志
# 第一步,创建logger对象
logger = logging.getLogger()
-
filter对象,用于过滤日志,可以不用管,handler对象自带了基本的过滤操作。
-
handler对象,用于控制日志的输出位置(文件、终端等)
# 第二步,控制输出的位置
# 输出到文件中,可以自定义路径
hd1 = logging.FileHandler('a1.log', encoding='utf-8')
# 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8')
# 输出到终端
hd3 = logging.StreamHandler()
- format对象,控制日志的输出格式
# 第三步,编辑日志的输出格式
# 格式一:
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
# 格式二:
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
- 给logger对象绑定handler对象
# 第四步,绑定handler对象
# 绑定hd1
logger.addHandler(hd1)
# 绑定hd2
logger.addHandler(hd2)
# 绑定hd3
logger.addHandler(hd3)
- 给handler绑定format对象
# 第五步,绑定format对象
# 让hd1输出fm1的格式
hd1.setFormatter(fm1)
# 让hd2输出fm2的格式
hd2.setFormatter(fm2)
# 让hd3输出fm1的格式
hd3.setFormatter(fm1)
- 设置日志等级
# 第六步,设置日志等级
logger.setLevel(10) # 输出debug及以上的等级的日志
"""
等级:
debug 10
info 20
warning 30
error 40
critical 50
"""
- 输出内容到日志
# 第七步,自定义输出内容
logger.debug('这是一段debug日志内容!!')
logger.info('这是一段info日志内容!!')

配置日志字典
想要输出日志还有一个更加好用的方法,我们可以先配置一个日志字典,定义好参数后,只需要用三行代码就可以把日志输出了。
导入模块和配置输出路径和输出格式
import logging
import logging.config
# 定义复杂的日志输出格式, 其中name为getlogger指定的名字
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]'
# 定义一个简单版的输出格式
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
配置日志字典
# 配置日志字典
LOGGING_DIC = {
'version': 1, # 不用管
'disable_existing_loggers': False, # 不用管
'formatters': { # 绑定输出格式
'standard': {
'format': standard_format # 绑定复杂的输出格式
},
'simple': {
'format': simple_format # 绑定简单的输出格式
},
},
'filters': {}, # 过滤日志 不用管
'handlers': { # 配置输出日志位置
'console': { # 打印到终端的日志
'level': 'DEBUG', # 定义日志可以输出的等级
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple' # 绑定的输出格式
},
'default': { # 打印到文件的日志
'level': 'DEBUG', # 定义日志可以输出的等级
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard', # 绑定的输出格式
'filename': logfile_path, # 输出的路径
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5, # 日志个数,5个
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
# 当键不存在的情况下(也就是key设为空字符串),默认都会使用该k:v配置
# loggers配置中使用空字符串作为字典的键,兼容性最好
'': { # 可以当作是日志输出的分类信息
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # 定义日志可以输出的等级
'propagate': True, # 向上(更高level的logger)传递
},
},
}
输出日志
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# 自定义分类信息会传给日志字典中'logger'中的空字符串
logger1 = logging.getLogger('自定义分类信息')
# 输出到日志的信息
logger1.debug('这是一段debug日志')
Queue模块
Queue模块可以实现队列的功能,先进先出。
实操:
from multiprocessing import Queue # 导入
q = Queue(3) # 自定义队列的长度
# 朝队列中存放数据
q.put(111)
q.put(222)
# 用于判断队列是否满了
print(q.full()) # 输出:False
q.put(333)
print(q.full()) # 输出:True
"""如果队列满了继续存放数据会原地阻塞等待队列中出现空位"""
print(q.get()) # 输出:111
print(q.get()) # 输出:222
# 判断队列是否空了
print(q.empty()) # 输出:False
print(q.get()) # 输出:333
print(q.empty()) # 输出:True
"""如果队列空继续取数据会原地阻塞等待队列中出现数据"""
print(q.get_nowait()) # 功能与get一致,但队列中如果没有值,直接报错
q.put_nowait(123) # 功能与put一致,但队列中如果没有空位,直接报错
总结:
- get():取值。
- get_nowait():取值,但如果没有值就会报错。
- put():存值。
- put_nowait():存值,但如果队列满了就会报错。
- empty():判断队列是否为空。
- full():判断队列是否满了。


