文件操作
文件操作
文件操作简介
文件
文件是操作系统暴露给用户可以直接操作硬盘的快捷方式。
用代码进行文件操作的流程
用代码进行文件操作有四个步骤:
- 打开文件或是创建文件
- 编辑文件内容
- 保存文件内容
- 关闭文件
基本语法结构
# 用python操作文件有2中语法
# 第一种(不推荐)
f1 = open(文件路径,模式,编码类型)
f1 = close()
# 第二种(推荐),f是变量名
with open(文件路径,模式,编码类型) as f:
pass
"""
使用第一种是需要手动写关闭文件的代码
而第二种方法会在运行完子代码后自动关闭文件
"""
补充
在填写路径的时候我们会用到反斜杠符号,为了防止转义,我们会在路径前面加上一个英文字母r
文件的内置方法
数据类型有它的内置方法,文件当然也有。
read() # 一次性读取文件的全部内容 ps:文件过大易内存溢出
readline() # 一次只读一行内容
readlines() # 将文件一行行的内容存储到列表中
readable() # 判断文件是否可读
write() # 将内容写到文件中
writelines() # 将列表中的多个元素写到文件中
writable() # 判断文件是否可写
flush() # 将文件保存一下
补充:文件还支持for循环,可以一行行读取内容,内存中同一时刻只会有一行内容,有效防止内存溢出。
文件的读写模式
python对于文本的操作模式有三种:只读模式(r)、只写模式(w)、只追加模式(a)。
- 只读模式(r模式)
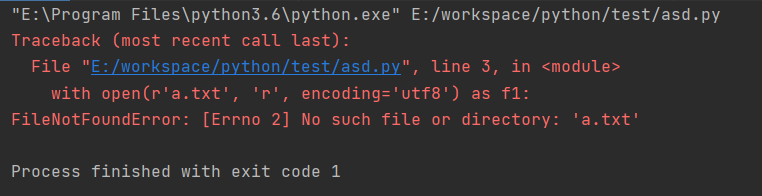
# 路径不存在时,会直接报错
with open(r'a.txt', 'r', encoding='utf8') as f1:
pass
# 路径存在时,正常打开文件并等待内容读取
with open(r'a.txt', 'r', encoding='utf8') as f1:
pass
# 注意:r模式只能读取,不能写入,不然会报错
- 只写模式(w模式)
# 路径不存在时,会自动创建文件
with open(r'a.txt', 'w', encoding='utf8') as f1:
pass
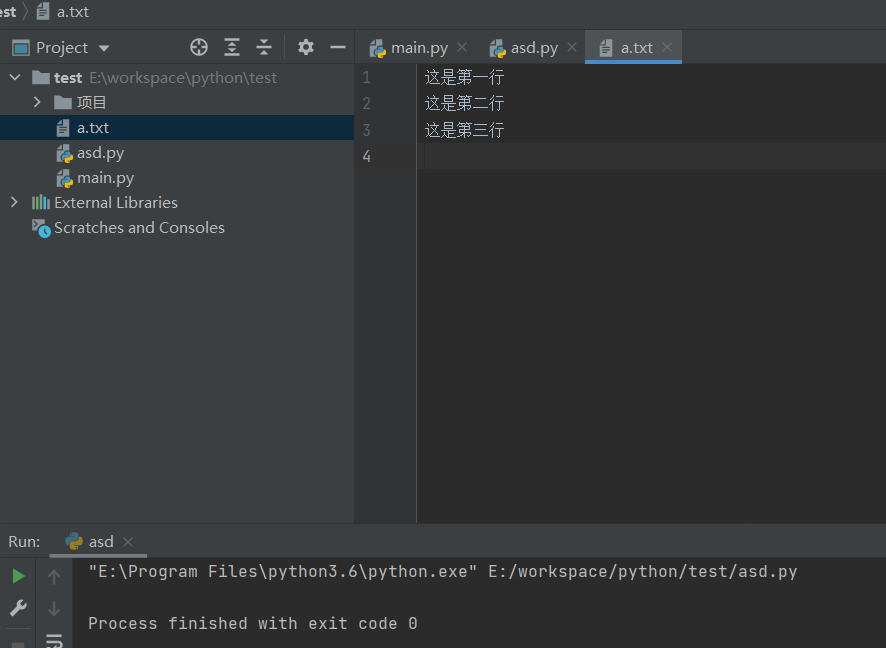
# 路径存在时,会先清空文件内容,之后在写入数据
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write('这是第一行\n')
f1.write('这是第二行\n')
f1.write('这是第三行\n')
- 只追加模式(a模式)
# 只追加模式和只写模式基本一致
# 唯一的区别就是文件存在时它不会清空数据在添加内容,而是会在内容末尾添加内容
with open(r'a.txt', 'a', encoding='utf8') as f1:
f1.write('这是追加内容')
文件的操作模式
文件的操作模式有两种t模式和b模式。
-
t模式是默认的模式,在读写模式中,它的t被省略了,完整的写的话应该是'rt'、'wt'、'at'。
注意事项:
- 只能操作文本文件
- 必须指定encoding参数
- 该模式读写都是以字符串为最小单位
-
b模式也称二进制模式,是可以操作任意类型的文件的。
注意事项:
- 不需要指定encoding参数
- 可以操作任意类型的文件
- 该模式读写都是以bytes类型为最小单位
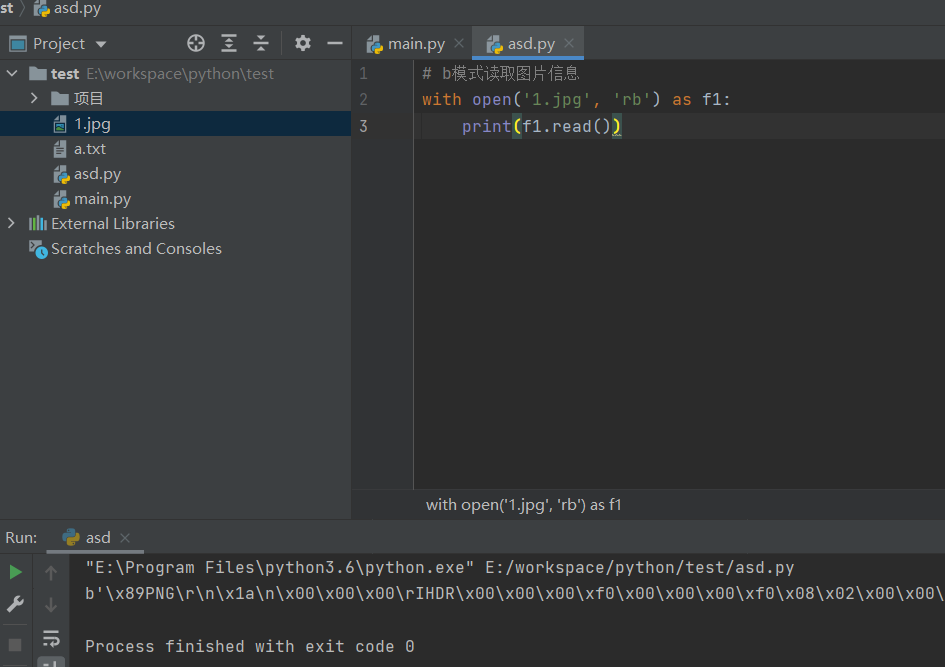
# b模式读取图片信息
with open('1.jpg', 'rb') as f1:
print(f1.read())
文件内光标的移动(了解即可)
前言
在文件的内置方法中,read()方法是可以有参数的,而且在文本模式(t模式)与二进制模式(b模式)中表示不同的含义。

# 在文本模式,也就是t模式下,括号内的参数表示的是读取字符的个数
# a.txt里面的内容:我很hangsome
with open(r'a.txt', 'r', encoding='utf8') as ft:
print(ft.read(1)) # 此时文件光标移到了第一个字符后:我'很nb
# 输出:我
print(ft.read(3)) # 从光标处开始读取,也就是第二个字符开始
# 输出:很ha
# 在二进制模式,也就是b模式下,括号内的参数表示的是读取的字节数
# a.txt里面的内容:我很handsome
with open(r'a.txt', 'rb') as fb:
# b模式读取内容需要解码,不然输出的bytes类型我们读不懂
print(fb.read(3).decode('utf8')) # 此时文件光标移到了第三个字节后
# 输出:我
print(fb.read(6).decode('utf8')) # 从第四个字节开始读取
# 输出:很han
"""在utf8中一个中文使用3字节存储,一个英文字符用1字节存储"""
控制光标移动seek()方法
seek()方法可以控制光标的移动,seek()方法有两个参数:offset和whence。
-
offset参数,代表着需要移动的字节数
-
whence参数,代表着光标起始位置,有三个选择参数:0、1、2,不写默认为0
0:从文件的开头开始,能在文本模式和二进制模式中使用
1:从文件的光标当前位置开始,只能在二进制模式中使用
2:从文件的末尾开始,只能在二进制模式中使用
实战:
"""a.txt中的内容为:我很hangsome"""
# 0模式
with open(r'a.txt', 'r', encoding='utf8') as f:
f.seek(6, 0) # 把光标向后移到离开头6个字节的位置
print(f.read())
"""
输出:
hangsome
"""
# 1模式
with open(r'a.txt', 'rb') as f:
print(f.read(3).decode('utf8')) # 光标此时到了第三个字节后,也就是“我”的后面
f.seek(7, 1) # 把光标向后移到离当前位置7个字节的位置
print(f.read().decode('utf8'))
"""
输出:
我
some
"""
# 2模式
with open(r'a.txt', 'rb') as f:
f.seek(-8, 2) # 把光标向前移到离末尾8个字节的位置
print(f.read().decode('utf8'))
"""
输出:
hangsome
"""
文件的修改
文件本质是不可以修改的,我们所看到的新内容的出现实际上是新内容将旧内容覆盖得到的。
# 文件a.txt.的内容为:
我叫张三 今年要干一票大的
# 修改文件
with open('a.txt',mode='r+',encoding='utf-8') as f:
f.seek(12)
f.write('(法外狂徒)')
# 修改后的内容
我叫张三(法外狂徒)一票大的
"""只会将后面的内容覆盖,不会添加"""
那么我应该如何修改内容的同时不会把后面的内容覆盖呢?
比如我想要将“我叫张三,今年要干一票大的”修改为“我叫张三(法外狂徒),今年要干一票大的”,下面提供了两种方法。

方法一:将文件内容全部读取出来,再用replace()方法将要修改的内容替换
# a.txt的内容为
我叫张三,今年要干一票大的
# 将内容全部读取出来
with open('a.txt',mode='r',encoding='utf-8') as f:
data=f.read()
# 将内容替换掉后写回到a.txt中
with open('a.txt',mode='w',encoding='utf-8') as f:
f.write(data.replace('张三','张三(法外狂徒)'))
"""
优点:在文件修改过程中同一份数据只有一份
缺点:占用过多的内存
"""
方法二:创建一个临时的文件,将原文件内容一行行写入到临时文件中,最后将原文件删除,把临时文件名改为原文件
# a.txt的内容为
我叫张三,今年要干一票大的
import os # 导入模块,用于操作文件
with open('a.txt', 'r', encoding='utf-8') as read_f, \
open('.a.txt.swap', 'w', encoding='utf-8') as wrife_f:
# 遍历原文件的每一行,并把想要修改的给替换掉
for line in read_f:
wrife_f.write(line.replace('张三', '张三(法外狂徒)'))
# 删除原文件
os.remove('a.txt')
# 重命名临时文件
os.rename('.a.txt.swap', 'a.txt')
"""
优点:内存不会占用过多
缺点:在文件修改过程中同一份数据有两份
"""
