

一、线性回归
损失函数 https://blog.csdn.net/alw_123/article/details/82193535
正规方程解, https://blog.csdn.net/alw_123/article/details/82825785#comments
最小二乘法及算法代码 https://blog.csdn.net/qq_32864683/article/details/80368135
梯度下降讲解 https://www.cnblogs.com/wallacup/p/6017378.html
拟然函数 https://www.cnblogs.com/softlin/p/6219372.html?utm_source=itdadao&utm_medium=referral
逻辑回归(二分类算法):https://www.sohu.com/a/236530043_466874
softmax 回归(多分类算法) https://zhuanlan.zhihu.com/p/62381502
二、KNN,k近邻算法。用于分类,也可以用于回归
https://baike.baidu.com/item/%E9%82%BB%E8%BF%91%E7%AE%97%E6%B3%95/1151153?fr=aladdin
https://blog.csdn.net/pengjunlee/article/details/82713047
https://blog.csdn.net/Mr_Lowbee/article/details/86557790
kd-tree 查找最近邻 https://baike.baidu.com/item/kd-tree/2302515?fr=aladdin
三、决策树
https://www.cnblogs.com/xiemaycherry/p/10475067.html
决策树基本概念,如何划分决策树,根据属性“纯度”来分割数据。纯度主要通过信息熵,gini系数,错误率来判断。 信息增益
当熵或者基尼值过小时,表示数据的纯度比较大。
选择信息增益最大的作为划分属性。
决策树三个主要算法:
ID3算法: 信息增益最大化
C4.5: 信息增益率
CART:基尼(Gini)系数.
数据特征较多,需要降维,用到算法
分类回归树:
分类回归树算法---CAR:T https://cloud.tencent.com/developer/article/1080843
分类回归树的缺陷:
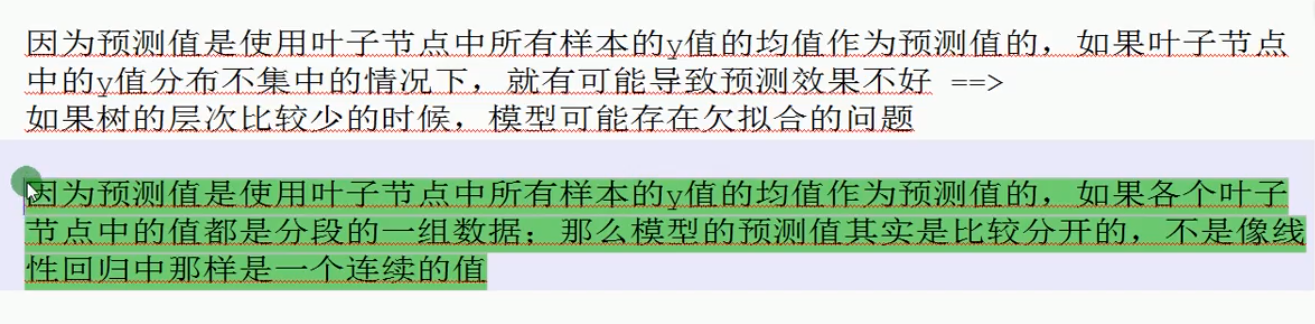
决策树的剪枝:
前置剪枝,后置剪枝 https://blog.csdn.net/am290333566/article/details/81187562
BGD SGD 梯度下降算法
批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解 https://www.cnblogs.com/lliuye/p/9451903.html
gbdt全称梯度下降树 https://www.cnblogs.com/bnuvincent/p/9693190.html
四,集成学习
Bagging 有放回抽样,分类器融合时,采用多数投票或者均值等。
随机森林RF 在Bagging策略的基础上进行修改后的一种算法。 https://blog.csdn.net/qq_34106574/article/details/82016442
五、聚类算法
五种主要聚类算法 https://blog.csdn.net/u011511601/article/details/81951939
K-Means聚类(初始簇心敏感),二分 K-Means算法(弱化初值敏感问题),K-Means++算法(对中心点选择不同) https://blog.csdn.net/promisejia/article/details/88322330
Canopy聚类算法 https://blog.csdn.net/u011514201/article/details/53510069/
Mini Batch K-Means 算法
KNN分类算法和聚类算法的区别 :https://blog.csdn.net/LLDBSD/article/details/85219490
层次聚类算法(凝聚的层次聚类AGNES算法,分裂的层次聚类DIANA算法) https://blog.csdn.net/qq_40859560/article/details/82797401
BIRCH聚类算法原理 https://www.cnblogs.com/pinard/p/6179132.html
密度聚类算法:只要样本点的密度大于某个阈值,则将该样本添加到最近的簇中。这类算法可以克服基于距离的算法只能发现凸聚类的缺点,可以发现任意形状的聚类,而且对噪声数据不敏感。
DBSCAN; https://blog.csdn.net/denghecsdn/article/details/82793940
密度最大值算法MDCA:https://blog.csdn.net/xueyingxue001/article/details/51966945/
均值偏移聚类算法; https://blog.csdn.net/u013761036/article/details/96140356
DBSCAN聚类算法;
使用高斯混合模型(GMM)的期望最大化(EM)聚类;
六、支持向量机SVM
一种二分类的算法
https://www.jiqizhixin.com/articles/2018-10-17-20
SMO,
核函数:对不可以线性可分的,可以通过增加维度来找出超平面。为了解决维度过大的问题,引用核函数
SVM可以用于图像识别,文字识别等
七、多标签多分类算法
多标签分类(multi-label classification)综述 https://www.cnblogs.com/cxf-zzj/p/10049613.html
https://www.cnblogs.com/Allen-rg/p/9492303.html
八、EM算法
机器学习算法总结(六)——EM算法与高斯混合模型 https://www.cnblogs.com/jiangxinyang/p/9278608.html
http://blog.sciencenet.cn/blog-2970729-1191928.html
九、隐马尔可夫算法
隐马尔可夫链
https://www.cnblogs.com/bigmonkey/p/7230668.html
https://www.cnblogs.com/vpegasus/p/hmm.html
https://blog.csdn.net/hudashi/article/details/87867916
十、主题模型
主题模型是用来在大量文档中发现潜在主题的一种统计模型
https://blog.csdn.net/liuy9803/article/details/81029355
https://blog.csdn.net/jiayalu/article/details/100533184
参考人工智能(目录)
