for word in sep:
str=str.replace(word,"")
print(str)
#排除无意义的词
li=str.split()
strset=set(li)
exclude={'in','you','i','go'}
strset=strset-exclude
#单词字数
dict={}
for word in strset:
dict[word]=li.count(word)
print(len(dict),dict)
wclist=list(dict.items())
print(wclist)
#按词频排序
wclist.sort(key=lambda x:x[1],reverse=True)
print(wclist)
#输出pop(20)
for you in range(20):
print(wclist[you])

import jieba
import jieba.posseg as psg
#通过文本处理文件
with open("xs.txt", 'r') as fo:
str=fo.read()
fo.close()
#汉字文本的预处理
for ch in str:
if ch.isalpha() is False:
str = str.replace(ch, "")
# 分词并转成一个列表
strList = [x.word for x in psg.cut(str) if x.flag.startswith('n')]
# 词频统计,用字典保存,排序
mySet = set(strList)
keyList = []
valueList = []
for word in mySet:
keyList.append(word)
valueList.append(strList.count(word))
wordCount = dict(zip(keyList, valueList))
# 字典排序函数(并取top20):
def sortDict(myDict):
tempList = list()
for i in myDict.items():
tempList.append(i)
tempList.sort(key=lambda x: x[1], reverse=True)
myDict = dict(tempList[0:21])
return myDict
wordCount = sortDict(wordCount)
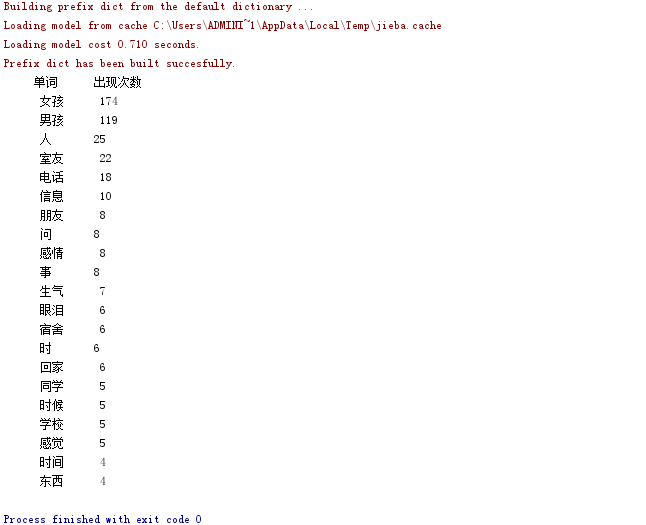
# 输出
print(" 单词 出现次数".center(13))
for word in wordCount.keys():
print(word.center(13), wordCount[word])