
sentinel--核心原理篇
本篇内容主要主要从理论及源码角度介绍sentinel降级和限流的核心原理。如果有对sentinel功能不了解的可以先阅读下《sentinel--初级使用篇》。
1、核心骨架介绍
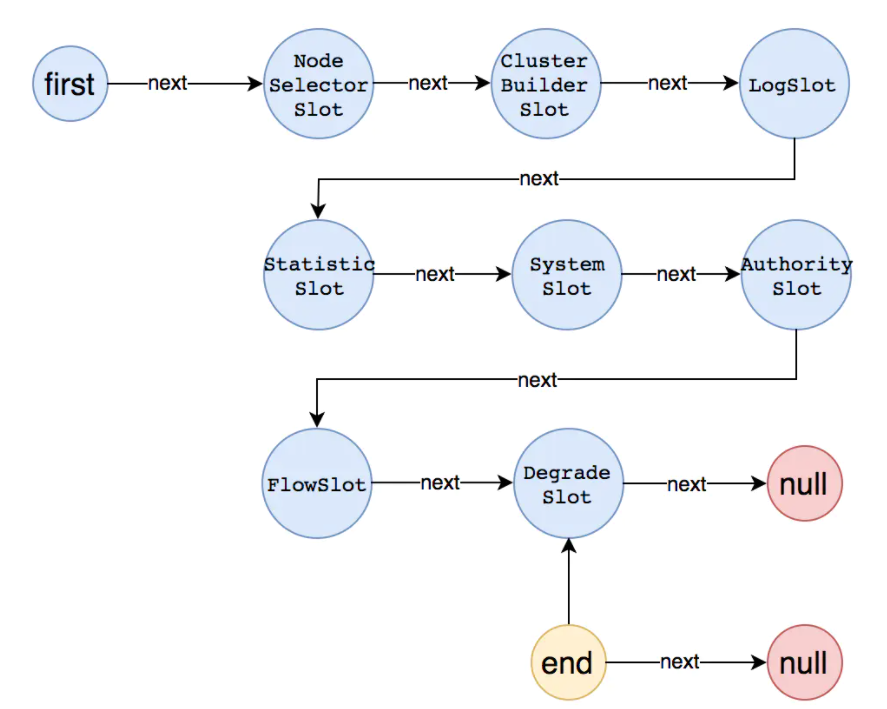
Sentinel 的核心骨架,将不同的 Slot 按照顺序串在一起(责任链模式),从而将不同的功能(限流、降级、系统保护)组合在一起。slot chain 其实可以分为两部分:统计数据构建部分(statistic)和判断部分(rule checking)。核心结构如下图:
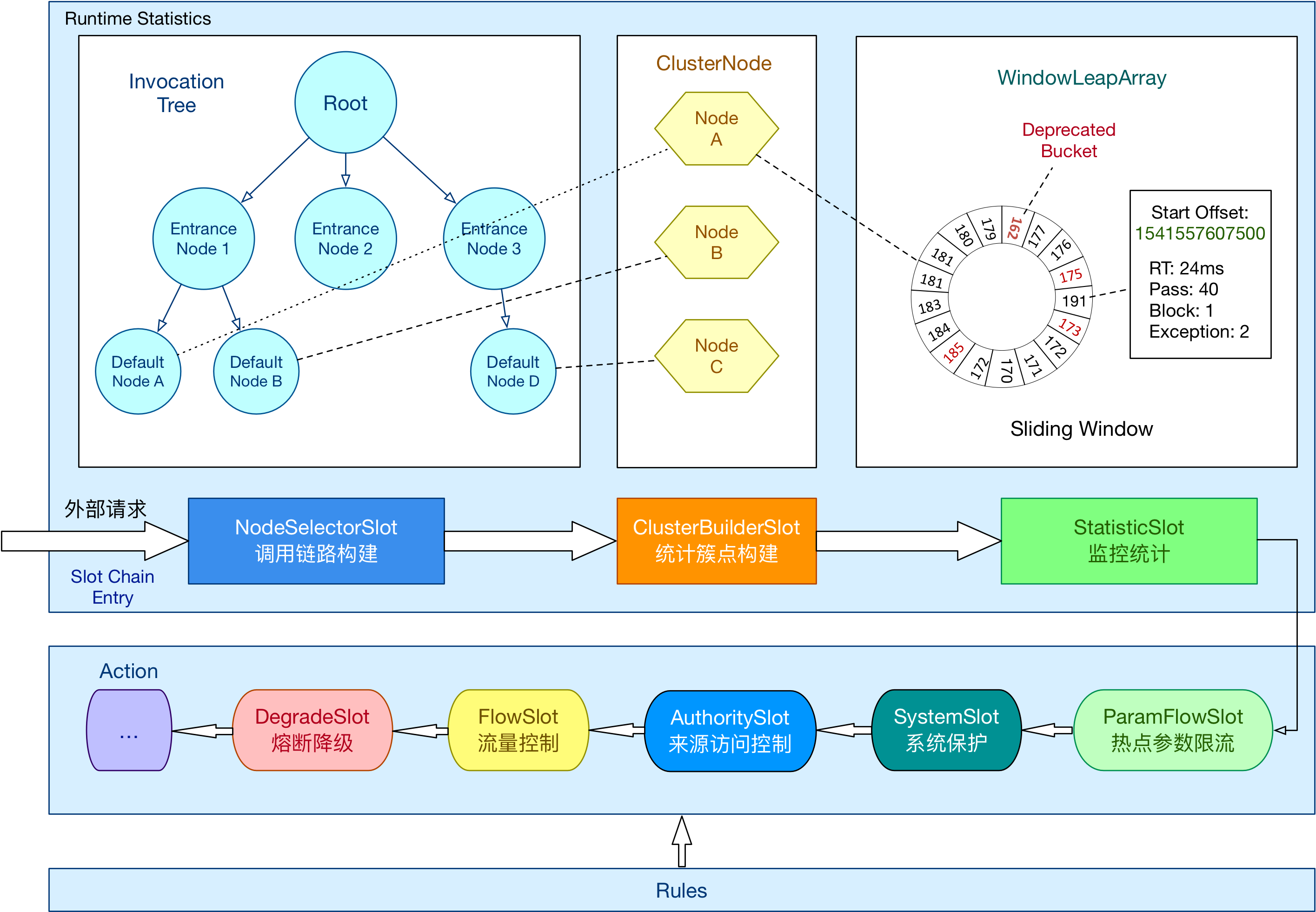
目前是一个资源对应一个Slot 链。
2、核心骨架构架过程
Entry entry = null;
try {
entry = SphU.entry(KEY);
throw new RuntimeException("oops");
}catch (Throwable t) {
bizException.incrementAndGet();
// It\'s required to record exception here manually.
Tracer.traceEntry(t, entry);
} finally {
total.addAndGet(1);
if (entry != null) {
entry.exit();
}
}先贴一段sentinel的基本使用用法,然后一路往下跟到下图:
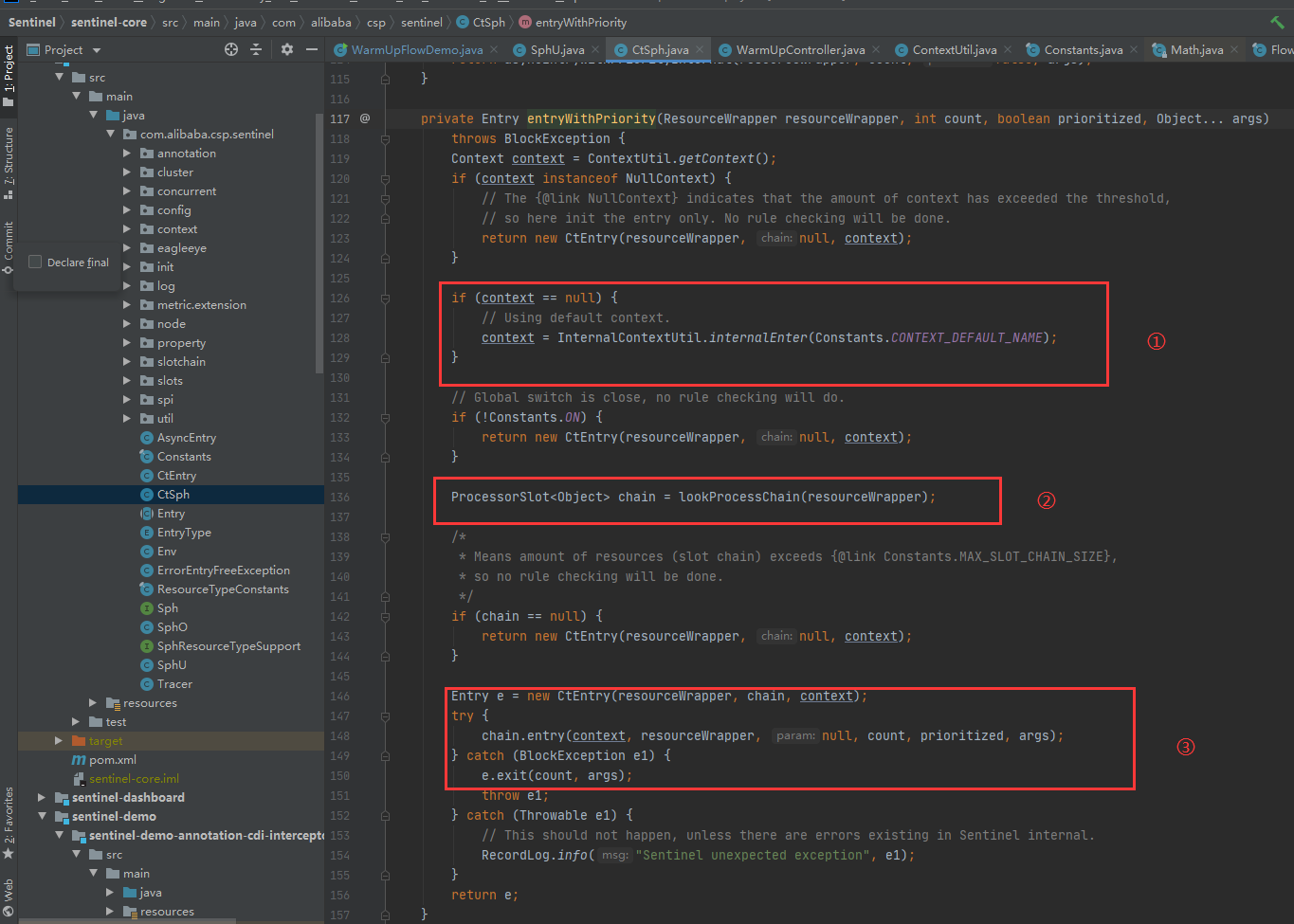
①段代码会生成下面这样一颗树
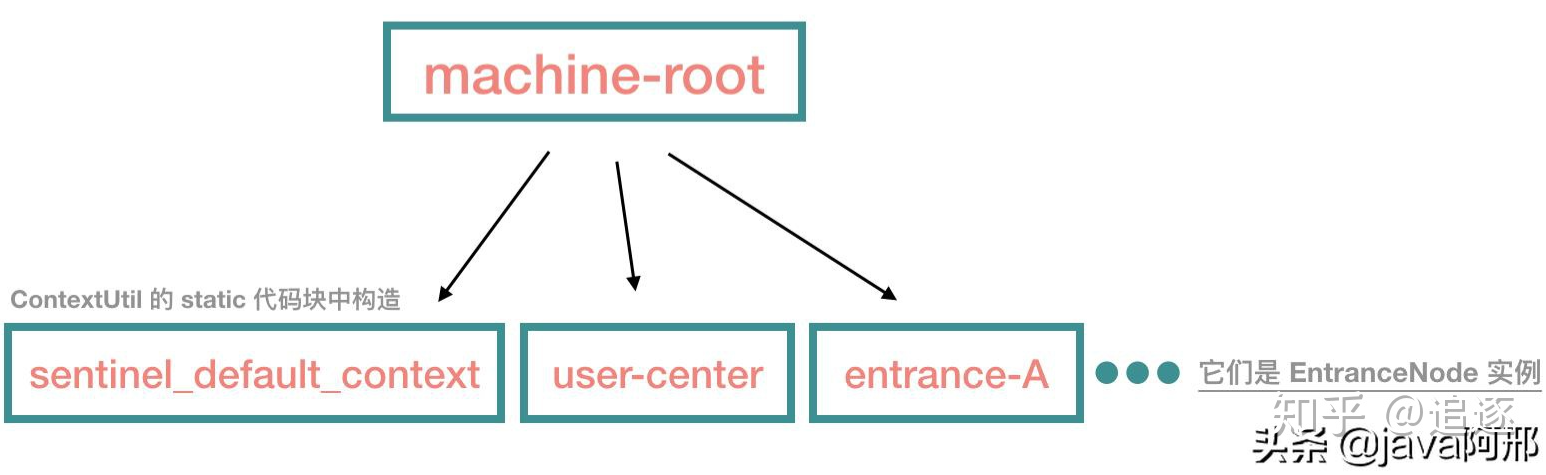
这里的源码非常简单,如果我们从来不显式调用 ContextUtil#enter 方法的话,那 root 就只有一个 default 子节点。context 很好理解,它代表线程执行的上下文,在各种开源框架中都有类似的语义,在 Sentinel 中,我们可以看到,对于一个新的 context name,Sentinel 会往树中添加一个 EntranceNode 实例。它的作用是为了区分调用链路,标识调用入口。
②处代码非常关键(lookProcessChain(resourceWrapper) 这个方法),内部实现如下
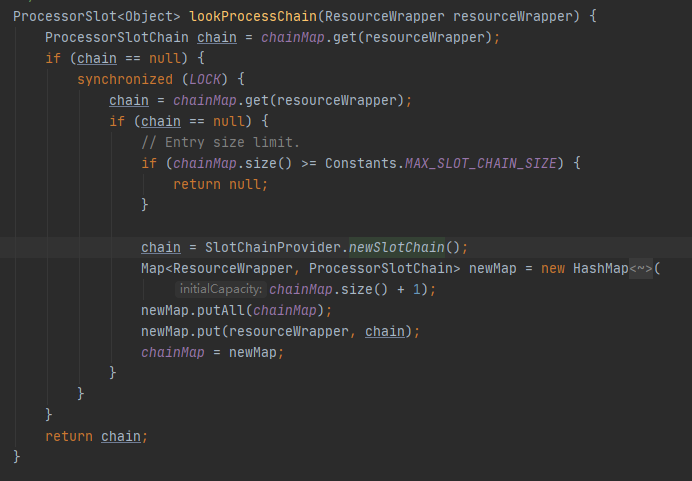
通过SPI机制将META-INFO/servcie下配置好的默认责任链构造这加载出来,然后调用其builder()方法进行构建调用链
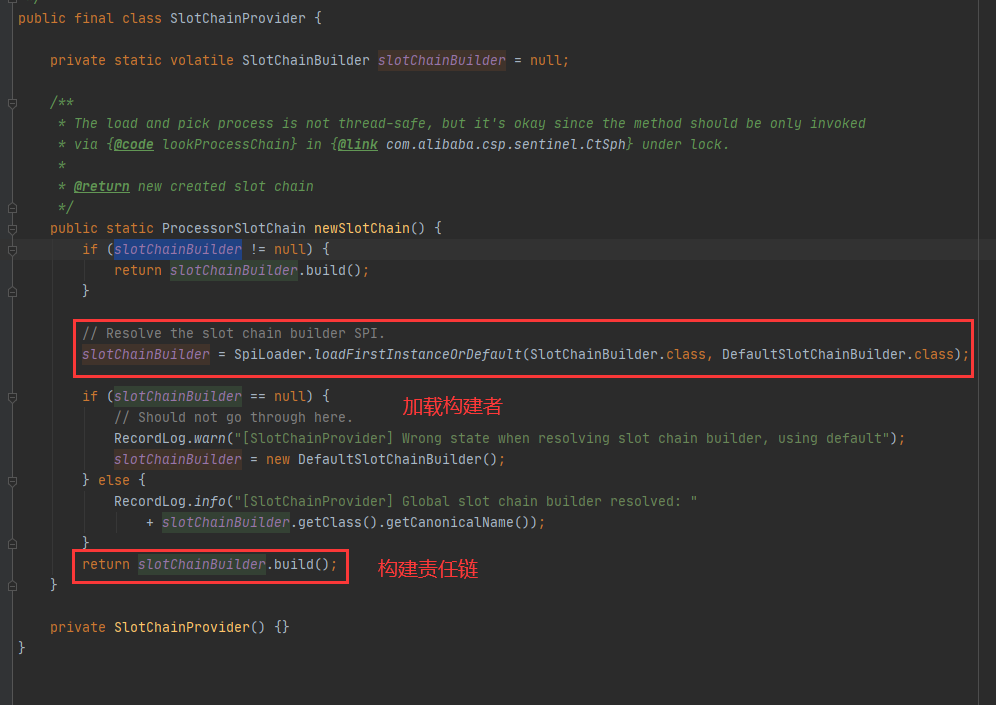
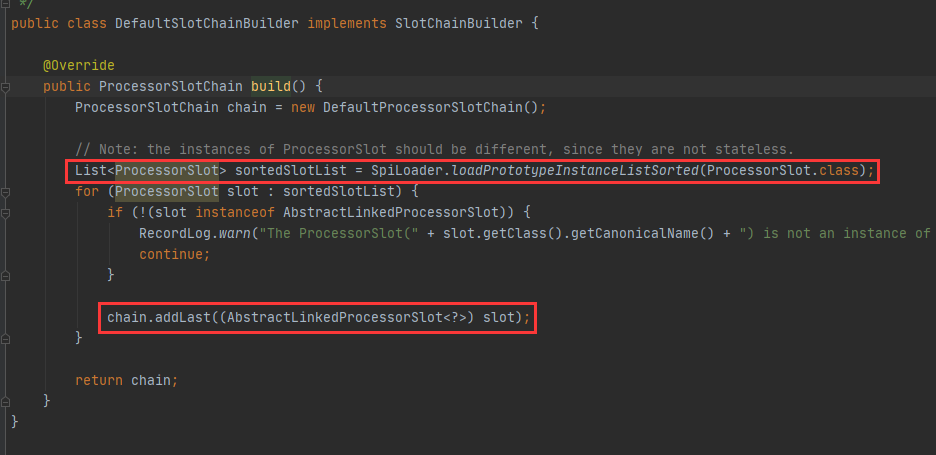
责任链同样是由spi机制加载出来的,上面的加载只会在第一次使用的时候加载,然后缓存到内从后,以后直接取即可。其中责任链的构架过程类似有现行链表的构建过程,具体如下图,这里就不在过多赘述。
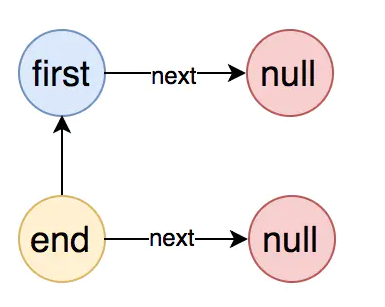
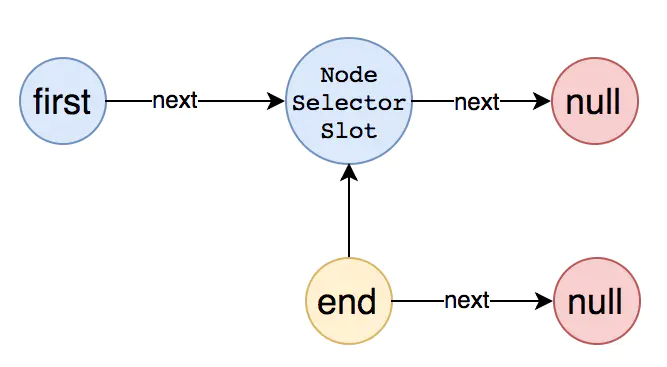
我们前面说了,责任链实例和 resource name 相关,和线程无关,所以当处理同一个 resource 的时候,会进入到同一个 NodeSelectorSlot 实例中。该节点主要处理的是:不同的 context name,同一个 resource name 的情况。如下面的两段代码:
 接下来,我们来到了 ClusterBuilderSlot 这一环,这一环的主要作用是构建 ClusterNode。这里不贴源码,根据上面的树,然后在经过该类的处理以后,我们可以得出下面这棵树:
接下来,我们来到了 ClusterBuilderSlot 这一环,这一环的主要作用是构建 ClusterNode。这里不贴源码,根据上面的树,然后在经过该类的处理以后,我们可以得出下面这棵树:
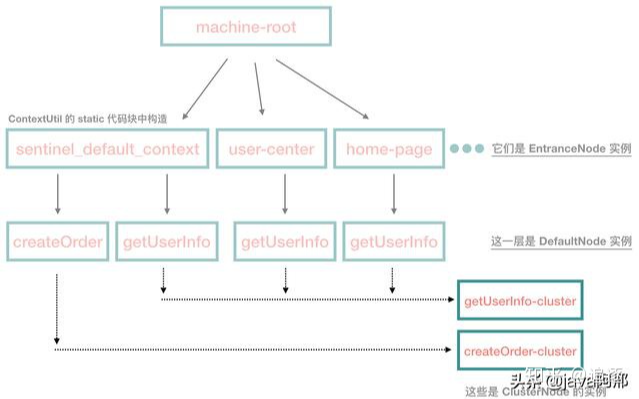
从上图可以看到,对于每一个resource,这里会对应一个 ClusterNode 实例,如果不存在,就创建一个实例。这个 ClusterNode 非常有用,因为我们就是使用它来做数据统计的。比如 getUserInfo 这个接口,由于从不同的 context name 中开启调用链,它有多个 DefaultNode 实例,但是只有一个 ClusterNode,通过这个实例,我们可以知道这个接口现在的 QPS 是多少。另外,这个类还处理了 origin 不是默认值的情况:
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}
我们可以看到,当设置了 origin 的时候,会额外生成一个 StatisticsNode 实例,挂在 ClusterNode 上。我们把前面的代码改改,看红色部分:

我们的 getUserInfo 接收到了来自 application-a 和 application-b 两个应用的请求,那么树会变成下面这样:
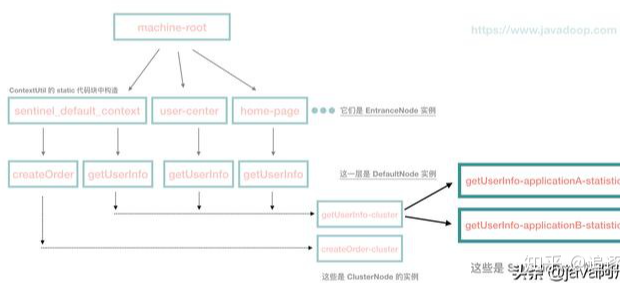
它的作用是用来统计从 application-a 过来的访问 getUserInfo 这个接口的信息。目前这个信息在 dashboard 中是不展示的,毕竟也没什么用。到此为止我们的核心骨架就创建完成了。

