4亿级服务打磨之批量消耗优化
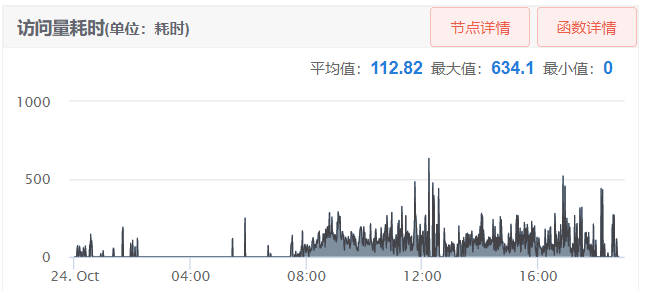
从上图可以看到批量消耗平均耗时在100ms以上,有时候甚至超过500ms,这是在1分钟内的平均耗时,我看过请求日志有些甚至在1000ms以上。
对于一个有着4亿请求量的服务来说,为了保证服务的质量与性能,该接口必定在优化名单之内的。
先从代码看起
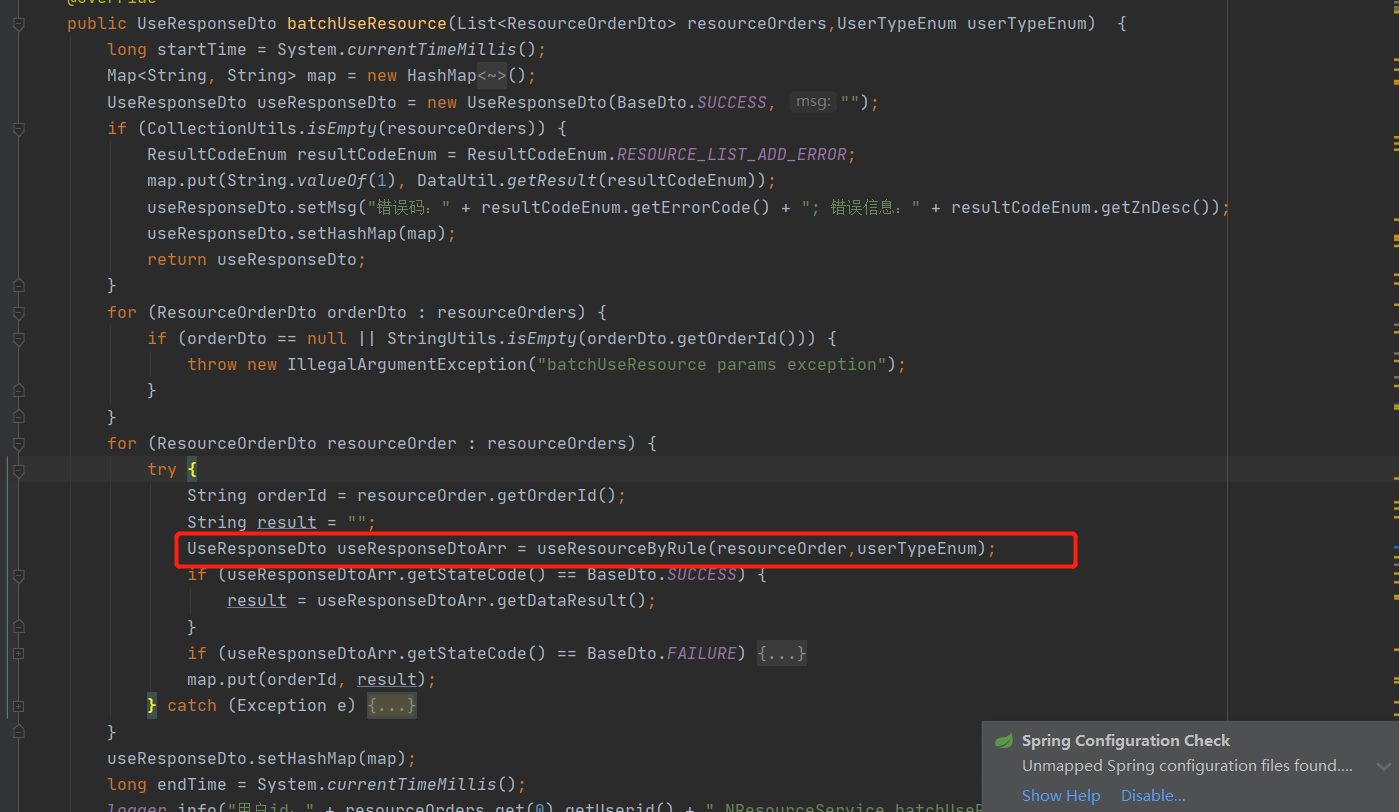
整体代码梳理了一遍,没有什么太大的问题,不存在一些常识性的问题。
红框圈出来的部分是单次消耗的逻辑。需要进行必要的复杂的有DB交互逻辑。然后我观察了一下请求日志,单个消耗时间大概在10ms左右,但是架不住批量消耗的用户多,有的甚至超过100个。所以叠加起来的时间久长了。
问题已经描述清楚了,大家有什么好的思路吗?
此时我先献丑,大家有什么好的思路可以在评论里留言。
我看到此类问题第一反应就是按用户维度用线程池开多线程。因为用户与用户之间是隔离的,开多线程完全不用担心并发问题。
首先看了一下服务器的负载,开多线程没啥问题。
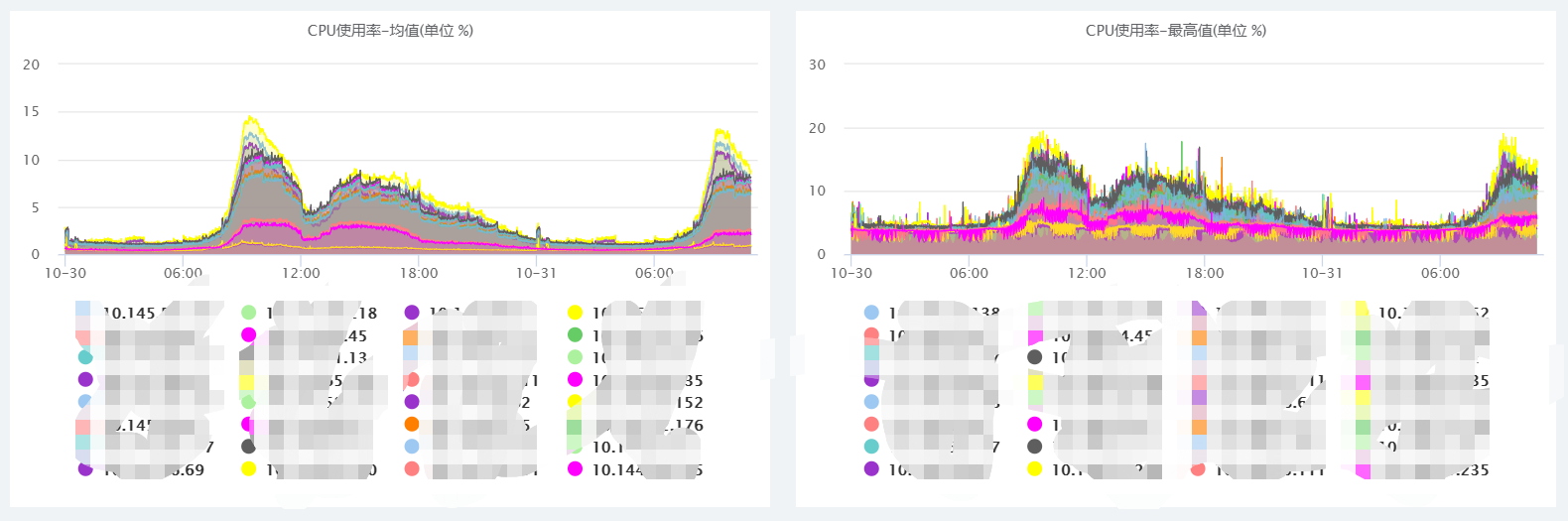
但是,统计了一下请求日志,发现大部分批量消耗只是一个用户。这时候开多线程就没有意义了。
看到请求日志我想到的第一个思路就是和,将一个用户的批量消耗合成一笔消耗不就行了,跟业务一聊发现不行,因为用户关注每笔消耗的流水。
这时我们的终极方案该上场了,就是一个字“合”,简而言之就是多笔消耗业务合并成一笔消耗业务,减少与DB交互的次数。
方案再细化就是:
1、按照资源消耗可拆分的最小粒度进行分组,换句话说就是将将相互不影响的单次消耗拆分到各个组里面去,多线程各个分组批量消耗。目前拆分完了只会有一个分组,开多线程是为了以后扩展需要。
2、具体的批量消耗为,将资源由原来的每笔消耗扣减一次合并成一次汇总扣减,然后在这个过程中内存构建消耗明细,异步批量插入到数据库中去。
到此批量消耗优化结束,理论上和单笔消耗的性能差距不大,甚至性能会更好,因为少了插入消耗明细与DB的交互时间
最后总结一下,其实整体方案不难,也不算复杂,想到了,就可以实现,主要是应用了分布式高并发环境下流量合并的思想,希望这个细想给大家带来更多的启发和灵感

 浙公网安备 33010602011771号
浙公网安备 33010602011771号