
nacos 作为配置中心--选举机制
通过前两篇文章大家也看出nacos从使用角度来说功能强大,我们现有的配置支持较友好,对项目的侵入性较小。这也是我继续研究他的动力,看看到底是否能引入到项目中来。下面三个主题是我接下来研究的主要方向:
- 选举机制
- 数据同步机制
- 性能
nacos作为配置中心的功能是基于raft协议来实现的。为什么要选raft呢?
答案只有两个字:简单。相比paxos协议来说,raft协议要简单的多。我们日常开发做方案时也应如此,简洁有效方案省时省力、易于实现、易于维护。我们逐渐培养自己从复杂的业务中抽象出最简单直接的方案的能力,培养自己化繁为简的能力。
接下来不在废话,直接上raft协议中选举机制部分。
在raft中,任何时候一个服务器可以扮演下面角色之一:
- Leader: 所有请求的处理者,Leader副本接受client的更新请求,本地处理后再同步至多个其他副本;
- Follower: 请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件
- Candidate候选人: 如果Follower副本在一段时间内没有收到Leader副本的心跳,则判断Leader可能已经故障,此时启动选主过程,此时副本会变成Candidate状态,直到选主结束。
- term:这根民主社会的选举很像,每一届新的履职期称之为一届任期
看到了这里,大家觉的raft的选举过程是怎样的呢?此处可以心里默想5分钟,已检验一下自己做方案的能力。然后再看下牛人是怎么实现的,从对比中学习人家的思路。在做事儿之前要现有自己的观念和看法,先思考一番,先思而后行。这样做有两个好处:
1、不会盲从,能去其缺点,学习有点;
2、能锻炼自己的做事儿做方案的能力,能让自己更加独立,不依赖别人,成为团队的核心、顶梁柱。
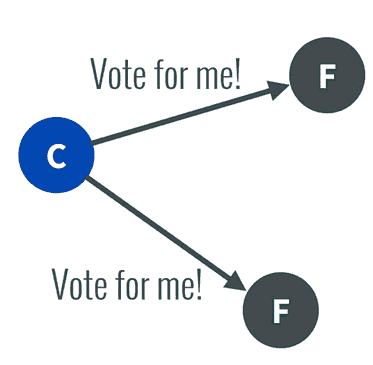
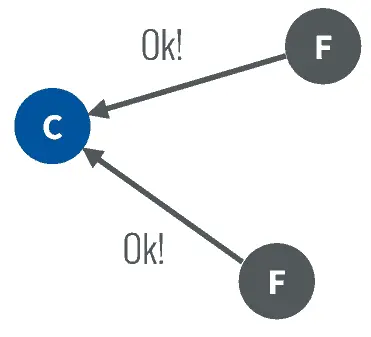
- 系统刚刚启动,所有节点的任期都是0,大家的role都是follower
- 一个启动的节点第一个触发未检测到心跳超时,自增任期为1,并且重新计时(投票开始时间),给自己投一票,然后向所有的其它节点发起投票
- 其它节点当前的任期都为0,且日志也没空,肯定会投票给它,而且这些节点因为收到了candidate的投票选举,清零自己的心跳空白等待时间,未超时前不会发起投票,从而避免多重投票导致无效投票的可能性
- 第一个发起投票的节点收到半数投票,成为leader。
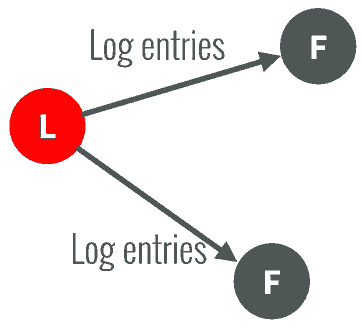
1、每次follower收到leader的一次HeartBeat,都会清零自己的心跳计时器,重新开始计时,如果当前心跳计时器超时了,仍然未收到leader的心跳,就会从follower变成candidate
2、自增当前任期,且开始计时(选举计时),向其它节点发起投票
3、其它节点会比较 任期和日志的序号,至少不能比自己的数据旧才会投票给第一个发起投票的节点
4、超过半数节点投票成功,才会成为leader,否则要等待选举超时,再发起第二轮投票。
动态过程: https://raft.github.io/
个人的疑问:
选取出了主节点之后,从节点如何知道谁是主节点?
任期的时长改怎么设置呢?所有节点都一样?
从源码给大家解释nacos的实现过程。
raft协议的实现都在RaftCore这个类中。
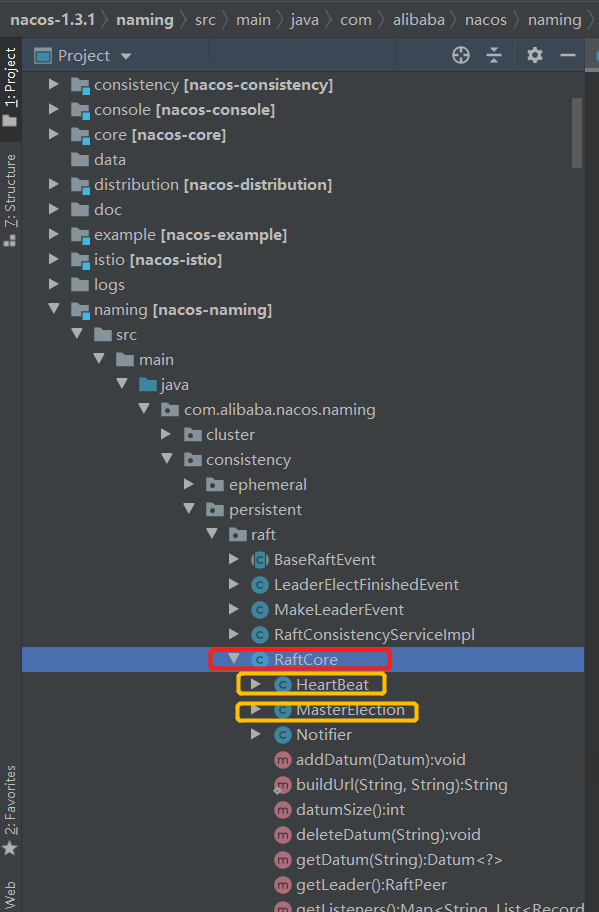
Raft中有两个子类分被负责选举和心跳。
1、选举的入口
public static final long TICK_PERIOD_MS = TimeUnit.MILLISECONDS.toMillis(500L);
public void init() throws Exception {
//省略其他逻辑代码
....
Loggers.RAFT.info("finish to load data from disk, cost: {} ms.", (System.currentTimeMillis() - start));
GlobalExecutor.registerMasterElection(new MasterElection());
GlobalExecutor.registerHeartbeat(new HeartBeat());
Loggers.RAFT.info("timer started: leader timeout ms: {}, heart-beat timeout ms: {}",
GlobalExecutor.LEADER_TIMEOUT_MS, GlobalExecutor.HEARTBEAT_INTERVAL_MS);
}
public static void registerMasterElection(Runnable runnable) {
NAMING_TIMER_EXECUTOR.scheduleAtFixedRate(runnable, 0, TICK_PERIOD_MS, TimeUnit.MILLISECONDS);
}
public static void registerHeartbeat(Runnable runnable) {
NAMING_TIMER_EXECUTOR.scheduleWithFixedDelay(runnable, 0, TICK_PERIOD_MS, TimeUnit.MILLISECONDS);
}可以看出每隔500ms就会触发一次选举任务和心跳任务
2、接下来看一下心跳是如何做的
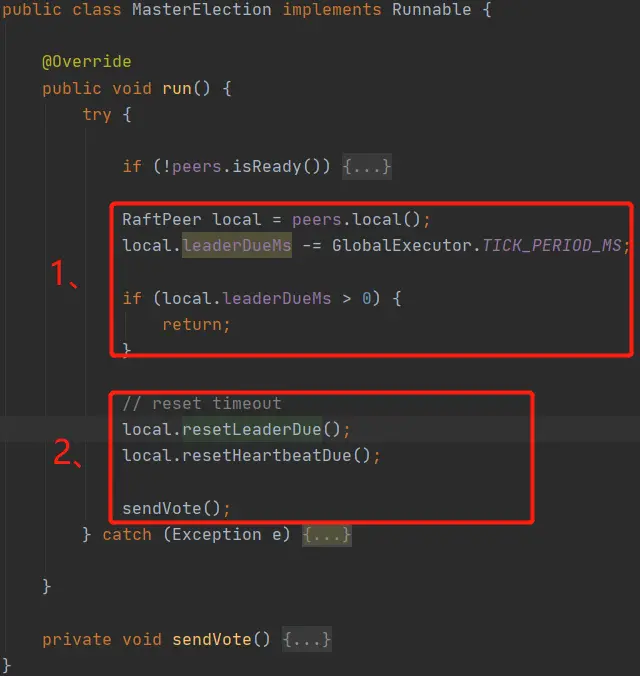
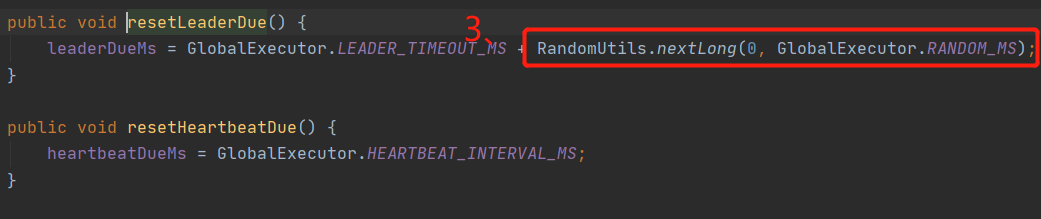
看源码“1、”处可以发现,在leaderDue(leader任期)内是不会进行选举的。只有leaderDue到期之后才会重置leaderDue和heartBeatDue(心跳检测时长),然后发送起投票。这里有个细节可以关注下,在代码“3、”处有一个随机值,大家有没有想过为什么要加入这个随机值?
答:随机值是为了让每个节点的leaderDueMs不同,也就是每个节点的leader任期不一样,从而避免大家同时发起投票,提升选举leader的成功率。换一种说法就是,某个节点leaderDueMs先减为0,先自增term,然后后发起投票,这是该节点由于term+1比其他节点term值大,从而成功成为leader。如果不加随机值,大家同时发起头票,同时term+1 这样在这一轮选举中就不会有leader。
3、选举具体过程
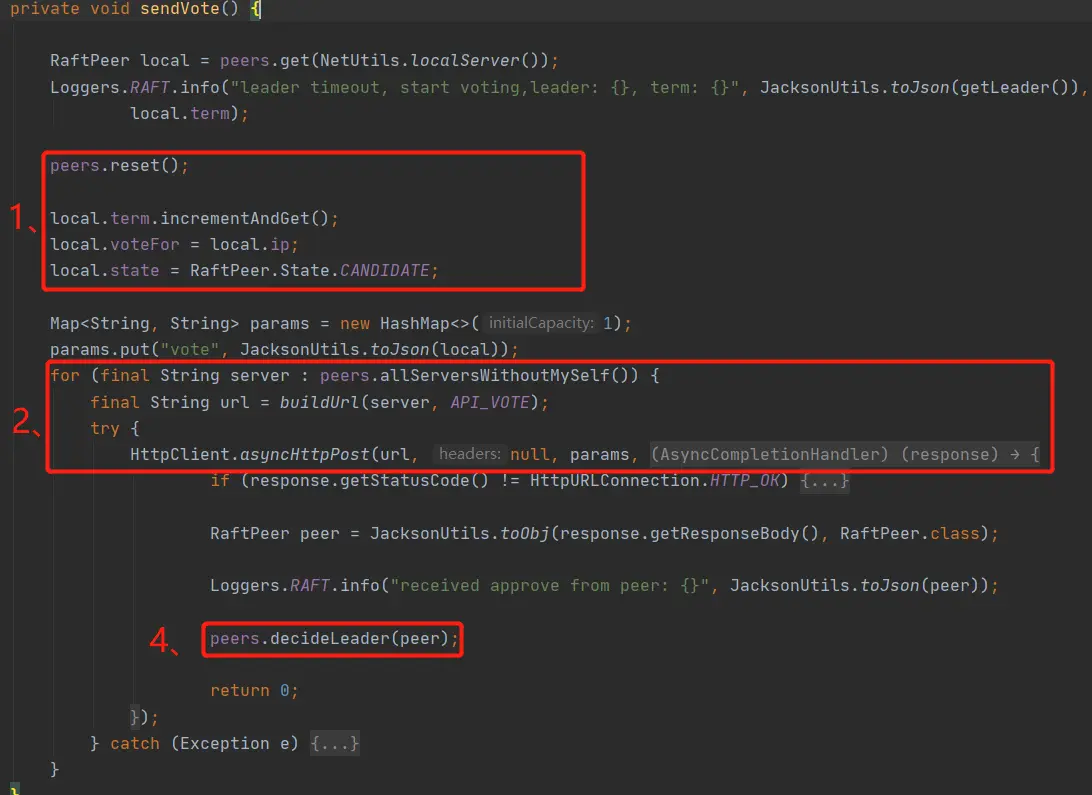
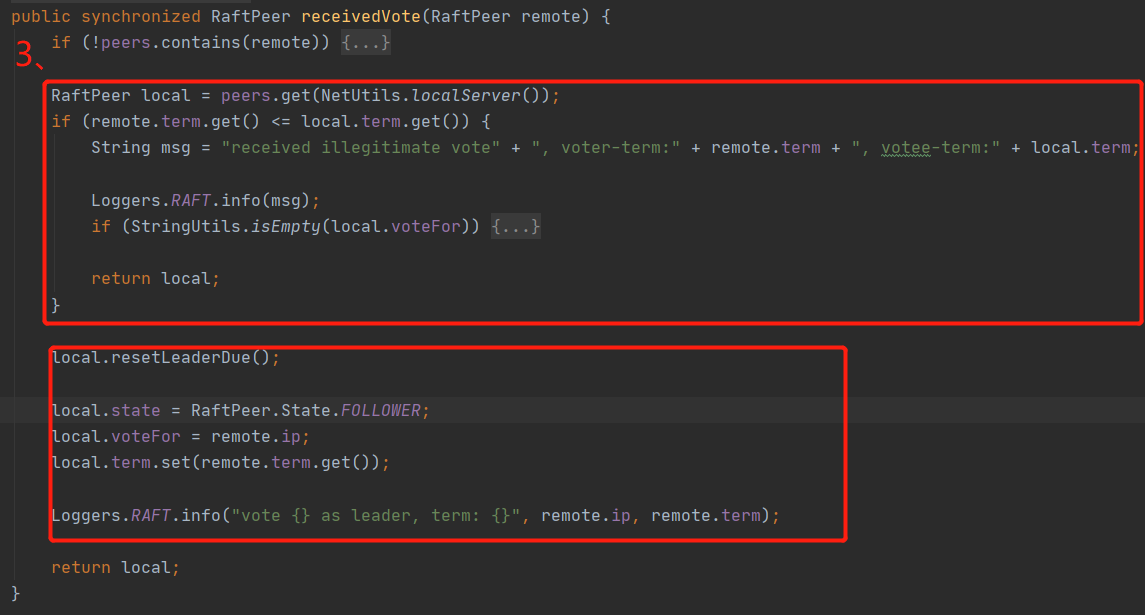
发起头票的过程为头票发起方,向不包含自己的其他节点发起头票请求,其他节点接收到请求后,进行上述代码处“3、”处的处理,看一下term是否比自己的term他,大则投给他,然后然后将自己的term设置为要发起头票请求的term,重置leaderDueMs(为了避免自己再发起一轮头票请求)。最后将头票结果返回给头票发起方。头票发起方接收到头票结果,然后根据结果有半数头票的leader成为真正的leader。选举到此结束。
那么问题来了,其他节点怎么知道这个头票结果呢?如果是你该以何种方式通知其他节点呢?
这时候其实由于其他节点都选某个节点为主,然后自己leaderDueMs重置,不会发起选举了。
4、心跳过程
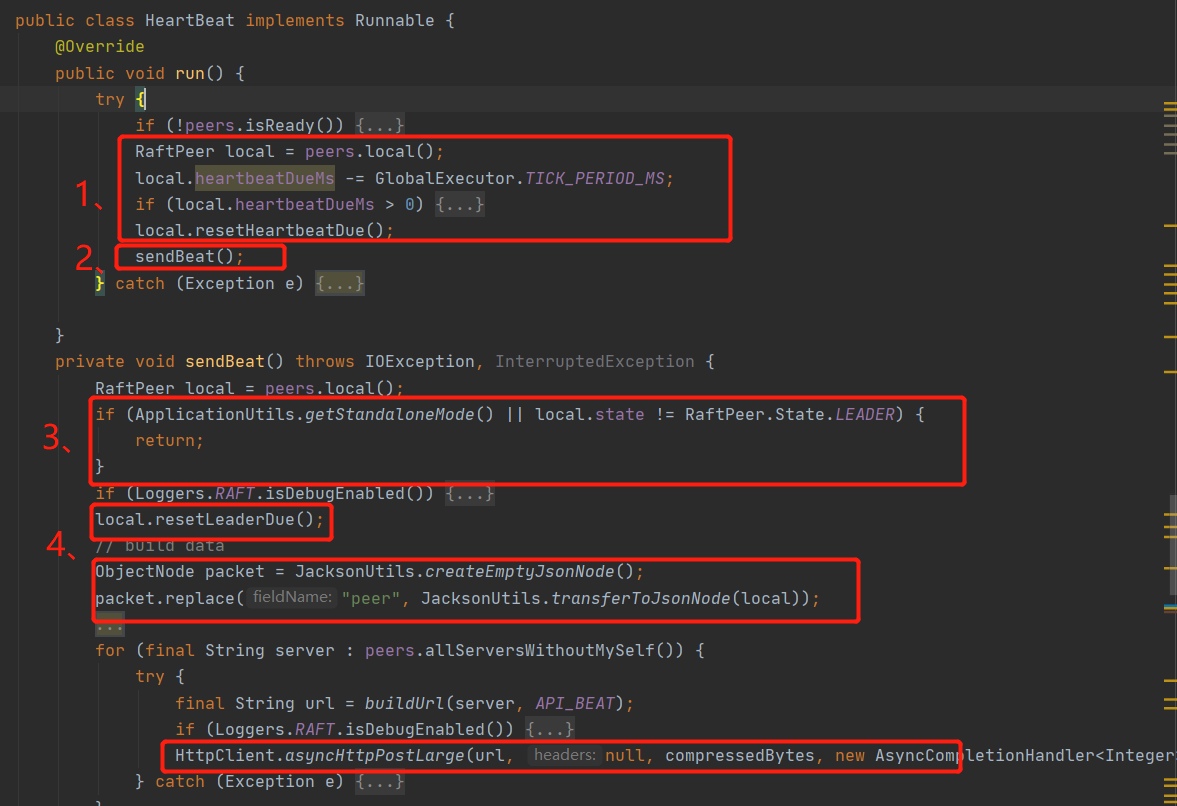
第一步和选举类似,只有heartBeatDueMs到期之后才会发起心跳处理。这里的心跳处理周期远远小于选举的term周期。而且再心跳处理过程中心跳发起方和接收方都会重置选举时间。通过时间的延长来阻止各个节点发起头票请求。
上面代码地四处解决了某一节点成为leader之后,如何将这个消息通知给其他节点,答案就行通过心跳的方式将leader传给其他节点,其他节点接收到心跳请求之后,更新leader。接收心跳请求的代码如下。
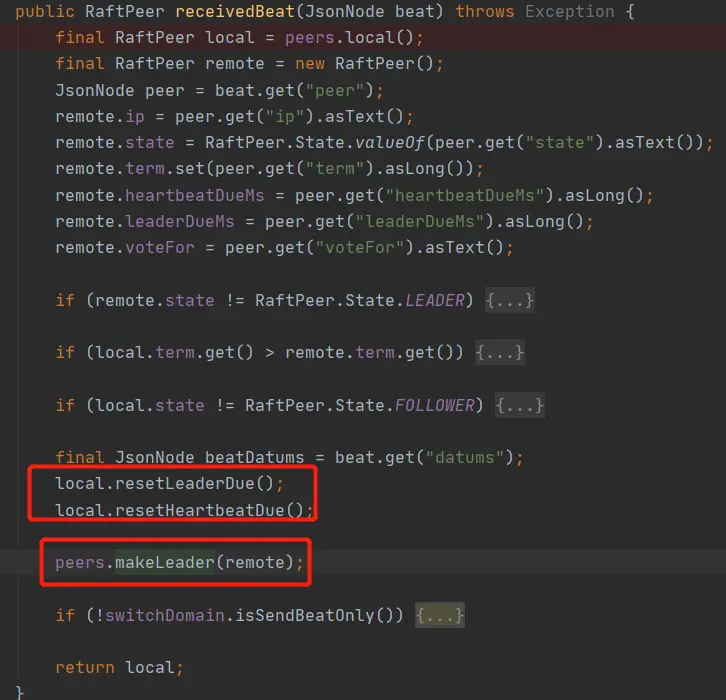
到此选举机制介绍完毕。
此时有我有产生三个新的问题:
1、follower 超时,有问题吗?
2、leader 超时,有哦问题吗?
3、脑裂问题该如何处理?
问题一:
follower超时,自身会重新发起选举,如果与其他节点不通,则会一直处于选举状态,如果超时一段时间后恢复,会通过选举成为新的leader或者(接收心跳消息完成了选举),或者成为原来leader的follower(在发去选举请求之前接收到了心跳消息,成为follower)。这时候会存在两个leader,但是由于旧leader的term较小,发送心跳消息不起效果,最终被新的leader同步为follower。该结论代验证,仅仅是分析结论
又产生新问题,有两个leader会影响配置信息的发布吗?
问题二:
leader超时重新选举,差生新的leader。旧leader如果恢复了,也会通过心跳,被同步为follower。
问题三:
脑裂问题通过问题一和问题二的答案可以看出,通过时间续约和term比较最终旧leader被同步为follower。

