scrapy 入门
为了爬取网站数据而编写的一款应用框架,出名,强大。所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板。(高性能的异步下载,解析,持久化……)
a) 概念:为了爬取网站数据而编写的一款应用框架,出名,强大。所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板。(高性能的异步下载,解析,持久化……)
b) 安装:
在 win 上:
- pip install wheel
- 下载twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
- pip install 下载好的框架.whl
- pip install pywin32
- pip install scrapy
c) 基础使用: 使用流程
1. 创建一个工程:scrapy startproject 工程名称
- 目录结构:

2. 在工程目录下创建一个爬虫文件:
- cd 工程
- scrapy genspider 爬虫文件的名称 起始url
- 对应的文件中编写爬虫程序来完成爬虫的相关操作
3. 配置文件的编写(settings)
- 19行:对请求载体的身份进行伪装
- 22行:不遵从robots协议,实验环境先关闭
4. 执行: scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)
scrapy 命令说明格式
- startproject 创建一个新工程 scrapy startproject <name> [dir]
- genspider 创建一个爬虫 scrapy genspider [options] <name> <domain> #不写爬虫名会默认将域名作为爬虫名
- settings 获得爬虫配置信息 scrapy settings [options]
- crawl 运行一个爬虫 scrapy crawl <spider>
- list 列出工程中所有爬虫 scrapy list
- shell 启动URL调试命令行 scrapy shell [url]
scrapy 框架 (5+2)
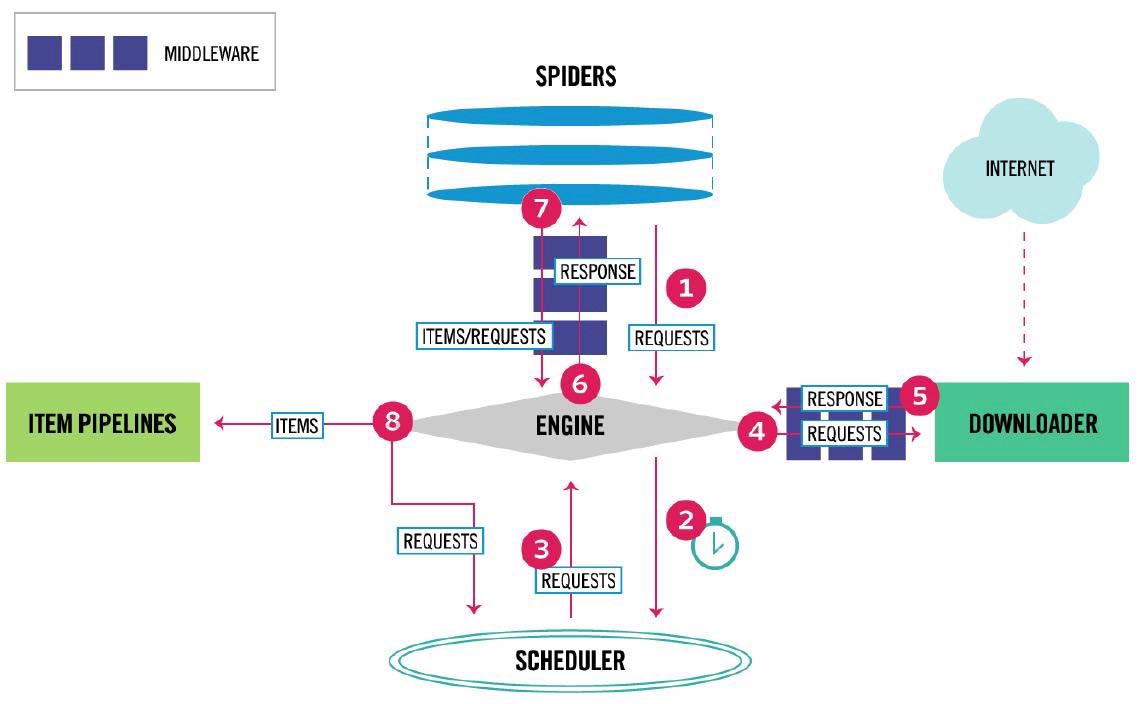
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
数据流的三个路径
| A |
1 Engine从Spider处获得爬取请求(Request)
2 Engine将爬取请求转发给Scheduler,用于调度
|
| B |
3 Engine从Scheduler处获得下一个要爬取的请求
4 Engine将爬取请求通过中间件发送给Downloader
5 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6 Engine将收到的响应通过中间件发送给Spider处理
|
| C |
7 Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8 Engine将爬取项发送给Item Pipeline(框架出口)
9 Engine将爬取请求发送给Scheduler
|
模块功能
| 模块 | 功能 |
| Spider |
(1) 解析Downloader返回的响应(Response)
(2) 产生爬取项(scraped item)
(3) 产生额外的爬取请求(Request)
需要用户编写配置代码
|
| Engine |
(1) 控制所有模块之间的数据流
(2) 根据条件触发事件
Engine控制各模块数据流,不间断从Scheduler处
获得爬取请求,直至请求为空
不需要用户修改
|
| Scheduler |
对所有爬取请求进行调度管理
不需要用户修改
|
| Downloader |
根据请求下载网页
不需要用户修改
|
| Downloader Middleware |
目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
用户可以编写配置代码
|
| Item Pipelines |
(1) 以流水线方式处理Spider产生的爬取项
(2) 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
(3) 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
需要用户编写配置代码
|
| Spider Middleware |
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
用户可以编写配置代码
|
requests与scrapy比较
| requests页面级爬虫 | scrapy 网站级爬虫 |
|
功能库
并发性考虑不足,性能较差
重点在于页面下载
定制灵活
上手十分简单
|
框架
并发性好,性能较高
重点在于爬虫结构
一般定制灵活,深度定制困难
|
| 非常小的需求,requests库
不太小的需求,Scrapy框架
定制程度很高的需求(不考虑规模),自搭框架,requests > Scrapy
|
|
spider 处理

Request
属性或方法.url Request.method 对应的请求方法,.headers 字典类型风格的请求头.body 请求内容主体,字符串类型.meta 用户添加的扩展信息,在Scrapy内部模块间传递信息使用.copy() 复制该请求
Response
.url Response对应的URL地址.status HTTP状态码,默认是200.headers Response对应的头部信息.body Response对应的内容信息,字符串类型.flags 一组标记.request 产生Response类型对应的Request对象.copy() 复制该响应
Scrapy 爬虫提取信息的方法
• Beautiful• lxml• re• Selector• Selector
<HTML>.css( ).extract()
标签名称 标签属性
CSS Selector的基本使用
本文来自博客园,作者:元贞,转载请注明原文链接:https://www.cnblogs.com/yuleicoder/p/9929454.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号