drf3 Serializers 序列化组件
为什么要用序列化组件
做前后端分离的项目,我们前后端交互一般都选择JSON数据格式,JSON是一个轻量级的数据交互格式。
给前端数据的时候都要转成json格式,那就需要对从数据库拿到的数据进行序列化。
django序列化和rest_framework序列化的对比
将后端数据库中的信息用json的格式传给前端
数据准备


DRFDemo/urls.py from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('books/', include("SerDemo.urls")), ] SerDemo/urls.py urlpatterns = [ path('list', BookView.as_view()), path('retrieve/<int:id>', BookEditView.as_view()), ]
from django.db import models # Create your models here. __all__ = ["Book", "Publisher", "Author"] class Book(models.Model): title = models.CharField(max_length=32, verbose_name="图书名称") CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = models.IntegerField(choices=CHOICES, verbose_name="图书的类别") pub_time = models.DateField(verbose_name="图书的出版日期") publisher = models.ForeignKey(to="Publisher", on_delete=None) author = models.ManyToManyField(to="Author") def __str__(self): return self.title class Meta: verbose_name_plural = "01-图书表" db_table = verbose_name_plural class Publisher(models.Model): title = models.CharField(max_length=32, verbose_name="出版社的名称") def __str__(self): return self.title class Meta: verbose_name_plural = "02-出版社表" db_table = verbose_name_plural class Author(models.Model): name = models.CharField(max_length=32, verbose_name="作者的姓名") def __str__(self): return self.name class Meta: verbose_name_plural = "03-作者表" db_table = verbose_name_plural
for table in models.__all__: admin.site.register(getattr(models, table))
需要自己手动,对取出来的数据进行序列化后返回
class BookView(View): # 第一版 用.values JsonResponse实现序列化 def get(self, request): book_list = Book.objects.values("id", "title", "category", "pub_time", "publisher") book_list = list(book_list) ret = [] for book in book_list: # print(book) publisher_id = book["publisher"] publisher_obj = Publisher.objects.filter(id=publisher_id).first() book["publisher"] = { # 将 publisher 对应的出版社,序列化 "id": publisher_id, "title": publisher_obj.title } ret.append(book) # ret = json.dumps(book_list, ensure_ascii=False) # json.dumps 不能处理日期格式数据 # return HttpResponse(ret) # 使用JsonResponse 能帮我们处理 return JsonResponse(ret, safe=False, json_dumps_params={"ensure_ascii": False})
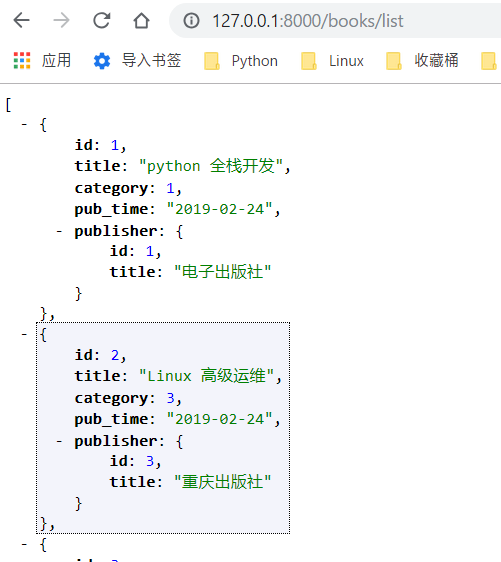
class BookView(View): # 第二版 用django serializers实现序列化 def get(self, request): book_list = Book.objects.all() ret = serializers.serialize("json", book_list, ensure_ascii=False) return HttpResponse(ret)
序列化仍旧处于表层,第二级以下的数据显示为数字

DRF序列化
用DRF的序列化,要遵循框架的一些标准,
-- Django我们CBV继承类是View,现在DRF我们要用APIView
-- Django中返回的时候我们用HTTPResponse,JsonResponse,render ,DRF我们用Response
安装 pip install djangorestframework
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'SerDemo',
'rest_framework',
]
序列化
from rest_framework import serializers class BookSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = serializers.ChoiceField(choices=CHOICES,source="get_category_display") pub_time = serializers.DateField()
from rest_framework.views import APIView from rest_framework.response import Response from .serializers import BookSerializer # 导入序列化类 class BookView(APIView): def get(self, request): book_obj = Book.objects.first() ret = BookSerializer(book_obj) # book_list = Book.objects.all() # 拿到所有的对象 # ret = BookSerializer(book_list, many=True) return Response(ret.data)
ret = BookSerializer(book_list, many=True) 序列化多个对象时,需要设置many=True

含外键数据的序列化
from rest_framework import serializers class PublisherSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) class BookSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = serializers.ChoiceField(choices=CHOICES, source="get_category_display") pub_time = serializers.DateField() publisher = PublisherSerializer() author = AuthorSerializer(many=True)

DRF反序列化
当前端给我们发post的请求的时候~前端给我们传过来的数据~我们要进行一些校验然后保存到数据库 这些校验以及保存工作,DRF的Serializer也给我们提供了一些方法了 首先~我们要写反序列化用的一些字段~有些字段要跟序列化区分开 Serializer提供了.is_valid() 和.save()方法
将前端传过来的数据进行反序列化,然后保存到数据库
read_only=True #序列化
write_only=True #反序列化数据
前端传过来的数据样式
{
"title": "Alex的使用教程",
"w_category": 1,
"pub_time": "2018-10-09",
"publisher_id": 1,
"author_list": [1, 2]
}
接受Post前端传过来的数据,必须在serialise类定义create方法
class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) #不需要校验 title = serializers.CharField(max_length=32, validators=[my_validate]) CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublisherSerializer(read_only=True) publisher_id = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) author_list = serializers.ListField(write_only=True) #反序列化字段 def create(self, validated_data): # 创建数据,接受post 数据 book = Book.objects.create(title=validated_data["title"], category=validated_data["w_category"], pub_time=validated_data["pub_time"], publisher_id=validated_data["publisher_id"]) # 取数据的时候应该为前端传过来的字段数据 book.author.add(*validated_data["author_list"]) #多对多 return book
定义 post 方法接受前端传过来的数据
class BookView(APIView): def get(self, request): # book_obj = Book.objects.first() # ret = BookSerializer(book_obj) book_list = Book.objects.all() ret = BookSerializer(book_list, many=True) return Response(ret.data) def post(self, request): print(request.data) serializer = BookSerializer(data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data) #校验成功,反回 else: return Response(serializer.errors)
post数据

反回的结果

DRF的PUT请求部分验证
单条数据操作
from django.urls import path, include from .views import BookView, BookEditView urlpatterns = [ path('list', BookView.as_view()), path('retrieve/<int:id>', BookEditView.as_view()), ]
BookEditView
class BookEditView(APIView): def get(self, request, id): # 获取单条数据 book_obj = Book.objects.filter(id=id).first() ret = BookSerializer(book_obj) return Response(ret.data) def put(self, request, id): # 部分修改数据 book_obj = Book.objects.filter(id=id).first() serializer = BookSerializer(book_obj, data=request.data, partial=True) # partial=True # 支持部分验证 if serializer.is_valid(): serializer.save() return Response(serializer.data) else: return Response(serializer.errors) def delete(self, request, id): book_obj = Book.objects.filter(id=id).first() book_obj.delete() return Response("")
查看单条数据,获取id为4的数据

修改数据
前端传过来的数据
data = { "title": "Alex的使用教程2" }
对修改的数据进行序列化处理 update 方法
class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) #不需要校验 title = serializers.CharField(max_length=32, validators=[my_validate]) CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublisherSerializer(read_only=True) publisher_id = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) author_list = serializers.ListField(write_only=True) def update(self, instance, validated_data): # 处理 put 更新数据 instance.title = validated_data.get("title", instance.title) instance.category = validated_data.get("category", instance.category) instance.pub_time = validated_data.get("pub_time", instance.pub_time) instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id) if validated_data.get("author_list"): instance.author.set(validated_data["author_list"]) instance.save() return instance

反回的结果

DRF的验证
class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) # 不需要校验 title = serializers.CharField(max_length=32, validators=[my_validate]) CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublisherSerializer(read_only=True) publisher_id = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) author_list = serializers.ListField(write_only=True) def create(self, validated_data): # 创建数据 book = Book.objects.create(title=validated_data["title"], category=validated_data["w_category"], pub_time=validated_data["pub_time"], publisher_id=validated_data["publisher_id"]) book.author.add(*validated_data["author_list"]) # 多对多 return book def update(self, instance, validated_data): # 处理 put 更新数据 instance.title = validated_data.get("title", instance.title) instance.category = validated_data.get("category", instance.category) instance.pub_time = validated_data.get("pub_time", instance.pub_time) instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id) if validated_data.get("author_list"): instance.author.set(validated_data["author_list"]) instance.save() return instance
def validate_title(self, value): # 对传过来的title进行校验 if "python" not in value.lower(): raise serializers.ValidationError("标题必须含有python") return value def validate(self, attrs): # 全局校验 if attrs["w_category"] == 1 and attrs["publisher_id"] == 1: return attrs else: raise serializers.ValidationError("分类以及标题不符合要求")




自定义验证器
当有重叠校验器时自定义的验证器权重更高
def my_validate(value): # 自定义验证器,权重更高,用在需要校验数据的地方 if "敏感信息" in value.lower(): raise serializers.ValidationError("不能含有敏感信息") else: return value
使用
title = serializers.CharField(max_length=32, validators=[my_validate])
all
from rest_framework import serializers from .models import Book # 外键序列化 class PublisherSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) # # # 传过来的书籍对象数据 # book_obj = { # "title": "Alex的使用教程", # "w_category": 1, # "pub_time": "2018-10-09", # "publisher_id": 1, # "author_list": [1, 2] # } # # data = { # "title": "Alex的使用教程2" # } def my_validate(value): # 自定义验证器,权重更高, if "敏感信息" in value.lower(): raise serializers.ValidationError("不能含有敏感信息") else: return value class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) # 不需要校验 title = serializers.CharField(max_length=32, validators=[my_validate]) CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublisherSerializer(read_only=True) publisher_id = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) author_list = serializers.ListField(write_only=True) # def create(self, validated_data): # 创建数据 book = Book.objects.create(title=validated_data["title"], category=validated_data["w_category"], pub_time=validated_data["pub_time"], publisher_id=validated_data["publisher_id"]) book.author.add(*validated_data["author_list"]) # 多对多 return book # def update(self, instance, validated_data): # 处理 put 更新数据 instance.title = validated_data.get("title", instance.title) instance.category = validated_data.get("category", instance.category) instance.pub_time = validated_data.get("pub_time", instance.pub_time) instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id) if validated_data.get("author_list"): instance.author.set(validated_data["author_list"]) instance.save() return instance def validate_title(self, value): # 对传过来的title进行校验 if "python" not in value.lower(): raise serializers.ValidationError("标题必须含有python") return value def validate(self, attrs): if attrs["w_category"] == 1 and attrs["publisher_id"] == 1: return attrs else: raise serializers.ValidationError("分类以及标题不符合要求")
ModelSerializer序列化
现在我们已经清楚了Serializer的用法,会发现我们所有的序列化跟我们的模型都紧密相关~
那么,DRF也给我们提供了跟模型紧密相关的序列化器ModelSerializer
-- 它会根据模型自动生成一组字段
-- 它简单的默认实现了.update()以及.create()方法


# 注意:当序列化类MATE中定义了depth时,这个序列化类中引用字段(外键)则自动变为只读 class BookSerializer(serializers.ModelSerializer): class Meta: model = Book fields = "__all__" # fields = ["id", "title", "pub_time"] # exclude = ["user"] # 分别是所有字段 包含某些字段 排除某些字段 depth = 1 # depth 代表找嵌套关系的第几层
# depth = 1 #对第二级别的字段也进行序列化

class BookSerializer(serializers.ModelSerializer): category = serializers.CharField(source="get_category_display") class Meta: model = Book # 对应的 model # fields = ["id", "title", "pub_time"] fields = "__all__" # 所有字段 depth = 1 # 外键深度为1

拿到了较多的冗余字段
通过 SerializerMethodField 只取想要的字段,然后在下面定义各自的获取方法
自定义字段
class BookSerializer(serializers.ModelSerializer): # 只取想要的字段, category_display = serializers.SerializerMethodField(read_only=True) publisher_info = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj): return obj.get_category_display() def get_authors(self, obj): authors_query_set = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in authors_query_set] def get_publisher_info(self, obj): # obj 是我们序列化的每个Book对象 publisher_obj = obj.publisher return {"id": publisher_obj.id, "title": publisher_obj.title}
Meta中其它关键字参数
class BookSerializer(serializers.ModelSerializer): chapter = serializers.CharField(source="get_chapter_display", read_only=True) class Meta: model = Book fields = "__all__" # fields = ["id", "title", "pub_time"] # exclude = ["user"] # 分别是所有字段 包含某些字段 排除某些字段 depth = 1 read_only_fields = ["id"] extra_kwargs = {"title": {"validators": [my_validate,]}}
由于depth会让我们外键变成只读,所以我们再定义一个序列化的类,其实只要去掉depth就可以了~~ class BookSerializer(serializers.ModelSerializer): chapter = serializers.CharField(source="get_chapter_display", read_only=True) class Meta: model = Book fields = "__all__" # fields = ["id", "title", "pub_time"] # exclude = ["user"] # 分别是所有字段 包含某些字段 排除某些字段 read_only_fields = ["id"] extra_kwargs = {"title": {"validators": [my_validate,]}}
ModelSerializer反序列化
ModelSerializer 默认已经帮我们做了反序列化(不用写 create 方法)接受post 数据


class BookSerializer(serializers.ModelSerializer): # 只取想要的字段, category_display = serializers.SerializerMethodField(read_only=True) # 序列化(显示的时候)的 显示 publisher_info = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) # 定义获取字段的方法 def get_category_display(self, obj): return obj.get_category_display() def get_authors(self, obj): authors_query_set = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in authors_query_set] def get_publisher_info(self, obj): # obj 是我们序列化的每个Book对象 publisher_obj = obj.publisher return {"id": publisher_obj.id, "title": publisher_obj.title} # category = serializers.CharField(source="get_category_display") class Meta: model = Book # 对应的 model # fields = ["id", "title", "pub_time"] fields = "__all__" # depth = 1 # 字段的额外参数, "write_only": True 让下面这字段在反序列化的时候显示 extra_kwargs = {"category": {"write_only": True}, "publisher": {"write_only": True}, "author": {"write_only": True}}
from rest_framework import serializers from .models import Book # 外键序列化 class PublisherSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) # # # 传过来的书籍对象数据 # book_obj = { # "title": "Alex的使用教程", # "w_category": 1, # "pub_time": "2018-10-09", # "publisher_id": 1, # "author_list": [1, 2] # } # # data = { # "title": "Alex的使用教程2" # } def my_validate(value): # 自定义验证器,权重更高, if "敏感信息" in value.lower(): raise serializers.ValidationError("不能含有敏感信息") else: return value # class BookSerializer(serializers.Serializer): # id = serializers.IntegerField(required=False) # 不需要校验 # title = serializers.CharField(max_length=32, validators=[my_validate]) # CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) # category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True) # w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) # pub_time = serializers.DateField() # # publisher = PublisherSerializer(read_only=True) # publisher_id = serializers.IntegerField(write_only=True) # author = AuthorSerializer(many=True, read_only=True) # author_list = serializers.ListField(write_only=True) # # def create(self, validated_data): # 创建数据 # book = Book.objects.create(title=validated_data["title"], category=validated_data["w_category"], # pub_time=validated_data["pub_time"], publisher_id=validated_data["publisher_id"]) # book.author.add(*validated_data["author_list"]) # 多对多 # return book # # def update(self, instance, validated_data): # 处理 put 更新数据 # instance.title = validated_data.get("title", instance.title) # instance.category = validated_data.get("category", instance.category) # instance.pub_time = validated_data.get("pub_time", instance.pub_time) # instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id) # if validated_data.get("author_list"): # instance.author.set(validated_data["author_list"]) # instance.save() # return instance # # def validate_title(self, value): # 对传过来的title进行校验 # if "python" not in value.lower(): # raise serializers.ValidationError("标题必须含有python") # return value # # def validate(self, attrs): # if attrs["w_category"] == 1 and attrs["publisher_id"] == 1: # return attrs # else: # raise serializers.ValidationError("分类以及标题不符合要求") # 方法二 class BookSerializer(serializers.ModelSerializer): # 只取想要的字段, category_display = serializers.SerializerMethodField(read_only=True) # 序列化(显示的时候)的 显示 publisher_info = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) # 定义获取字段的方法 def get_category_display(self, obj): return obj.get_category_display() def get_authors(self, obj): authors_query_set = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in authors_query_set] def get_publisher_info(self, obj): # obj 是我们序列化的每个Book对象 publisher_obj = obj.publisher return {"id": publisher_obj.id, "title": publisher_obj.title} # category = serializers.CharField(source="get_category_display") class Meta: model = Book # 对应的 model # fields = ["id", "title", "pub_time"] fields = "__all__" # depth = 1 # 字段的额外参数, "write_only": True 反序列化的时候显示 extra_kwargs = {"category": {"write_only": True}, "publisher": {"write_only": True}, "author": {"write_only": True}}
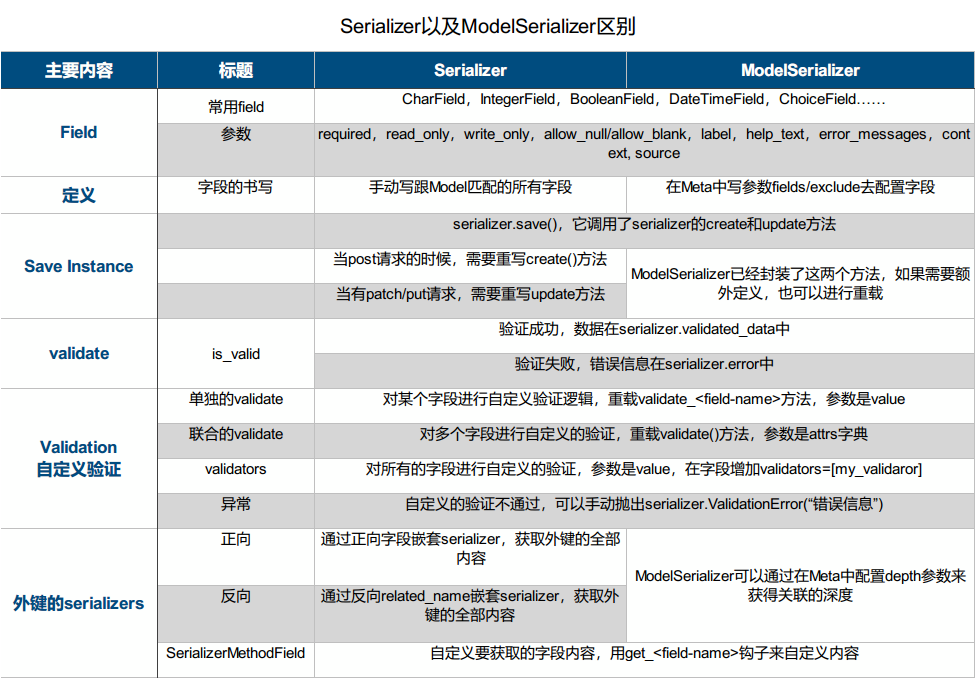
序列化组件小结

本文来自博客园,作者:元贞,转载请注明原文链接:https://www.cnblogs.com/yuleicoder/p/10425487.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号