

链家广州二手房的数据与分析——数据分析2
继续上一篇的工作继续分析广州链家二手房的数据。
>> Normality Test
用nortest package 的 ad.test() 分别对三个主要因素(面积,总价和均价)进行正态分布检验,结果显示这三个变量都不满足正态分布,而 Q-Q Plot 的表现方式就更直观了:
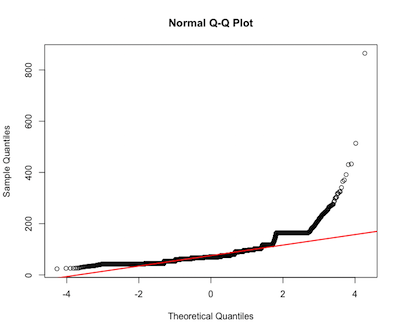
房子的面积
ad.test(house$area) #p-value < 2.2e-16 reject normality
qqnorm(house$area)
qqline(house$area, col = 2, lwd=2)
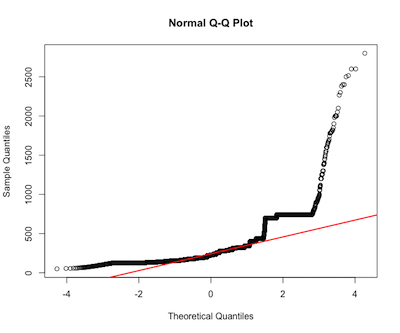
房子的总价
ad.test(house$total_price) #p-value < 2.2e-16 reject normality
qqnorm(house$total_price)
qqline(house$total_price, col = 2, lwd=2)
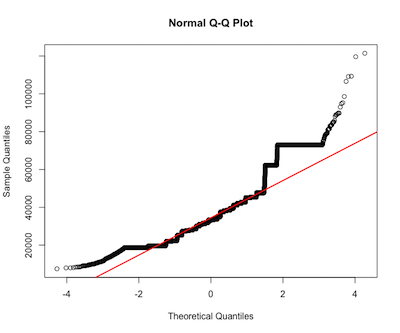
房子的单价
ad.test(house$unit_price) #p-value < 2.2e-16 reject normality
qqnorm(house$unit_price)
qqline(house$unit_price, col = 2, lwd=2)
因为房子的面积,总价和单价这三个变量均不满足正态分布,所以就不能对这三个变量进行 ANOVA 和线性回归等分析了。
>> Cluster Analysis
接下来我们可以将可知的房源划分归类。房子分类后对于卖家和中介而言就可以更精准地找到目标的客户群体,对于买家而言也可以避免花更多的时间去了解不合适的房子从而加快交易速度(毕竟房子总是蹭蹭蹭地往上涨不给人思考的时间~)我会用简单方便的 K-Mean 算法对房子实现分类的工作。
在开始聚类分析之前心里要大概有个数,到底这些房子应该分为几类才合适?聚类的原则就是组内的差距要小而组间的差距要大。我只选择面积和单价这两个最为重要的变量进行分析,并计算了不同分组的情况下的组内离差平方和:
tot.wssplot <- function(data, nc, seed=1){
tot.wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:nc){
set.seed(seed)
tot.wss[i] <- kmeans(data, centers=i, iter.max = 500)$tot.withinss
}
plot1 <- ggplot(data=data.frame(1:nc,tot.wss), aes(x=1:nc, y=tot.wss, group=1)) +
geom_line(color="#007CFF", linetype="solid", size=1.0)+
geom_point(color="#FF6666")+
scale_x_continuous(limits=c(0, 10),breaks = seq(0,10,2))+
scale_y_continuous(limits=c(10000, 45000),breaks = seq(10000, 45000,5000))+
xlab('Number of Cluster')+
ylab('Within groups sum of squares')
}
temp <- data.frame(scale(house[,c("area", "unit_price")]))
plot2 <- tot.wssplot(temp, nc = 10)
print(plot2)
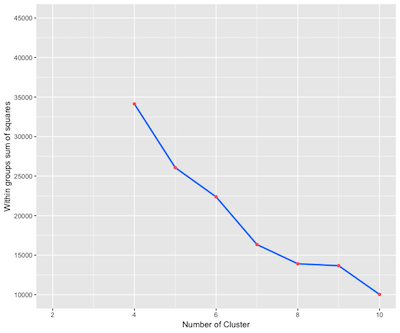
由上图的计算结果,我选择了将房子分为5类, 结果还不错。
set.seed(1)
group <- kmeans(x = temp, centers = 5, iter.max = 500)
print(group)
#K-means clustering with 5 clusters of sizes 7336, 3448, 16948, 19842, 3906
#(between_SS / total_SS = 74.7 %)
#### >> Interpreting Results
将分类的结果作为数据的一个新变量 house$group ,然后分组计算各组的房子的面积,总价和单价。
| Group | Area | Total Price | Unit Price | Count |
|---|---|---|---|---|
| 1 | 74.86566 | 154.5091 | 20766.57 | 7336 |
| 2 | 86.89919 | 595.8457 | 67492.40 | 3448 |
| 3 | 79.08328 | 310.8258 | 39814.88 | 16948 |
| 4 | 58.04336 | 179.4360 | 31160.86 | 19842 |
| 5 | 142.63028 | 460.6121 | 30534.02 | 3906 |
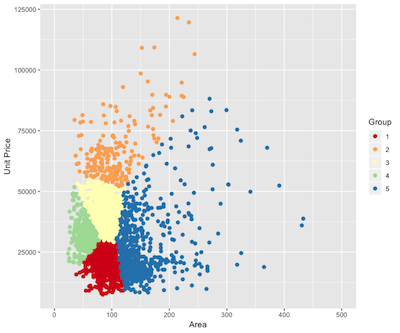
另外,第一组的房子集中的区域为市桥,新塘南,桥南等地;第二组的房子集中在东山口,淘金,天河公园等地;第三组的房子集中在京溪,昌岗,金碧等;第四组的房子集中在江燕路,西关,大石,祈福新村等;第五组的房子集中在麓景,荔城等。
综合上述的信息,我认为可以将广州的二手房大致分为以下5类:
- **上车盘型 ** :这组的房子大多位于市郊而且面积适中,价格较低。对于资金不够充裕的买家来说也是一个能够得着的选择。
- **区域中心型(好地段) ** :这组的房子大多位于广州市的黄金地段(或是交通或是学位等因素),均价是远远超过广州二手房均价的,而且物以稀为贵在房子上也能验证。这组的房子数量并不多。
- **刚需型 ** : 这组的房子大多位于广州市内,虽然不算很好的地段,但是至少交通配套等设施会比市郊的房子要好。面积适中,价格适中,房源充足。
- **“老破小”型 ** :这组的房子面积偏小,但是其集中所处的区域多处于江燕路和西关等老城区,所以其价格也不会很便宜,因为把这组的房子定义为“老破小”型。打引号的原因是这组内的房子不一定一一满足即老又小又破的特征,但是由数据推测该组的大多数房子会满足老破小其一的特征。
- 大户型 : 这组的房子面积较大,很容易就知道是包括别墅,复式等大户型的房子了。
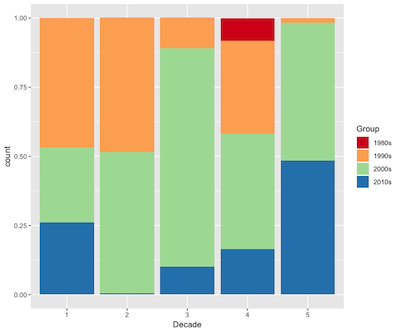
通过绘制房子分组与房子建筑年代的图形,可以确定第4组就是老房子居多了,基本80s的房子都属于第4组的房子。
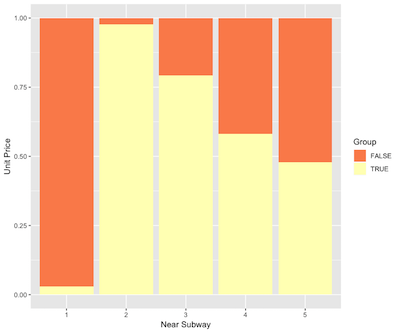
绘制房子分组与房子是否近地铁的图形,可以确定第2组是大部分是近地铁(代表交通发达)的好位置的房子,而第1组则符合预期猜测多为市郊的房子远离地铁。
最后,说了那么多,买房子就还是看看银行卡的余额……
相关文章:


