
CUDA Fortran环境的搭建和第一个CUDA Fortran程序
CUDA Fortran环境的搭建和第一个CUDA Fortran程序
前言
工作中需要用到CUDA Fortran对原有的Fortran程序做并行化,那么第一步就是要完成环境的搭建,总体来说过程并不是特别繁琐,但初次安装还是会遇到一些问题,因而在此概要性地做一下总结和整理.
背景
什么是CUDA
CUDA(Compute Unified Device Architecture),统一计算架构,是由NVIDIA公司所推出的一种结合CPU与GPU进行计算的架构.CUDA给程序开发人员提供直接访问CUDA GPU中虚拟指令集和存储器的接口.利用CUDA,GPU可以实现通用处理,而不仅仅是图形,这种方法被称为GPGPU(General-Purpose Graphic Processing Unit),与CPU不同的是,GPU侧重以较慢的速度执行大量并发的线程,而非快速执行单一线程,因而CUDA近些年来在并行计算中大放异彩.
编译器
一开始NVIDIA官方只提供了CUDA C/C++ 的接口和编译器,因此可以很方便地将C/C++代码移植到GPU上,但对于科学与工程即使算中的重要编程语言Fortran,无法直接改写为CUDA C/C++,为了使Fortran应用能够使用GPU进行加速,与NVIDIA公司合作的PGI(The Portland Group)小组设计了CUDA Fortran语言,并在自家的PGI Fortran编译器中支持了CUDA Fortran程序的编译.直到2013年,NVIDIA收购了PGI,并在2020年将PGI Fortran编译器整合到了NVIDIA官方推出的HPC_SDK中,其编译器名称也有了统一的命名.
现在CUDA架构中常见的编译器有:
- nvc: 可以编译CUDA C程序
- nvc++: 可以编译CUDA C++程序
- nvfortran: 可以编译CUDA Fortran程序
- nvcc: 可以编译CUDA C/C++程序
CUDA Fortran环境的搭建
确定设备环境
截至目前,CUDA Fortran尚且不支持Windows,因此以下所有内容均基于Linux操作系统进行:
操作系统
首先用cat /etc/os-release的方式来查看操作系统的版本并记录下来,后面会用到,我这里用的是ubuntu 20.04.
查找可用GPU
用lspci | grep -i nvidia来查找是否有可用的NVIDIA GPU,AMD的显卡是无法安装CUDA环境的.
CUDA Toolkit
当完成第一步的准备工作后,我们就可以开始安装CUDA环境了,CUDA Toolkit是一个整合了CUDA C/C++编译器,cuda-gdb调试器,nvprof性能监测工具,NVIDIA显卡闭源驱动,各种库文件的一个集成工具包.因此我们无需从安装驱动开始,而是直接安装CUDA Toolkit.
首先我们需要访问CUDA Toolkit下载页面,然后逐层选择适配自己设备环境的安装方式.我的环境所选内容如下图:
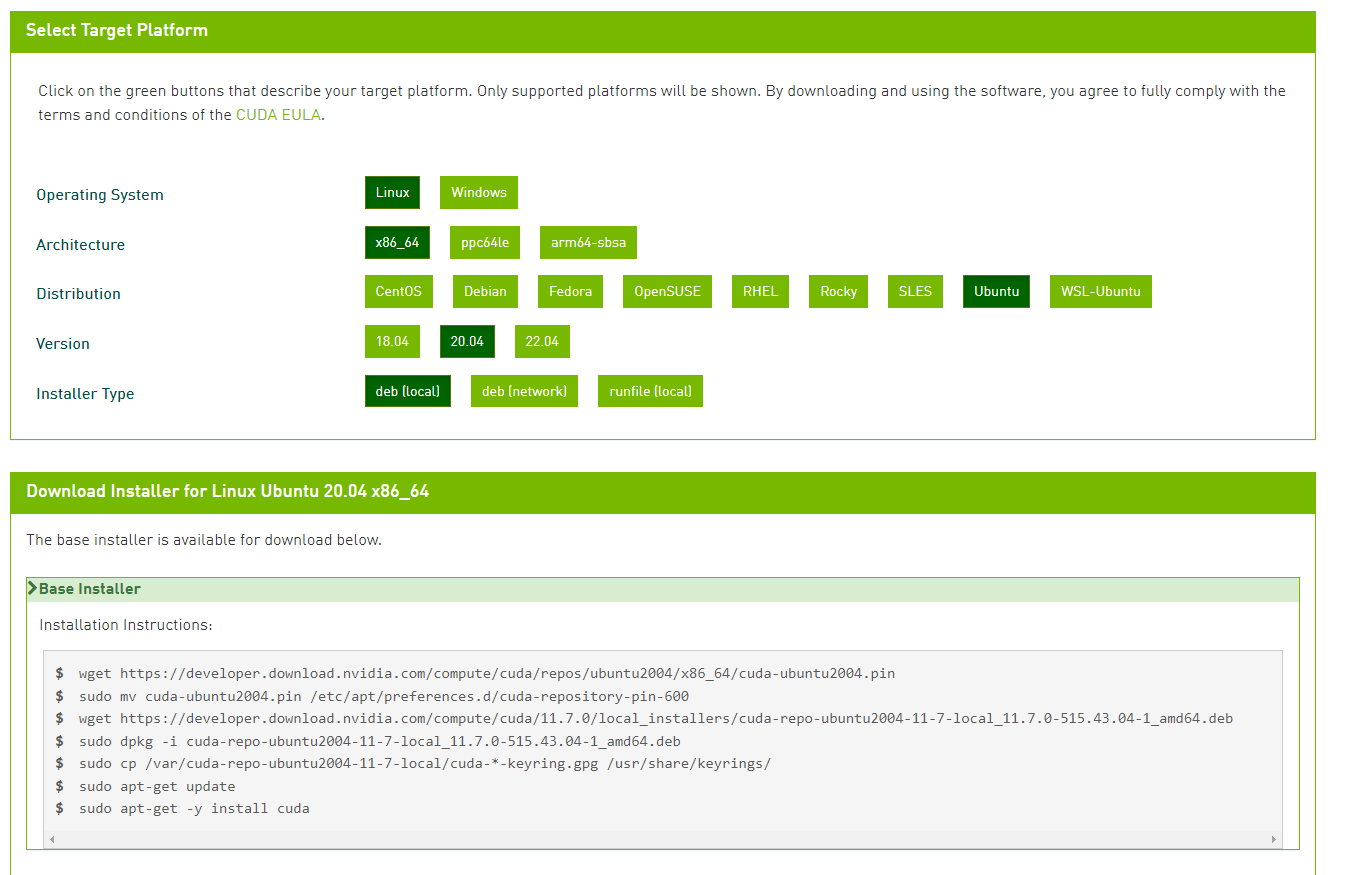
需要注意的是此页面是目前最新版的CUDA Toolkit下载页面,如果你所用的发行版没有被支持,可以寻找更早的CUDA Toolkit release版本.
选择完成后,按照其下方给出的 installation instructions 进行安装即可.
安装过程中只需要按照提示进行一些简单的操作即可,但需要注意的是,安装过程最好在非图形化界面下进行,否则可能会引发一些不必要的错误,图形界面用户可以用sudo init 3的方式进入纯命令行界面进行安装.另外,有些发行版中可能会默认安装了NVIDIA开源版本的显卡驱动nouveau,在安装前需要将其禁用,比较新的CUDA Toolkit会自行将其禁用而不需要我们手动进行,但若是安装一些比较古早的版本时,可能需要手动进行这一操作.
等待一段时间,当你安装完成后,屏幕上会给出提示,让你将bin包和库文件添加到环境变量中.选择你喜欢的编辑器编辑/home/'username'/.bashrc文件,(用你的用户名替换'username'),在文件的末尾加上以下内容:

如果你安装的不是CUDA 11.7,那么你需要进入/usr/local目录中,查看相应的cuda目录名,并将与第一行中的cuda-11.7进行替换.
完成之后source /home/'username'/.bashrc或者重新打开一个shell进行一些测试.
-
检测驱动
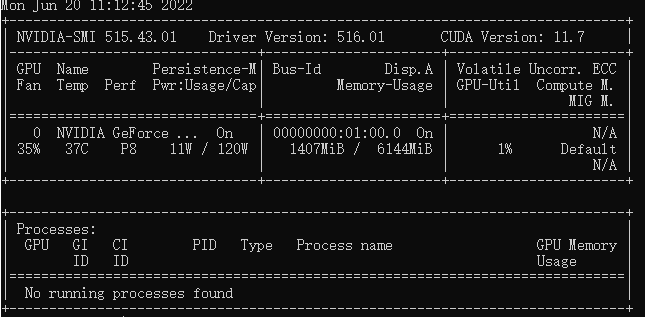
用nvidia-smi命令来检测驱动是否存在.若存在,会显示出详细的显卡信息,如下图:
-
编译器检查
在安装完CUDA Toolkit之后,事实上我们已经可以进行CUDA C/C++的 开发了,我们可以输入nvcc --version命令来检查CUDA C/C++编译器的版本,或者用which nvcc来查看PATH中是否能找到nvcc编译器.然后我们可以简单地编写一个CUDA C程序cudahello.cu来验证编译器是否能够正常运行,注意文件名需要命名为.cu后缀,否则需要在编译时添加编译选项告诉编译器这是一个cuda程序,否则会在链接时因为找不到运行时库而报错:
#include<stdio.h>
#include<cuda_runtime.h>
__global__ void cuda_hello()
{
printf("hello world from GPU!\n");
}
int main()
{
cuda_hello<<<1,10>>>();
cudaDeviceReset();
return 0;
}
退出编辑器后输入nvcc cudahello.cu -o cudahello.out,观察是否能够编译成功.若成功,再./cudahello.out查看运行结果是否正确,若没有错误的话,会输出10条' hello world from GPU!'
- 检查调试器和性能监视器是否存在
which cuda-gdb或者cuda-gdb --version来查看调试器是否存在,which nvprof或者nvprof --version查看性能监测工具是否存在.
若以上步骤都没有什么问题,那么我们就可以进行到下一步,进行CUDA Fortran的环境安装了.
HPC_SDK
首先需要根据你所安装的CUDA版本选择合适的HPC_SDK,然后在下载页面按照它的installation instruction进行安装.另外还有一些预先的准备事项和安装完成后配置环境变量等工作,其流程在官方安装指导中给出了详细的描述.按照官方文档中的方式进行安装.安装完成后,此时若是用which nvfortran命令会发现无法找到nvfortran编译器.是因为需要加载module文件.如果没有修改安装路径,那么sdk默认会安装到/opt/nvidia/hpc_sdk目录下,modulefile文件位于/opt/nvidia/hpc_sdk/modulefiles/nvhpc目录下,其中会有一个以你所安装的sdk版本命名的modulefile,我这里是22.5,然后需要module load ./22.5,这时再用which nvfortran发现已经可以找到nvfortran编译器了.
另外,module是Linux系统上用于加载和管理模块的命令,但是大多数的发行版中并未默认安装,因此在加载过程中可能会遇到 module:command not found的报错,需要用root权限来安装,CentOS为 sudo yum install environment-modules, Ubuntu为 sudo apt install environment-modules,安装完成后,重新打开一个终端或者 source /etc/profile.d/module.sh启用module命令,如果是csh则用 source /etc/profile.d/module.csh.
当然这样会存在一些麻烦,因为这样每次打开一个新的终端窗口,都需要重新输入这一长串的路径来加载module,为方便期间,我们可以给在usr/share/modules/modulefiles目录下给我们刚刚安装的module文件创建一个软链接文件,命令为:
sudo ln -s /opt/nvidia/hpc_sdk/modulefiles/nvhpc/22.5 /usr/share/modules/modulefiles/name
其中22.5需要根据你所安装的版本进行替换,最后的name则可以按照你的想法自定义一个名字.
完成以上的步骤后,我们可以用module avail查看可用的module,你所定义的name也会出现在列表中,此时我们可以直接module load name,就可以完成module的加载,而不用输入之前的一长串路径.
检查
完成以上步骤后,分别用nvfortran --version和man nvforrtran进行测试,若能够正确显示其版本及手册,说明配置无误.若不能,或者仅手册不能,则说明环境变量没有配置好,可以详读官方安装指导进行配置.若没有问题,则进入/opt/nvidia/hpc_sdk/Linux_x86_64/22.5/examples/CUDA-Fortran中,将SDK目录复制到你的家目录下.然后make,若结果显示为:

则说明环境没有问题,配置完成!
第一个CUDA Fortran程序
hello world
当我们搭建好环境,就需要写一个程序来测试一下功能了,新建一个hello.cuf文件,同样要注意后缀名,若后缀名不是.cuf,则需要在编译选项中指定.在文件中添加一个简单的hello world代码块:
module hello_m
contains
attributes(global) subroutine hello()
implicit none
print*, 'hello world from GPU!'
end subroutine hello
end module hello_m
program main
use cudafor
use hello_m
implicit none
integer :: ierr
call hello<<<1,10>>>()
ierr = cudaDeviceReset()
end program main
然后进行编译:
nvfortran hello.cuf -o hello.out
然后./hello.out执行一下,若执行结果能正确显示十个hello world from GPU!,则说明没有问题,CPU和GPU之间可以正常通信.
以上
2022年6月29日更新
前文所提到的不用.cuf作后缀是因为vim尚且不支持CUDA Fortran的语法高亮显示,因而在vim中编辑.cuf文件时文本全部呈黑色,可以将文件名后缀修改为.f90以获得fortran语法的高亮显示,在编译时添加 -Mcuda 编译选项来告诉编译器这是一个cuda文件,另外,在vim8之后的版本,是支持CUDA C语法的高亮显示的,即.cu后缀文件.但如果你想要保留.cuf后缀,且高亮显示的话,就需要一些其他的方法,参见:
https://forums.developer.nvidia.com/t/text-color-of-file-cuf/134097
但此博文所说方法并非完全起效,会出现一些奇怪的问题,如错误识别非.cuf文件并更改其语法高亮,或者高亮显示有瑕疵等.还需要寻找更加合适的方法.
