Sql server Insert执行的秘密(下) 带外键的INSERT分析
上一篇文章介绍了一个最简单INSERT语句的执行计划详细情况,这一篇分析一下带外键表的INSERT的例子。

本文所用的数据表结构如上图所示;其中Blog表上BlogID是自增的主键,并在CreateUserID和CreateTime列上分别建有两个非唯一索引。
我们要往Blog表中插入一条数据,并分析其执行情况。
INSERT 语句如下:
INSERT INTO [DB_Cn].[dbo].[Blog]
([Title]
,[Tags]
,[Content]
,[CreateUserID]
,[CreateTime]
,[IP])
VALUES
('这是一个测试博客标题'
,'测试'
,'这是测试博客的内容,博主的地址是http://www.cnblogs.com/yukaizhao/'
,100
,'2010-01-06'
,'127.0.0.1');
其执行计划要稍微复杂一些,如下所示
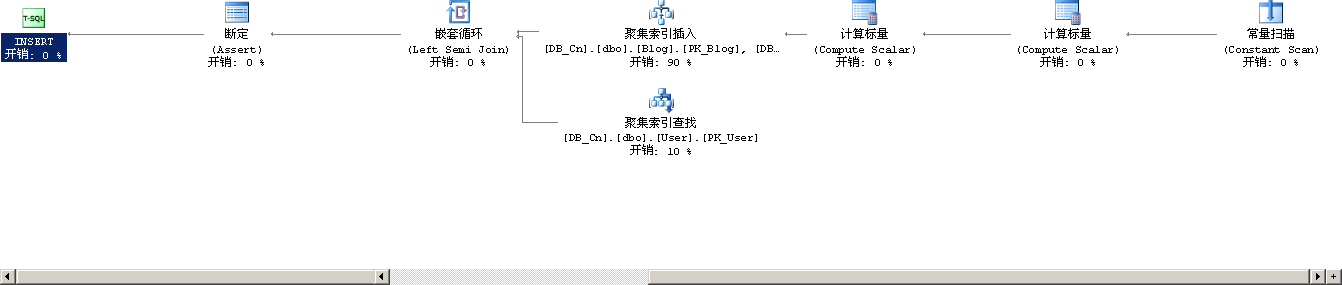
从右向左分析,第一步中的常量扫描是根据用户输入的sql语句生成一个数据行;第一个常量扫描生成了一个新的自增长id;第二个计算标量则是计算用户输入的sql语句中的常量值,这些在上一篇文章中有详细的叙述,请参考上文。
第四步是分叉的两步操作,上面的操作是聚集索引插入,下一步的操作是对User表的聚集索引查找,如下图是聚集索引插入的详细情况:

逻辑索引插入的部分估计开销为90%,这一步插入Blog表的主键,Blog表的两个索引IX_Blog和IX_Blog_CreateTime,对这两个索引的操作说明了在表中建索引会对表的插入操作效率产生负面影响;由于Blog表的CreateUserID字段是个外键,所以这一步还有一个输出列表输出了CreateUserID字段;这个字段要用来做外键是否存在的判断。
我们再看下对User表的聚集索引查找操作的详细情况:

这步中查找的对象是PK_User及User表的主键,主键的扫描是非常迅速的,尽管如此当User表非常大时,扫描的开销也是非常可观的。这里扫描的开销可以分为两个部分,一部分是cpu的开销,另外一个方面是扫描时sql server会自动给主键加上一个共享锁,既然加锁就有可能会造成死锁或排他锁的等待。
从这一步看如果我们对响应速度的要求远大于对数据一致性的要求时,可以考虑删掉外键,去掉这一步不必要的开销。
第五步:对第四步两个分叉操作产生的输出进行嵌套循环,这一步嵌套循环是为下一步的Assert做准备
第六部:Assert判断嵌套循环产生的CreateUserID是否为NULL,如果为NULL则会引发外键不存在的异常
最后一步执行INSERT操作。
从以上分析可以得出几点心得
1. 为什么使用自增长字段,在插入数据失败时自增长字段的编号会被占用?
因为自增长字段的值是在第二部计算标量是产生的,这一步已经将自增id加1了
2. 为什么给表建的索引多了会影响插入的性能
因为每一次插入都需要对每一个索引进行插入
3. 为什么在做大并发设计时,会不建外键,或将外键删除掉
因为外键会带来额外的cpu开销和锁资源的开销

 浙公网安备 33010602011771号
浙公网安备 33010602011771号