



一个“”字引发的痛苦经历
(一篇老文章,还有点价值,特意整理了一下。由于涉及客户项目,已经进行了脱敏处理)
1 写在前面的话
虽然这个问题是有解决方案的,但我不建议大家提供给客户,理由见此。
2 问题描述
2010.10.12,业务部门提交问题单(2010.09.14):在对xx铁路局进行“缴费通知单明细信息导入”时,因遇到生僻字“贾”(上龙下天),系统无法识别并报错,使得业务不得不暂停,望给予解决。
3 问题分析
3.1 初步分析
生僻字的乱码问题, 我们认为在生产系统中是不存在的 (除非超出 GBK 字符集的范围),因为系统运行 2 年多来,已经录入了一些不在 GB2312 中的生僻字。
在开发环境中验证,导入存在生僻字的个人基本信息,没有问题;
在 21 测试环境中(AIX+WebLogic+Oracle) ,导入存在生僻字的个人基本信息,有问题,并且在界面上也无法直接录入。
开始在 21 测试环境中分析问题:
1、检查 AIX、ORACLE 等相关字符集设臵,未发现问题;
2、上传文件后,BLOB 字段中的信息正确;
3、修 改 startWeblogic.sh 文 件 , 在 启 动 java 时 , 增 加:
-Dfile.encoding=GBK -Ddefault.client.encoding=GBK,没有效果;
4、修改前台 BAT,增加上述参数,没有效果;
基于第 2 点,证实环境没有问题,怀疑问题出在导入的代码中,可能是读取、转换时造成的乱码。
检查代码。 在 xxx.xx.xxxx.PersonInfoInputBO 类的 batchProcess 方法中, 增加调试输出信息,发现在实际保存数据前,都没有乱码,只是在以下代码执行后,数据库中保存的数据为乱码:
if (!bHasErr ) { getHibernateTemplate().saveOrUpdateAll(arr); }
至此,确认代码没有问题,只能怀疑是数据库驱动的问题。使用以下方式验证:
1、删除 WEB-INF/lib/classes12.zip 文件。
2、把 17 上 eprk_a 环境中的数据库连接池驱动类型从 Oracle 改为 Weblogic(数据库:dtp/dtp1521@21_DB)。
重新导入数据,结果正确,未发生乱码现象。
另,在界面上仍无法录入“”字,怀疑与客户端程序(JRE)中的字符集环境设臵有关。
可以确定是 Oracle JDBC 驱动的问题。 Oracle Thin(OJDBC14.jar/Classes12.jar)的 JDBC 驱动与其它数据库的 JDBC 驱动在字符集设臵方面有区别。其它数据库(如DB2/SQLServer 等)的 JDBC 驱动是可以在 URL 中指定字符集的,但 Oracle 的 JDBC 不可以,将自动使用系统、用户的当前字符集。
使用 Weblogic 的数据库驱动,可解决上述问题,并且性能会有所提升,但第三方驱动的安全有效性值得怀疑,且需要大规模测试。
该问题尚未解决。
以上结论有问题。
3.2 进一步分析
部门其他项目组同事打电话说明也存在相同的问题,本人认为这个问题有一定的挑战性,同时需要一个明确的答案,因为以后一定还会碰到,并且这是对本人相对空档时期的严重藐视,故下决心解决此问题。历时一周,在无数次检查、发版、调试、Google、挑灯夜战、希望、失望、绝望。 。 。后,终于有了结论,抱墙痛哭。
之所以形成这个详细的文档,除了记录并缅怀我那近 50个工时外,还希望对我及对本文档感兴趣的同事警示以下基本要点:
一、不要放过任何你认为“应该不会吧”的假设,一定要验证之;
二、必须要有全局视角,对问题的前后左右,每一步进行细致的验证;
三、Microsoft、IBM、ORACLE 都 TM 操蛋!GB 码更操蛋!!
四、不是兄弟我无能,实在是共军太狡猾了。
五、很多事情,你跟他讲理吧,他跟你耍流氓;你跟他耍流氓吧,他跟你讲理。还是耍流氓比较好。唉。
在初步分析中, 结论是 Oracle 数据库驱动的问题, 但在 WINDOWS 中, 使用Oracle JDBC驱动连接相同的数据库是没有问题的,所以这个结论是不正确的,但 Oracle 的驱动的确存在不能设臵字符集的问题。
还是怀疑是环境的问题,在 GBK 和 GB18030 之间反反复复尝试,由于需要在 AIX 上发版,这个过程几乎占用了80%的时间,尝试了几乎所有的可能性和排列组合,问题没有得到解决。
3.2.1 环境检查的要点
1、检查 Oracle 数据库字符集:
select * from nls_database_parameters;

注意红框处。另外,还有以下相关的 SQL;
select * from nls_instance_parameters;
select * from nls_session_parameters;
select userenv('language') from dual;
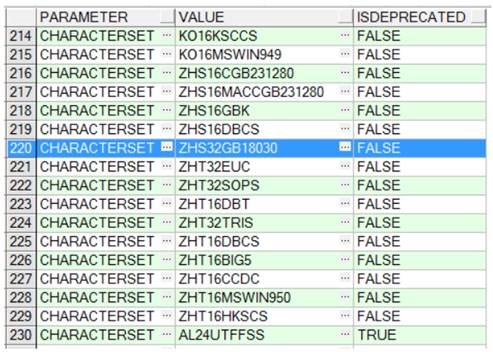
这里有个问题,ZHS16GBK 我理解对应 GBK 编码,检查数据库,GB18030 在数据库中应对应 ZHS32GB18030 编码,但由于 Oracle 数据库安装好后再改字符集存在较大风险,没有进行尝试,以下 SQL 可以查看 Oracle 支持的所有字符集:
select * from V$NLS_VALID_VALUES v where v.PARAMETER = 'CHARACTERSET';

2、检查 AIX 系统字符集(WINDOWS 系统不用检查)

3、检查 AIX 用户环境设置
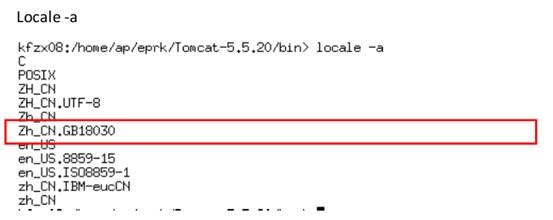
env

LANG,应为 GB18030 或 Zh_CN.GB18030(注意大小写)
NLS_LANGUAGE,应为 AMERICAN_AMERICA.ZHS16GBK,经测试,这个参数不设也没有关系,但相关文档中都是这么要求的,所以还是设臵上为好。
4、JAVA
在服务器(TOMCAT、Weblogic) 、客户端相应的启动 JAVA 的角本中,增加以下参数:
SUN JDK:-Dfile.encoding=GB18030
IBM JDK:-Dibm.stream.nio=true –Dfile.encoding=GB18030
5、在运行时检查环境
参考以下代码
(略)
可以在后台业务处理类或其它地方,嵌入以上代码,并把输出定向到 logger 中,注意输出信息中与encoding 相关的输出值。
一个很没意思的细节:Windows中,sun.unicode 值为 UncodeLittle,AIX 中,其值为UnicodeBig。 太 TM 乱了。 为什么在 Windows中就是Little?在 AIX 中就是 Big?就因为 “微软”?太 TM 有才了。哦,I'm a Big Man!
BTW:金正日是金日成的儿子。据说翻成 E 文是这样的:The King who is fxxking is the son of the King who has fxxked.
3.2.2 下载 并安装 IBM JDK
暂时排除 Oracle JDBC 驱动的嫌疑,在跟踪代码时,发现在调用 JdbcTemplate 保存 VO 前,都能查看到正确的汉字(能够在 logger 中输出。这是最大的、错误的疏漏,其实这时已经乱码了),怀疑是 Hibernate 编码转换的问题,疯狂跟踪、分析 Hibernate 的相关代码,发现虽然看得到汉字,但其value 值为空。往前怀疑,IBM JDK的问题。
SUN从来没有为IBM POWER系列CPU提供过JDK。JDK1.4前,IBM在SUN JDK的基础上修改形成 IBM JDK,JDK 1.4 及以后,IBM 自主开发 JDK。由于只在测试环境中存在问题,每次都要发版,太不方便了,决定下载 IBM JDK,在本机上,看能不能复现问题。
IBM JDK 太难下载了。其官网上只提供 JRE 下载,并且必须安装在 IBM 的机器上,会检查BIOS!Fxxk!
NND,死马当作活马医,我不过了,我决定下载 IBM 官网提供的、所有与 JAVA 相关的东西。还好,美帝总是欺软怕硬的,在 IBM 提供的,基于 Eclipse 的开发环境里就有 IBM JDK 1.6,是完整的 JDK,并且没有 BIOS 限制。下载地址我忘了,下载后的文件名为:
IBM_DevelopmentPackage_for_Eclipse_Win32_3.0.0.zip
好了,米有了,下锅吧。
3.2.3 适配 IBM JDK 和嵌入式 Tomcat
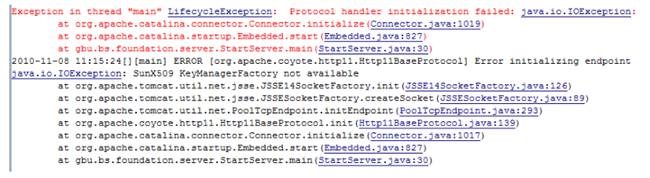
把开发环境中项目的 JRE 改为 IBM JDK 中提供的 JRE,启动 Tomcat,报错:

查了一下,Tomcat 的 SLL 设臵默认使用 SUN 的 X509。但 IBM JDK 中,改成了 IbmX509。
怎么设置?真是闹心。一阵狂试,修改方式如下:
修改 StartServer:
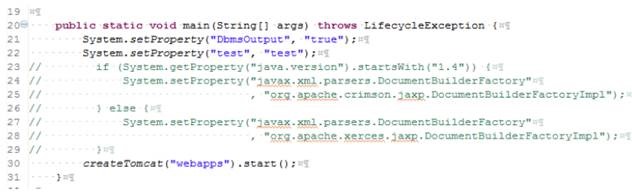
1、在合适的位臵增加 c.setAttribute("algorithm", "IbmX509");
2、注释 main 函数中与 XML 处理相关的代码,如下图:

不知道这样是不是就够了。 我估计不够, 还需要修改 IBM JDK 相关的文件, 具体改了哪里,我不记得了,也不想记得,最终文件如下:
1、把xerces.jar文件放到 ibm_sdk60\jre\lib 目录中;
2、把xerces.properties文件也放到上述目录中。
进行以上修正后,StartServer 能够在 IBM JDK 中正常使用。
调试环境就绪,可以稍微舒心一点干活了。
3.3 问题解决
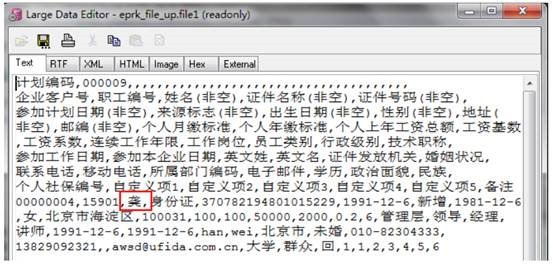
3.3.1 查看数据库 BLOB 字段中的内容
前文描述过,上传文件后,数据库中 BLOB 字段中的数据看起来没有问题。
数据库 BLOB 中的信息:

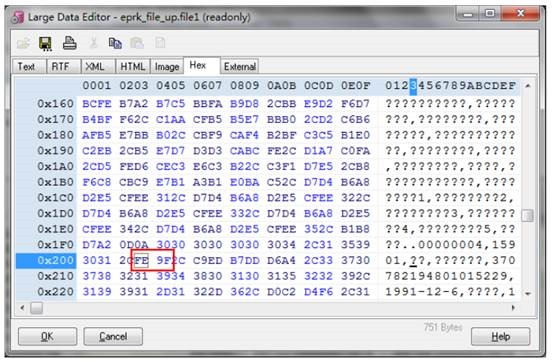
以十六进制查看:

所以从来没有怀疑在导入操作前就存在问题,到这个地步,只能再往前走,根据目前掌握的信息,怀疑在上传时,就存在问题了,理由如下:
1、在跟踪“导入”代码时,发现虽然这个字能够输出到日志,但其 value 值为空;
2、GB18030 针对 GBK 增补的汉字(特别是 FE 区),在 Unicode 中有两个编码;
3、JDK 默认编码使用 Unicode(UTF8);
4、WINDOWS 默认编码使用 GBK。
3.3.2 在ORACLE 中进行编码转换试验
select convert('屁, 'ZHS16GBK', 'ZHS16GBK') gbk, convert('屁, 'ZHS32GB18030', 'ZHS32GB18030') gb18030, convert('屁, 'UTF8', 'UTF8') utf8, convert('屁, 'ZHS16GBK', 'UTF8') utf2gbk, convert('屁, 'ZHS32GB18030', 'ZHS16GBK') gbk2gb18030, convert('屁, 'ZHS32GB18030', 'UTF8') utf2gb18030, convert(convert('屁, 'UTF8', 'UTF8'), 'ZHS32GB18030', 'UTF8') utf2gb18030 from dual;

说明:Convert(内容,目标字符集,来源字符集)
特别注意 GBK2GB18030,乱码了。GBK 是 GB18030 的子集,它们之间的转码根据官方描述应不存在问题,但实际转码时“屁”没有问题, “”有问题。个人推断:Oracle 内部默认字符为Unicode(UTF8), 在进行转码时, 使用Unicode 编码方式进行中间过渡, 导致在Unicode中有两个编码、GB18030 中只有一个编码的汉字乱码。
查看源文件中的编码:

也没有问题啊!唉,这里看起来是没有问题,而且 16 进制编码与数据库 BLOB 字段的也一样,但问题的关键却就在这里。我试着说一下我的理解,不一定对哈:
GBK 是没有收录“”字的,但在 WINDOWS、UltraEdit 却都能正常显示,为什么?因为我安装了 Office(或是其它)提供 GB18030 字符集支持的软件,但 WINDOWS 系统默认是GBK 编码(WIN 7也是)!能显示并不代表编码正确!并且我并没有为 Txt 文件指定编码格式,显示的时候没有问题,当 IBM JDK 以字节流方式读入文件时,这个文件的编码格式被认为是Unicode(UTF8), 即使我明确要求转码为GB18030, 也就是从Unicode(UTF8)转为GB18030,由于取的是 Unicode 中两个编码中对应不到 GB18030 中的那个,所以乱码了。
至此,怀疑 TXT 文件的编码格式有问题。嘿嘿。
3.3.3 修改源文件编码格式
使用 UltraEdit 转码,不支持 GB18030……下载 EditPlus,支持。转码后,相同内容、不同编码格式的文件大小有区别(GB18030 编码的文件大几个字节),并且 GB18030 编码格式文件中的“ ”在记事本中显示的是乱码。乱码就有门啦,不是 GBK,不是 Unicode,是 GB18030啦。
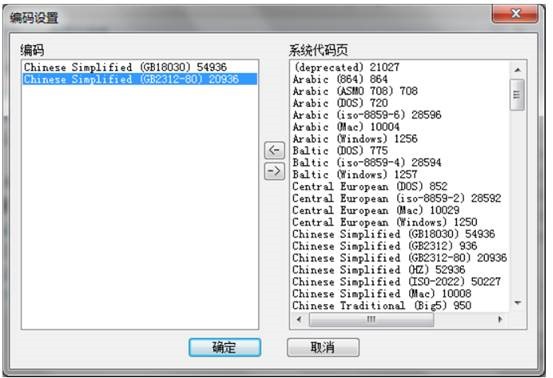
使用 EditPlus 打开 txt 文件, “另存为” :

注意:默认情况下, “编码”框中没有 GB18030,需要先使用“More…”引入,方式为在弹出框中把需要的编码放到左边就行:

GB18030 文件内容,在记事本中无法正确显示:

相应修改源代码
xxx.xx.xxxx.mapping.DataMapping
public Document xsltTransform(Document sourceDoc, MappingContext context) {
Document targetdoc = XMLUtils.getDocumentBuilder().newDocument(); System.out.println("begin xslt Transform " + new Date() + ":" + new Date().getTime()); try { mappingContextLocal.set(context); Transformer transformer = template.newTransformer(); transformer.setOutputProperty(OutputKeys.ENCODING, "GB18030"); transformer.transform(new DOMSource(sourceDoc), new DOMResult(targetdoc)); } catch (TransformerException ex) { throw new EaiException(ex); } return targetdoc; }
增加红色部分的代码。
private Document getSourceDocFromExcel(Object src, Worksheet page) throws BiffException, IOException, EaiException { 。。。 } else if (src instanceof byte[]) { byte[] bytedata = (byte[]) src; if (bytedata.length > 2 && bytedata[0] == -48 && bytedata[1] == -49) { workbook = Workbook.getWorkbook(new ByteArrayInputStream((byte[]) src)); } else { iscsv = true; csvdata = new String((byte[]) src,"GB18030"); } } else { iscsv = true; csvdata = (String) src; } 。。。 }
修改红色部分代码。
xxx.xx.xxxx.File_upBO
private void afterInputSave(File_upVO vo, String path) { if (DataMapping.getMappingContext() != null && DataMapping.getMappingContext().getErrMsg() != null && !"".equals(DataMapping.getMappingContext().getErrMsg())) { try { vo.setFiles(DataMapping.getMappingContext().getErrMsg().getBytes("GB18030")); } catch (UnsupportedEncodingException e) { throw new RuntimeException(e.getMessage()); } vo.setMemo("导入数据出现失败"); } else { vo.setMemo("导入数据全部成功"); } }
修改红色部分代码。
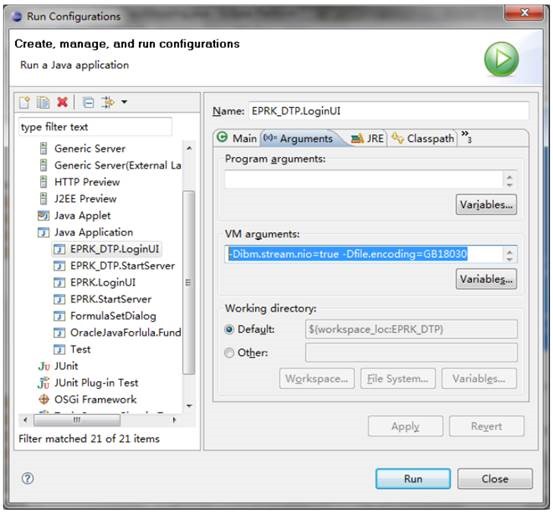
3.3.4 修改 JRE 参数
为 StartServer、LoginUI 指定正确的 JRE 参数:

主要是-Dfile.encoding=GB18030,在 IBM JDK 上,最好再加上-Dibm.stream.nio=true。因为IBM JDK 在 IO 异常处理方面,比 SUN JDK 要严格,别那么麻烦算了。
注意:如果使用 Client,必须在 login.bat 中进行相应的设置。
3.3.5 运行并测试
没有问题了,上传、导入、显示均正常。
4 要点总结
1、 来源文件的编码格式必须正确;
2、 JRE 参数的编码格式必须正确;
3、 JAVA 代码中转码设臵必须正确;
4、 操作系统编码必须支持 GB18030;
5、 操作系统用户的语言环境必须是 GB18030,包括数据库 NLS 设臵;
6、 数据库编码必须为 ZHS16GBK。(如果是 ZHS32GB18030 呢?没有环境测试,想来也是正确的)
7、 以本例来看,由于来源数据是 txt 类型的,所以对应到 BLOB 字段是不合适的,如果使用 CLOB,情况要简单得多,代码也要简单得多。
5 体会
1、 汉字的标准化、国际化,还有很长的路要走啊,并且很可能现在就走乱啦,不知道几只脚在走路啦。
2、 Oracle,你丫真能显示甲骨文么?
6 最终结论及建议
先发点牢骚,你说 GB2312 中 6 千多个汉字不够起名用的,那么兄台,GBK 中 2.1 万个汉字可够?你一定要 GB18030 吗?为什么?WINDOWS都不支持呀,很多输入法都不支持呀,身份证、银行卡等一系列需要把信息保存到计算机的事你很可能都没法办了呀。一定要?俺给你起个名,SB!
按照我前一个行业的经验来看,名字实在不宜起得太复杂。最好就用 GB2312 里的字,太复杂了的话,要么连老师都不认识,要么写起来麻烦。你想想,人家孩子的名字 10 来个笔划,你家孩子的名字 100 来个笔划,新学期发下 10 来本练习本,要求立刻把姓名都写上,你信不信你家孩子写哭了也写不好?造孽呀。
言归正传,虽然这个问题是有解决方案的,但我不建议大家提供给客户,理由如下:
1、 Windows默认编码为 GBK,很多输入法也是;
2、 就算解决了这个生僻字,不知道还没有其它生僻字有问题?康熙字典中有 4.7 万个汉字,能全部支持吗?不能!
3、 你架不住有强人如武则天,在仓颉、许慎等人基础上,自己造字吧?
4、 在计算机里,存在太多的方言,也有太多的水翻译,并且有些方言里的字,在其它方言里根本不存在——讲理的话,应该、必须存在的。
5、 要大范围检查并修改代码。
6、 测试覆盖率怎么定?生僻字怎么定义?我们知道有多少生僻字么?
结论:对于 GBK 没有收录的汉字,系统也不提供支持。要么拆开输入,要么用拼音代替,要么客户自己想替代方案。
对于怎么判断汉字在不在 GBK 里,目前我能想到的比较省事但客户操作起来比较麻烦的解决方案是这样的: 我们向客户提供附件中的 GBK 汉字编码表, 由客户在需要时去一一对比。
不知道客户会不会接收?或自动放弃?或自动想其它办法?
我的方法或描述可能存在问题,但我的结论就这样了。爱咋地咋地。
7 附
7.1 汉字编码表
GBK汉字编码对照表.xls
gb18030的汉字编码.xls
7.2 GB18030 针对 GBK 增补的部分汉字(FE 区 )
增补汉字和部首 80 个, 包括 28 个部首和 52 个汉字。 GBK 编码是从 FE50-FE7E, FE80-FEA0。

在制定 GBK 时,Unicode 中还没有这些字符,所以使用了专用区的码位,这 80 个字符的码位是 0xE815-0xE864。后来,Unicode 将 52 个汉字收录到“CJK 统一汉字扩充 A” 。28 个部首中有 14 个部首被收录到“CJK 部首补充区” 。所以在上图中,这些字符都有两个 Unicode 编码。


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}