软考笔记(六)高级系统架构师/分析师:数据库
目录
- 软考官网 报名通道
- 软考架构师笔记(一):计算机系统基础
- 软考架构师笔记(二):计算机网络基础与信息安全
- 软考架构师笔记(三):操作系统基础
- 软考架构师笔记(四):企业信息化与系统规划
- 软考架构师笔记(五):系统需求工程 需求分析
- 软考架构师笔记(六):数据库
- 软考架构师笔记(七):系统分析 系统设计
- 软考架构师笔记(八):系统架构
- 软考架构师笔记(九):软件工程与项目管理
- 软考架构师笔记(十):系统测试 维护 稳定性
数据库模式
三级模式、两级映射
外模式、模式、内模式
外模式/模式映射、模式/内模式映射
外模式:External Schema或Sub Schema,视图,用户模式,是数据库用户能看见和使用的局部数据的逻辑结构,与某一应用有关的数据逻辑表示。外模式通常是模式的子集,一个数据库有多个外模式。概念结构设计阶段的产物,E-R图。
模式:Schema,也成为逻辑模式,概念模式关系表,数据库中全体数据的逻辑结构和特征的描述,所有用户的公共数据视图。模式实际上是数据库数据在逻辑级上的视图。一个数据库只有一个模式。逻辑结构设计阶段的产物,表结构。
内模式:Storage Schema,存储模式。一个数据库只有一个内模式,数据物理结构和存储方式的描述,数据在数据库内部的表示方式。物理设计阶段产物。物理设计阶段产物。
两类独立性:
数据的物理独立性:当内模式(物理模式)发生改变时,数据的逻辑结构(模式)保持不变。需要修改模式/内模式映射。
数据的逻辑独立性:数据的逻辑结构(模式)发生变化时,应用程序不用修改。需要修改外模式/模式映射。
(XX独立性,就是指XX变化时,上级模式不用变!!!!!)
数据库设计过程

需求分析->概念结构设计-> 逻辑结构设计->物理设计
外模式:概念结构设计阶段的产物,E-R图
数据库概念结构设计阶段的工作步骤:抽象数据→设计局部视图→合并取消冲突→修改重构消除冗余 ER模型
模式:逻辑结构设计阶段的产物,表结构
内模式:物理设计阶段产物
关系代数
并 S1 U S2
交 S1 N S2
差 S1 - S2
笛卡尔积 S1 X S2
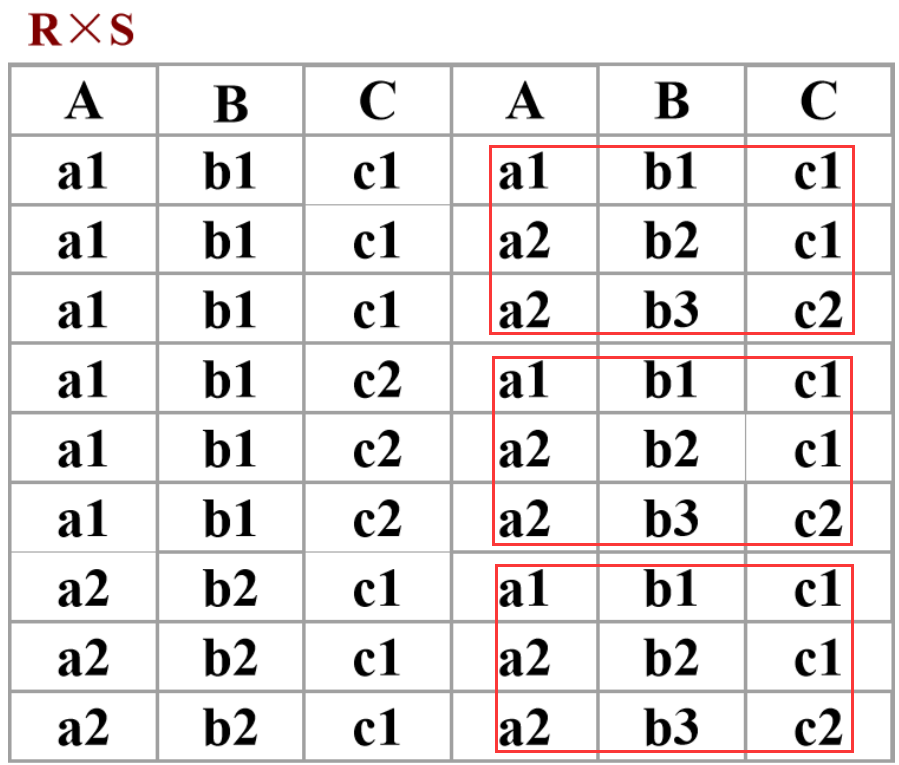
投影 S1 选择固定的列
选择 S1 选择固定的行
自然连接 : 做拼接, 找到指定的有相同元素的行,不相同的 补在后面
运算效率问题:尽早做选择的操作
规范化理论
键
- 超键 : 能够唯一标识元组
- 候选键 :消除多余属性
- 主键 候选键任选一个
- 外键 其他关系的主键
非规范化的关系模式,可能存在的问题包括:数据冗余、更新异常、插入异常、删除异常
优化方法:泛式

关系模式R<U,F>来说有以下的推理规则:
A1.自反律(Reflexivity):若YsXcU,则x一Y成立。
A2.增广律(Augmentation):若ZcU且X→Y,则XZ一YZ成立。
A3.传递律(Transitivity):若X一Y且Y一Z,则X一z成立。
根据A1,A2,A3这三条推理规则可以得到下面三条推理规则:
合并规则:由x一Y,X一Z,有X一YZ。(A2,A3)伪传递规则:由X→Y,WY-Z,有xW-Z。(A2,A3)
分解规则:由X→Y及ZSY,有X→Z。(A1,A3)
函数依赖
设R(U)是属性U上的一个关系模式,X和Y是U的子集,r为R的任一关系,如果对于r中的任意两个元组u,v,只要有u[X]=v[X],就有u[Y]=v[Y],则称X函数决定Y,或称Y函数依赖于X,记为X一Y。
A B 共同决定 C, 则C 部分函数依赖 A,B
A决定B, B决定C, C传递依赖A
数据库安全
- 用户标识和鉴定
- 存取控制
- 密码存储和传输
- 视图的保护
- 审计
数据备份
- 冷备份也称为静态备份,是将数据库正常关闭,在停止状态下,将数据库的文件全部备份(复制)下来。
- 热备份也称为动态备份,是利用备份软件,在数据库正常运行的状态下,将数据库中的数据文件备份出来。
- 完全备份:备份所有数据
- 差量备份:仅备份上一次完全备份之后变化的数据
- 增量备份:备份上一次备份之后变化的数据
- 日志文件:事务日志是针对数据库改变所做的记录,它可以记录针对数据库的任何操作,并将记录结果保存在独立的文件中。
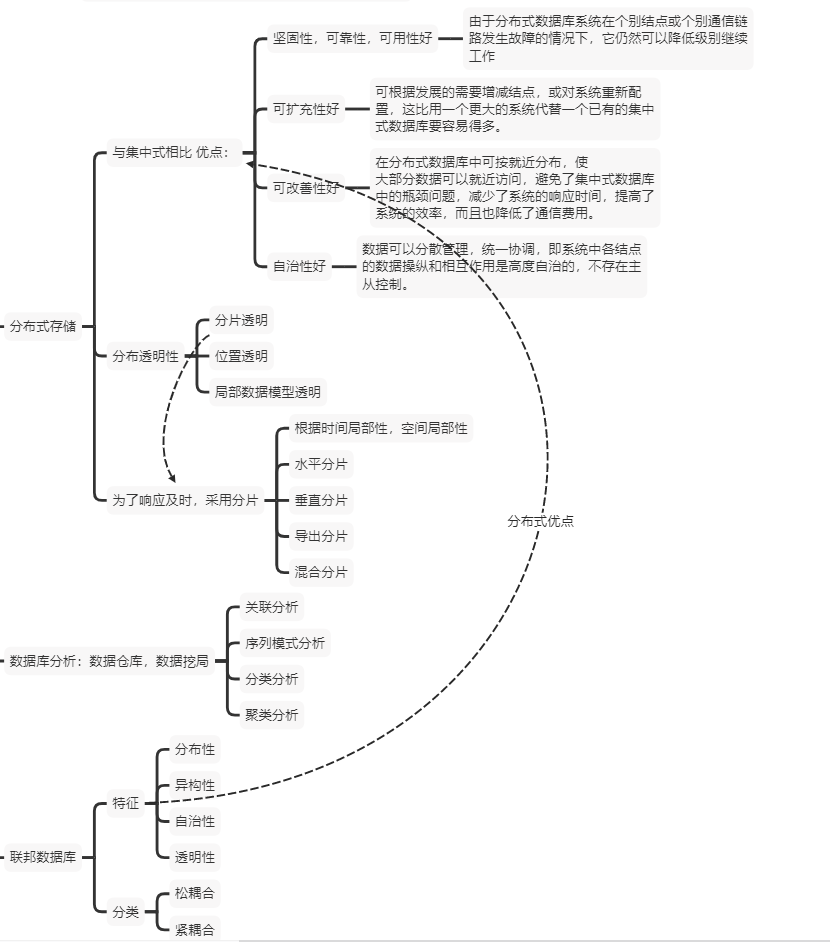
分布式数据库系统
分布透明性
- ·分片透明性:分不分片,用户感受不到
- ·位置透明性:数据存放在哪里,用户不用管
- ·局部数据模型透明性(逻辑透明):用户不用关系局部数据模型
分布式数据库管理系统-组成
- ·LDBMS
- ·GDBMS
- ·全局数据字典
- ·通信管理(CM)
分布式数据库管理系统-结构
- ·全局控制集中的DDBMS
- ·全局控制分散的DDBMS
- ·全局控制部分分散的DDBMS
数据仓库与数据挖掘
关联分析:关联分析主要用于发现不同事件之间的关联性,即一个事件发生的同时,另一个事件也经常发生。关联分析的重点在于快速发现那些有实用价值的关联发生的事件。其主要依据是事件发生的概率和条件概率应该符合一定的统计意义。在进行关联分析的同时,还需要计算两个参数,分别是最小置信度(可信度)和最小支持度,前者表示规则需满足的最低可靠度,用以过滤掉可能性过小的规则;后者则用来表示规则在统计意义上需满足的最小程度。
序列模式分析:序列分析主要用于发现一定时间间隔内接连发生的事件,这些事件构成一个序列,发现的序列应该具有普遍意义,其依据除了统计上的概率之外,还要加上时间的约束。在进行序列分析时,也应计算置信度和支持度。
分类分析:分类分析通过分析具有类别的样本特点,得到决定样本属于各种类别的规则或方法。利用这些规则和方法对未知类别的样本分类时应该具有一定的准确度。其主要方法有基于统计学的贝叶斯方法、神经网络方法、决策树方法等。分类分析时首先为每个记录赋予一个标记(一组具有不同特征的类别),即按标记分类记录,然后检查这些标定的记录,描述出这些记录的特征。这些描述可能是显式的,例如,一组规则定义;也可能是隐式的,例如,一个数学模型或公式。
聚类分析:聚类分析是根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,并且对每个这样的组进行描述的过程。其主要依据是聚集到同一个组中的样本应该彼此相似,而属于不同组的样本应该足够不相似。聚类分析法是分类分析法的逆过程,它的输入集是一组未标定的记录,即输入的记录没有作任何处理,目的是根据一定的规则,合理地划分记录集合,并用显式或隐式的方法描述不同的类别。在实际应用的DM系统中,上述四种分析方法有着不同的适用范围,因此经常被综合运用。
数据预处理是整合企业原始数据的第一步,它包括数据的抽取(extraction)、转换(transformation)和加载(load)三个过程(ETL过程)。
建立数据仓库则是处理海量数据的基础;数据分析是体现系统智能的关键,一般采用联机分析处理OLAP和数据挖掘两大技术。
联邦数据库
联邦数据库系统(FDBS)是一个彼此协作却又相互独立的成员数据库(CDBS)的集合,它将成员数据库系统按不同程度进行集成,对该系统整体提供控制和协同操作的软件叫做联邦数据库管理系统(FDBMS)
联邦数据库特征
- ·分布性
- ·异构性
- ·自治性
- ·透明性
联邦数据库分类
- ·紧耦合
- ·松耦合
NoSQL
一般关系数据库模式:
- 支持并发、效率低
- 关系表方式存储、SQL查询
- 向上扩展
- B树、哈希等
- 面向通用领域
NoSQL模式:
- 并发性能高
- 海量数据存储、查询效率高
- 向外扩展
- 键值索引
- 特定应用领域

 浙公网安备 33010602011771号
浙公网安备 33010602011771号