

漫谈可视化Prefuse(六)
可视化一路走来,体会很多;博客一路写来,收获颇丰;代码一路码来,思路越来越清晰。终究还是明白了一句古话:纸上得来终觉浅,绝知此事要躬行。
跌跌撞撞整合了个可视化小tool,零零碎碎结交了众多的志同道合之人,迷迷糊糊创建了我"可视化/Prefuse"的QQ群,详情可查看左侧的公告部分。此群旨在结实更多的可视化领域的同仁,也希望可以成为一个开源项目分享与阅读的平台。源于开源,开源为我们提供了助我们快速成长的养分,开源的每一行代码都是前辈们心血的结晶,开源是智慧的浓缩。
在博客园写博客也是如此,从起初只是一味的平铺直叙,直抒胸臆,从来没有估计到还要格式调整,也没有想到要布局美观,更不用提什么言简意赅、一针见血。总之,看看优秀的博客,就如同接触到一个开源项目,其开篇布局、文章内容、文本样式都是学习的教材。最近体会比较深的就是:写博客也体现出博客的特性,博客,不是论文,过多或者过于复杂的理论阐述(除非必不可少)会让大部分读者两眼昏花、四肢无力;博客,也不是小学造句子,过短或过少缺乏整体的连贯性,刚读起来有点感觉,好吧,还没高潮就结束了,让人摸不着头脑。所以,我发现,但凡获得点赞多的文章除了内容含金量高以外,还赢在表述以及篇幅的控制,真正站在Reader的角度去阐述问题、解决问题,Reader就会控制不住要点个赞。In a Word,路很长,要学的东西很多,慢慢体味。
上期回顾:《漫谈可视化Prefuse(五)---一款属于我自己的可视化工具》主要介绍了自己开发的一款可视化工具,包含了可视化工具中一些必不可少的功能,有些网友反应期待web版,其实Prefuse是支持applet版本的,这里没有走web的原因可能还是根据我们的需求走。要知道在以js为坚实后盾的各种可视化库大行其道的情况下,类似于Gephi、IBM i2等产品仍然具有不可撼动的地位的原因,在于需求催生产品,不同的需求就会对应着不同的产品形态。还有些网友反映披露工具相关细节,下面正文将会有所体现。
本篇主要立足于Prefuse框架讲述:1.可视化工具如何根据需求调整边的粗细;2.try...catch的巧用
1.如何通过边的粗细来反映边的权重
Prefuse框架默认边的粗细是统一的,都为1。但是我们往往面临的需求是给出数据格式如下
| Source | Target | Weight |
| 1 | 2 | 0.5 |
那么我们就可以通过边的粗细来体现这个Weight属性,用来表明节点1和节点2之间的亲密程度。
所以,我们针对Prefuse的源码做一下改动,在此之前,我们先了解有关类的继承关系:
类LabelRenderer:
|
1
2
3
4
5
6
7
8
9
10
|
public class LabelRenderer extends AbstractShapeRenderer { ...... public void render(Graphics2D g, VisualItem item) { RectangularShape shape = (RectangularShape) getShape(item); if (shape == null) return; ...... } ...... } |
类EdgeRenderer:
|
1
2
3
4
5
6
7
8
9
|
public class EdgeRenderer extends AbstractShapeRenderer { ...... public void render(Graphics2D g, VisualItem item) { // render the edge line super.render(g, item); ...... } ......} |
抽象类AbstractShapeRenderer:
|
1
2
3
4
5
6
7
8
|
public abstract class AbstractShapeRenderer implements Renderer { ...... public void render(Graphics2D g, VisualItem item) { Shape shape = getShape(item); ...... } ......} |
从以上三个类可以发现,类LabelRenderer和EdgeRenderer都是继承自抽象类AbstractShapeRenderer,并且LabelRenderer和EdgeRenderer类都覆写了父类 render方法。
两个类的render方法的最大不同之处在于,EdgeRenderer类显式调用了抽象父类AbstractShapeRenderer的render方法,并且通过在AbstractShapeRenderer类的render方法中加入:
| 1 | System.out.println("该item属于:" + item.getGroup()) |
得到的打印信息都是"该item属于:graph.edges",即表明都是对于边的渲染。
了解了类的继承关系,下面给出修改源码的步骤以实现通过配置文件实现边粗细的赋值:
(1)在PrefuseConfig类中添加:
| 1 | setProperty("data.edge.weight", "weight"); |
用于xml文件中确定边粗细的标示,这里是weight;
(2)在Graph类中添加:
| 1 | public static final String WEIGHT = PrefuseConfig.get("data.edge.weight"); |
用于在GraphMLReader获取常量;
(3)在GraphMLReader中添加:
|
1
2
|
public static final String WEIGHT = Graph.WEIGHT;public static final String WEIGHTID = WEIGHT + '_' + ID; |
方法startDocument()中添加:
|
1
2
|
m_esch.addColumn(WEIGHT, String.class);//边粗细相关m_esch.addColumn(WEIGHTID, String.class); |
方法startElement()中添加:
|
1
2
|
m_edges.setString(m_row, WEIGHT, atts.getValue(WEIGHT));m_edges.setString(m_row, WEIGHTID, atts.getValue(WEIGHTID)); |
(4)在AbstractShapeRenderer中添加:
|
1
2
3
4
5
6
7
8
9
10
|
EdgeItem edge = (EdgeItem)item;VisualItem vi = (VisualItem)edge.getSourceNode();item.setStrokeColor(vi.getFillColor());String weight = null;try { weight = item.get(GraphMLHandler.WEIGHT).toString(); } catch (Exception e) { weight = "1";}item.setSize(Double.parseDouble(weight)*10); |
使用的配置文件为xml格式,内容为:
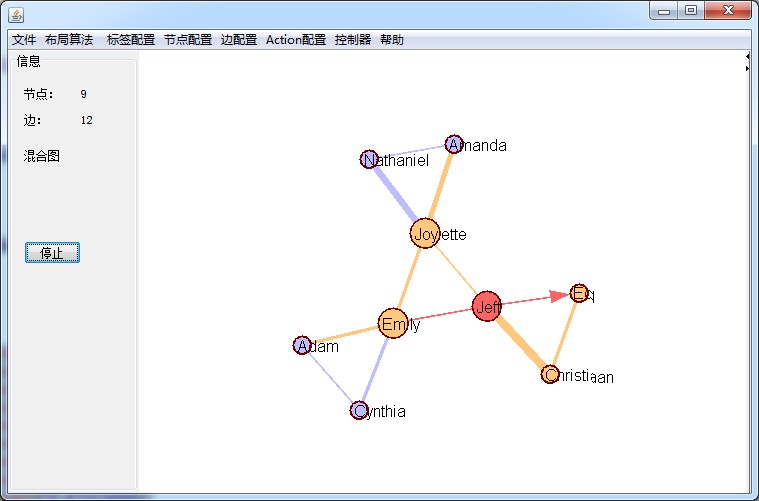
最终的图形显示为:
2.try....catch的巧用
巧用之处见1(4)中所写:
|
1
2
3
4
5
6
7
8
9
10
|
EdgeItem edge = (EdgeItem)item;VisualItem vi = (VisualItem)edge.getSourceNode();item.setStrokeColor(vi.getFillColor());String weight = null;try { weight = item.get(GraphMLHandler.WEIGHT).toString(); } catch (Exception e) { weight = "1";}item.setSize(Double.parseDouble(weight)*10); |
因为在实际情况中,会遇到有些xml文件中没有weight属性,或者xml部分边有部分没有的情况,这时就会面临在AbstractShapeRenderer中无法获取weight值的情形,即
| 1 | item.get(GraphMLHandler.WEIGHT) |
此值不存在或为空,起初通过添加语句:
|
1
2
3
4
5
|
if(item.get(GraphMLHandler.WEIGHT).toString().equals("") || item.get(GraphMLHandler.WEIGHT).toString() == null){ weight = "1";}else{ weight = item.get(GraphMLHandler.WEIGHT).toString();} |
等类似手段还是无法捕获item.get()取不到值的所有情况,后面转而想到,鉴于要捕获的是为空异常,索性使用try...catch直接进行捕获,捕获后在进行处理。从而有了上面的处理,即当item.get()函数获取不到值时就捕获异常,转入catch部分执行,在这里我们编写我们想要实现的功能,也就是获取为空时就将weight设置默认值为1,从而巧妙的解决了考虑所有为空的情况。
从该源码的经历发现,需要明确自己想要的功能,明确需要触及哪些类,明确如何保证修改后的源码运行的完整性,不能因为修改一处而到处报错;另外,还需要经常思考,灵活运行一些语句的特性为自己所用。今天就到这吧,如果觉得有用,记得点赞^_^,对可视化(gephi、prefuse、分布式计算、开源)感兴趣的可以加群讨论。
本文链接:《漫谈可视化Prefuse(六)---改动源码定制边粗细》
友情赞助
如果你觉得博主的文章对你那么一点小帮助,恰巧你又有想打赏博主的小冲动,那么事不宜迟,赶紧扫一扫,小额地赞助下,攒个奶粉钱,也是让博主有动力继续努力,写出更好的文章^^。
1. 支付宝 2. 微信



