
HOI生成——InterFusion
InterFusion
快速阅读
提供了一个2stage的HOI(human-object interations)生成策略。输入为text prompt,输出为HOI的mesh。第一阶段进行人体姿态生成,通过text生成对应的人体mesh,并作为anchor送入第二阶段。第二阶段分为整体生成和局部生成,在局部上把之前的anchor作为条件,对人体和物体进行分别生成与优化。在整体上以综合描述作为指导,并与 SDS-H 和 SDS-O 共同优化
Method
Stage 1 人体anchor生成:
-
利用 ChatGPT 生成有关人类日常事件或动作的prompt,形成 "verb-ing a/an/the object"结构。共生成了 235 条提示结果,涵盖了日常生活中的大多数互动。
-
使用预先训练好的 PIXIE 模型估算三维人类姿势,从而创建了一个由总计 55K 个三维伪 SMPL 姿势组成的综合 Syn-HOI 姿势数据集。
-
我们从多个视角渲染SMPL产生的图像,并使用 CLIP 的encoder得出姿势特征embdding。
-
将数据集,CLIP embedding means和姿势参数对连接起来。
-
进一步使用 KMeans 聚类技术构建了一个代码集,其中每个聚类包括一个姿势子集,代表了与中心点关键姿势相似的姿势。
-
选取k = 7 作为合适的姿势,然后,我们利用 GPT-4V 选择最精确的姿势作为最终查询的关键姿势。也可以在聚类中根据需求选择姿势作为anchor进行HOI生成。
-
为了限制使用从获取的姿态中获得的人体结构先验来优化几何形状和外观,进一步引入了COAP,该网络将3D查询点p映射到占用值,直接指示空间点是否位于3D身体内。
- 确定每个身体部分的位置
- 对生成进行约束?
Stage2:人体渲染优化+物体生成
- 将anchor与输入文本一起使用以引导生成详细的三维HOI场景。对于人类模型,它建立了一个基本的几何结构,对于对象模型,则定义了应保持未占用的区域。
- 对文本进行识别,从而使其对不同的组件(human/obj)都能够产生语义指导,通过DeepFloyd模型[6]产生
- 引入了相机追踪模块,在不同文本条件下增强优化过程调整相机姿态,对每个场景方面进行最佳渲染。
人类渲染部分
有个和graphi不同的地方,这里是mesh作为条件,使用H_nerf直接生成人体姿态。graphi是抠出了人体姿态之后在上方进行纹理生成
-
优化头部区域
-
确定头部位置(COAP)
-
为头部区域特别增加文本提示 the head of从而对头部进行特别的渲染
训练的损失函数如下,用来对头部进行关注,并且平衡与整个人体姿态的风格
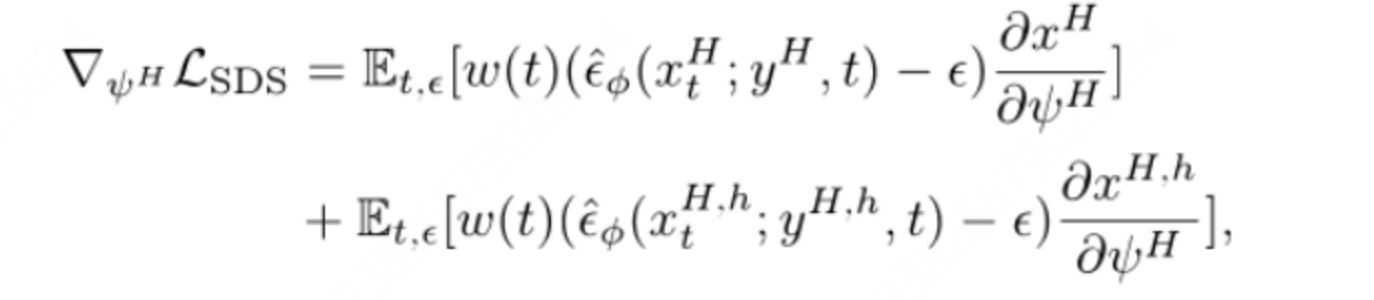
-
-
人体mesh生成
在生成时,anchor作为条件,anchor外的点也可以被占用,但随着它们远离锚点表面而概率逐渐降低。这种方法允许在锚点上添加几何细节,以确保模型与文本中描述的人类风格保持一致,并且结构根植于锚定姿势。使用的损失函数如下(可以进行身体的生成,为何不直接进行空mesh的生成,之后再渲染类似于3stage?)
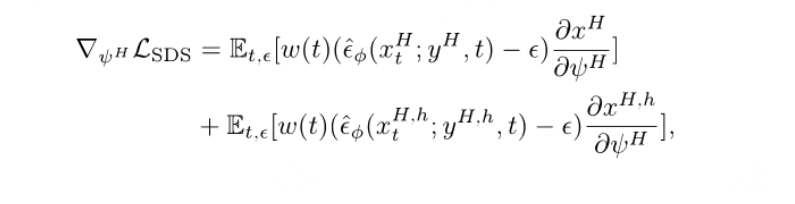
-
Object生成
Nerf生成obj
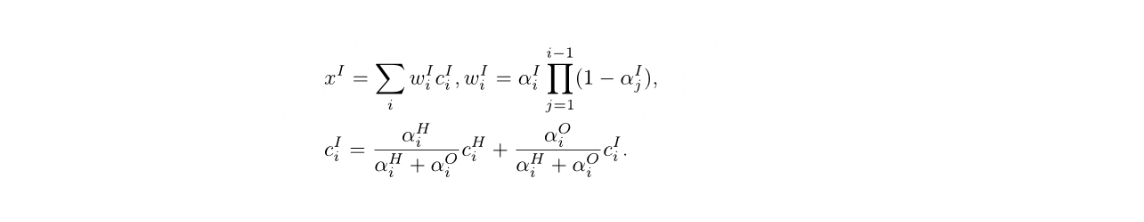
-
整体渲染
通过alpha混合渲染来整合H-NeRF和O-NeRF。alpha方法从每个点的密度计算出一个alpha值,并确定其对场景颜色的贡献。更高的alpha值表示更大的渲染影响。

