

Mysql:实现中位数算法
本次文章目的:
Mysql并没有专门的中位数算法,而对于SQL不熟悉的人,书写中位数,只能通过JAVA等语言实现。
并非推荐使用Mysql完成中位数计算,以下实现,仅为了通过算法解析的过程中,了解一些Mysql常用与不常用的功能、函数,并开拓思维。
当然,对于一些临时性的要求,需要制作一些临时性的算法测试、校验、导出, 能使用Mysql完成这类算法,就凸显出其效率。
说到中位数,我们就需要一批数据来进行测试和实现,创建如下表:
DROP TABLE IF EXISTS CaseRent; CREATE TABLE CaseRent( ID int(6) NOT NULL AUTO_INCREMENT, ResidentialAreaID int(6) DEFAULT NULL, CaseFrom varchar(30) DEFAULT NULL, Price int(6) DEFAULT NULL, PRIMARY KEY (ID) );
称之为出租案例表,关键字段有:小区ID、案例来源及价格。
接下来通过随机数来给出租案例表赋值:
INSERT INTO CaseRent (ResidentialAreaID, CaseFrom ,Price) SELECT ROUND((RAND()*100)+1),'链家在线',ROUND((RAND()*8000)+1000)
该语句包含知识点如下:
- 通过 INSERT INTO ... SELECT 进行赋值(用途广泛,创建表亦可以使用)
- 运用Rand() 随机数函数,ROUND() 四舍五入函数,完成小区ID从0~100 ,价格从1000~9000的随机录入。
一条数据当然不够,我们可以使劲的多点几下执行,使数据增加到近10条。这时候我们修改一下赋值语句
INSERT INTO CaseRent (ResidentialAreaID, CaseFrom ,Price) SELECT ROUND((RAND()*100)+1),'链家在线',ROUND((RAND()*8000)+1000) FROM CaseRent
继续反复来N下,之后将来源“链家在线”修改为“房天下”,进行一次赋值。
INSERT INTO CaseRent (ResidentialAreaID, CaseFrom ,Price) SELECT ROUND((RAND()*100)+1),'房天下',ROUND((RAND()*8000)+1000) FROM CaseRent
模拟数据到此完成!示例如下:
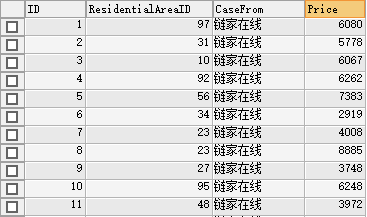
实际上,网上的中位数花式百出,但无一不是:代码篇幅长、需要自我关联 或者 使用上临时变量。
当然也有类似我们接下来要讲的方式。无论哪种方式,都需要更多的了解和扩展自己所知。
接下来以刚才我们自定义的模拟数据为例子,安排第一个问题:
- 查找小区ID = 99 的价格中位数
这类的中位数,可以说是最简单的,而且网上大部分中位数,均针对此类中位数(单条件),从上述网站就可以看到,其问题与我们的类似,但其代码量可谓不少。
我们来分析问题:其获取价格中位数,就必须使用ORDER BY 来实现排序,排序后,统计总条数,来获取中间一条的价格作为结果(如果为偶数,可以取2条均值,亦可以取前一条 例如 6条数据,可以取第3、4 条进行均值计算,这里以取前一条为算法模拟)
那么第一步,无疑是要进行价格从小到大的排序:
SELECT * FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY Price
排序之后,ID显的杂乱无章,关如此,我们人为的话,只能去手动数条数进行查找, 因此我们需要拥有一个新的自增ID,以此来更快的得知其对应的排名。
如何得到新的自增ID呢? 我们可以新建一张表, 通过INSERT INTO ...SELECT 来完成新数据的录入,以此达到数据的ID自增:例如:
INSERT INTO NewCaseRent(ResidentialAreaID,CaseFrom,Price) SELECT ResidentialAreaID,CaseFrom,Price FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY Price
不过这样我们就需要建表了,这就显的很麻烦,因为一个自增,而新建一张表,入不敷出,
那么我们就需要一个变量,来实现自增功能。
同JAVA/Python等开发语言一样,Mysql也有变量,通常以@开头为用户自定义变量,以@@开头为系统变量。
那么我们怎么使用变量?很简单,通过SET创建并赋值变量值, 再通过SELECT查询结果,例如:
SET @ID = 0; SELECT @ID;
有了变量,我们可以将变量作为新的自增ID,来代替创建一张新表的操作了,
通过变量自加操作,完成新的自增ID功能:
SET @ID = 0; SELECT @ID:=@ID+1 AS ID,ResidentialAreaID,CaseFrom,Price FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY Price
注意几点:
- 在SELECT中,给临时变量赋值,使用 :=
- 每条语句,从底层讲,都是循环查询,因此在语句上直接自增,就可以实现逐条累加。
当然,上面的语句其实是2条语句,这样放到JAVA或者其他语言中执行,可能不方便,因此也可以修改成如下语句:
SELECT @ID:=@ID+1 AS ID,ResidentialAreaID,CaseFrom,Price FROM CaseRent,(SELECT @ID:=0) b WHERE ResidentialAreaID = 99 ORDER BY Price
结果示例:
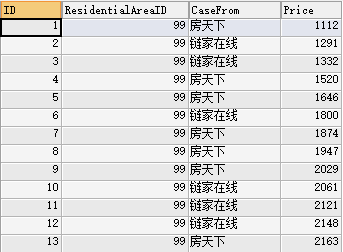
效果很好,接下来我们要做的,就是获取ID=总条数/2 的那条数据了。
思考一下,如何才能简单的得到结果?
SELECT * FROM ( SELECT @ID:=@ID+1 AS ID,ResidentialAreaID,CaseFrom,Price FROM CaseRent,(SELECT @ID:=0) b WHERE ResidentialAreaID = 99 ORDER BY Price ) a WHERE ID = @ID/2
通过简单的中位数选取,深刻认知Mysql临时变量的用法。
接下来引入加深层次的中位数:
- 根据案例来源,分别统计不同来源,小区ID=99的中位数。
分析问题:比第一步多了一个条件,其结果也多了一条数据。
那么该怎么做呢?
我们知道,排序的时候,需要按照 案例来源、价格 2个条件进行排序了,如果直接自增ID, 会是什么样的呢?
SELECT @ID:=@ID+1 AS ID,ResidentialAreaID,CaseFrom,Price FROM CaseRent,(SELECT @ID:=0) b WHERE ResidentialAreaID = 99 ORDER BY CaseFrom,Price
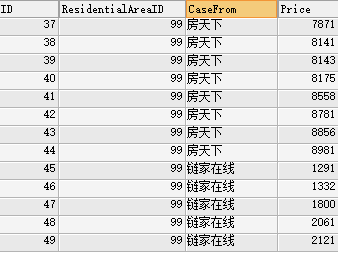
很明显,如果想要实现真确的自增ID, 到了链家在线这一步,ID需要重新从1开始计算。
那么难道我们分成2次统计? 如果案例来源有N个,这个方式明显不行。
接下来引入Mysql函数 IF
IF ( 条件 , 真 , 假 )
为什么引入IF? 我们需要判断排序后自增的时候,案例来源是否和上次的一样,如果不一样 说明切换到了新来源,这时候将@ID设置为从1开始,就可以实现2个来源不同的自增ID。
要判断来源是否一样,我们还得加个临时变量 @CaseFrom
SET @ID:=0,@CaseFrom=''; SELECT IF(@CaseFrom!=CaseFrom,@ID:=1,@ID:=@ID+1) AS ID,ResidentialAreaID,CaseFrom,Price, @CaseFrom:=CaseFrom wy FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY CaseFrom,Price;
这里的wy字段,就纯粹是为了赋值CaseFrom。对其他操作无用。
结果如下:
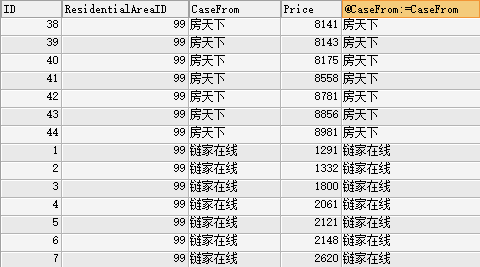
但是问题来了。 @ID已经不能直接用来 判断Count(*)/2了 。 因为@ID 已经是链家在线的ID,而不是房天下的。
通过创建临时表:临时完美通俗的解决该问题:
临时表Temporary只在当前会话使用,其余会话创建相同名称临时表,不互相冲突,不直接生成实体表。
但临时表不能自我关联。
SET @ID:=0,@CaseFrom=''; DROP TABLE IF EXISTS CS_1; CREATE TEMPORARY TABLE CS_1 SELECT IF(@CaseFrom!=CaseFrom,@ID:=1,@ID:=@ID+1) AS ID,ResidentialAreaID,CaseFrom,Price,@CaseFrom:=CaseFrom wy FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY CaseFrom,Price; DROP TABLE IF EXISTS CS_2; CREATE TEMPORARY TABLE CS_2 SELECT CaseFrom,FLOOR(Max(ID)/2) CenterID FROM CS_1 GROUP BY CaseFrom; SELECT * FROM CS_1 a INNER JOIN CS_2 b ON a.ID = b.CenterID AND a.CaseFrom=b.CaseFrom;
这就显的拖沓了,写了这么多代码,创建了2张临时表,关联后获取结果。 不过只是相对而言, 对于一些临时性的操作,计算、导出的时候,就算是python编写个脚本,其代码量也远远大于这些。
上述方式,通过临时表 + IF 的方式,实现了多层次的中位数获取。但是我们知道,通过IF判断,意味着我如果添加新的层次,例如:
- 获取每一个小区、每一个来源的中位数。
这样我们就得增加一个小区ID的临时变量,不仅案例来源改变,需要重置ID为1, 小区ID改变时,也要重置为1, 这样的代码如下:
SET @ID:=0,@CaseFrom='',@ResidentialAreaID=0; DROP TABLE IF EXISTS CS_1; CREATE TEMPORARY TABLE CS_1 SELECT IF(@CaseFrom!=CaseFrom,@ID:=1,@ID:=@ID+1) AS ID, IF(@ResidentialAreaID!=ResidentialAreaID,@ID:=1,1) AS ID2, ResidentialAreaID,CaseFrom,Price,@CaseFrom:=CaseFrom wy,@ResidentialAreaID:=ResidentialAreaID wy2 FROM CaseRent ORDER BY ResidentialAreaID,CaseFrom,Price; DROP TABLE IF EXISTS CS_2; CREATE TEMPORARY TABLE CS_2 SELECT ResidentialAreaID,CaseFrom,FLOOR(Max(ID)/2) CenterID FROM CS_1 GROUP BY ResidentialAreaID,CaseFrom; SELECT * FROM CS_1 a INNER JOIN CS_2 b ON a.ID = b.CenterID AND a.CaseFrom=b.CaseFrom AND a.ResidentialAreaID=b.ResidentialAreaID;
多了一个IF判断,多了一个临时变量,多关联了一个字段。
这对熟悉并了解该逻辑的人来说并没有增加多少代码量,但其多了一层逻辑,需要了解,这就可能照成混淆。
看上去很多,其实相较于其他方式,已经很精简了,不过还没完,我们还有很多方法可以尝试!
例如编写Mysql 自定义函数、存储过程来实现,不过这就有点偏离了。
接下来换一种方式实现。
通过 GROUP_CONCAT 和 SUBSTRING_INDEX实现中位数算法
Group_concat 一般不会太陌生,一般伴随着Group By 使用,当然也可以不实用Group by
通过Group_concat 可以将结果字段 默认通过 逗号 分割,组成一个新的字符串。
例如:
SELECT GROUP_CONCAT(Price) FROM CaseRent WHERE ResidentialAreaID = 99;
其结果如下:

而GROUP_CONCAT中,还可以写一些SQL代码。例如
GROUP_CONCAT( Price ORDER BY Price )
或者:
GROUP_CONCAT( DISTINCT Price )
是不是很方便,可以自行排序、剔除重复等操作,组成一个新的字符串。
再介绍另一个函数:SUBSTRING_INDEX
先看一下结果:
SELECT SUBSTRING_INDEX('一批,数,据',',',1)
= 一批
SELECT SUBSTRING_INDEX('一批,数,据',',',2)
= 一批,数
SELECT SUBSTRING_INDEX('一批,数,据',',',3)
= 一批,数,据
很明确了, 第一个参数放字符串,第二个为分割字符,第三个为取到第几个字符。
那就再说一个 -1 , -1 很常见,Redis、python 中 分割、查找字符经常使用,意为反向取值, 例如:
SELECT SUBSTRING_INDEX('一批,数,据',',',-1)
= 据
结合这两种函数的特性,就能完成中位数获取了。
我们来看一下:
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(Price ORDER BY Price),',',Count(1)/2),',',-1) zws FROM CaseRent WHERE ResidentialAreaID = 99;
以上涉及了2个函数, SUBSTRING_INDEX 以及 GROUP_CONCAT,
通过GROUP_CONCAT将结果排序后组成逗号分割的新字符串, 并通过SUBSTRING_INDEX, 获取到总量/2的结果,再通过SUBSTIRNG_INDEX -1的获取倒数第一个值,即为中位数结果。
那么如果加上案例来源获取中位数,这代码会变成什么样?
SELECT CaseFrom,SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(Price ORDER BY Price),',',Count(1)/2),',',-1) zws FROM CaseRent WHERE ResidentialAreaID = 99 Group By CaseFrom;
再加上区分小区呢?:
SELECT ResidentialAreaID,CaseFrom, SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(Price ORDER BY Price),',',Count(1)/2),',',-1) zws FROM CaseRent Group By ResidentialAreaID,CaseFrom;
似乎很简单,但是GROUP_CONCAT有个默认承载长度 1024
如果不修改参数的情况下,做大量数据的中位数统计,会超出GROUP_CONCAT的承载长度,导致计算错误。
而一般情况下,我们无法修改服务器的Mysql配参,可以通过:
show variables like 'group_concat_max_len'
来参考当前参数。
以及:
-- 以当前会话,临时修改GROUP_CONCAT支撑长度。
SET @@GROUP_CONCAT_MAX_LEN = 1024000;
当然,如果有必要,可以直接通知运维修改一下参数长度,如果不常用,可以自行使用这种方式修改后临时使用;因此数据量大的情况下,正确的写法如下:
SET @@GROUP_CONCAT_MAX_LEN = 1024000; SELECT ResidentialAreaID,CaseFrom, SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(Price ORDER BY Price),',',Count(1)/2),',',-1) zws FROM CaseRent Group By ResidentialAreaID,CaseFrom;
到此,中位数算法结束。
主要知识点:
临时变量
临时表
系统变量
IF
GROUP_CONCAT
SUBSTRING_INDEX
