

InnoDB学习(一)之BufferPool
我们知道InnoDB数据库的数据是持久化在磁盘上的,而磁盘的IO速度很慢,如果每次数据库访问都直接访问磁盘,显然严重影响数据库的性能。为了提升数据库的访问性能,InnoDB为数据库的数据增加了内存缓存区(BufferPool),避免每次访问数据库都进行磁盘IO。
缓存区BufferPool
缓存区并不是Innodb中特有的概念,操作系统中也有缓存区的概念,当用户第一次从磁盘读取文件时,会把文件缓存到内存中,后续再对这个文件进行读操作就可以直接从内存中读,从而减少磁盘IO次数。缓存只是内存中的一块连续空间,InnoDB是如何合理利用缓存区的空间的呢?本文会从以下几个方面介绍InnoDB的缓存区:
- 缓存区概览:InnoDB缓存区的结构和状态查询;
- 缓存区实例(BufferPool Instance):缓存区可以划分为多个实例;
- BufferChunk:缓存区实例内的数据块;
- 控制块和数据页:InnoDB是以什么形式缓存数据库中的数据的;
- 空闲空间管理;缓存区内的空闲空间管理逻辑;
- 用户数据管理:数据库数据和索引在缓存区缓存的管理;
- 自适应哈希索引:优化热点数据等值查询的哈希索引;
- ChangeBuffer简介:提高数据库更新效率的ChangeBuffer;
- 锁信息管理:InnoDB中的行锁信息也是存放在缓存区中的;
缓存区概览
InnoDB中的缓存区叫innodb_buffer_pool,当读取数据时,就会先从缓存中查看是否数据的页(page)存在,不存在的话去磁盘上检索,查到后缓存到innodb_buffer_pool中。同理,插入、修改、删除也是先操作缓存里数据,之后再以一定频率更新到磁盘上,这个刷盘机制叫做Checkpoint。
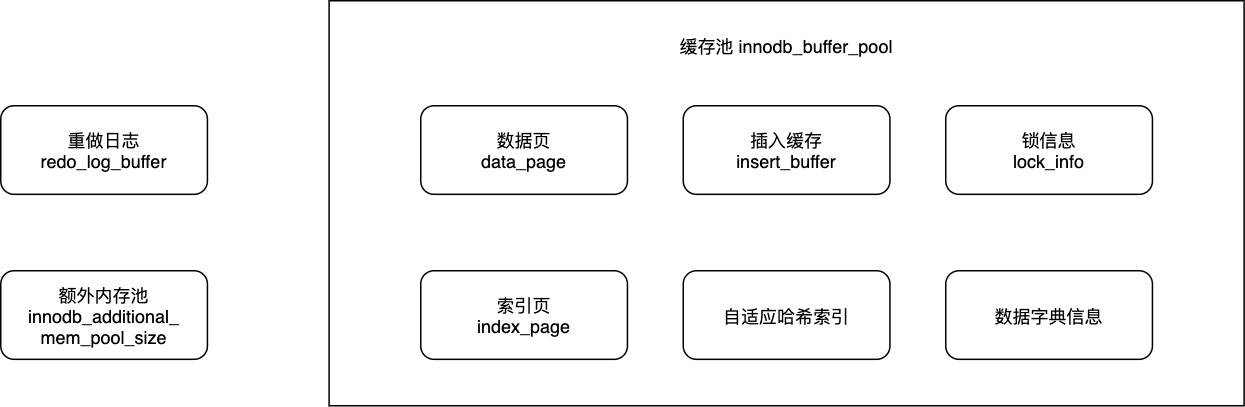
如下图所示,InnoDB中的数据主要有数据页、索引页、插入缓存、自适应哈希索引、锁信息和数据字典信息。我们经常听到的RedoLog不在缓存区中。
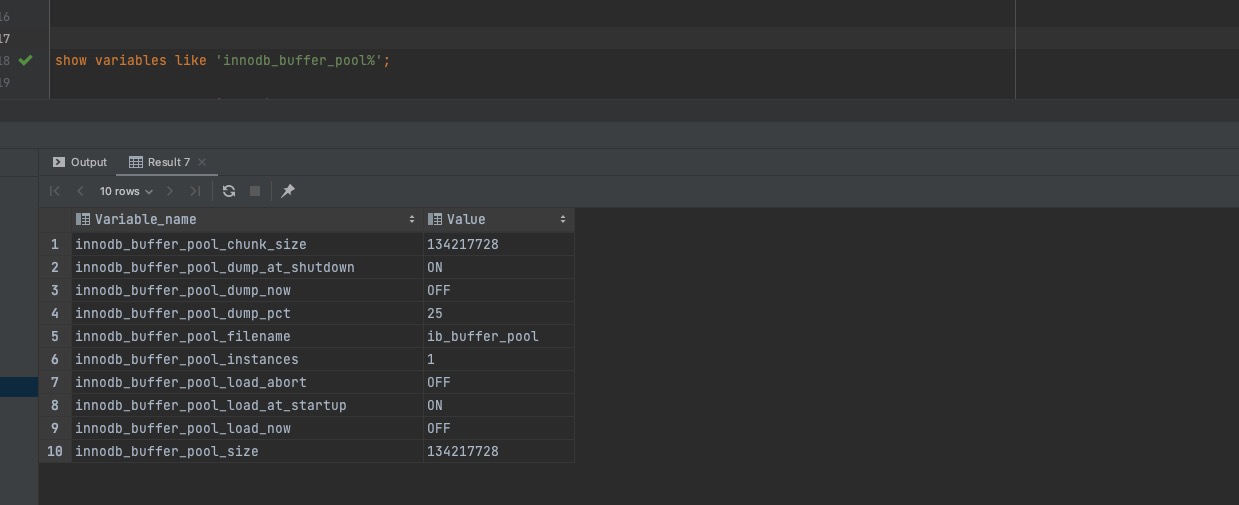
MySQL默认的innodb_buffer_pool的大小是128M,我们可以通过以下命令查看innodb_buffer_pool的参数,执行结果如下图所示:
show variables like 'innodb_buffer_pool%';
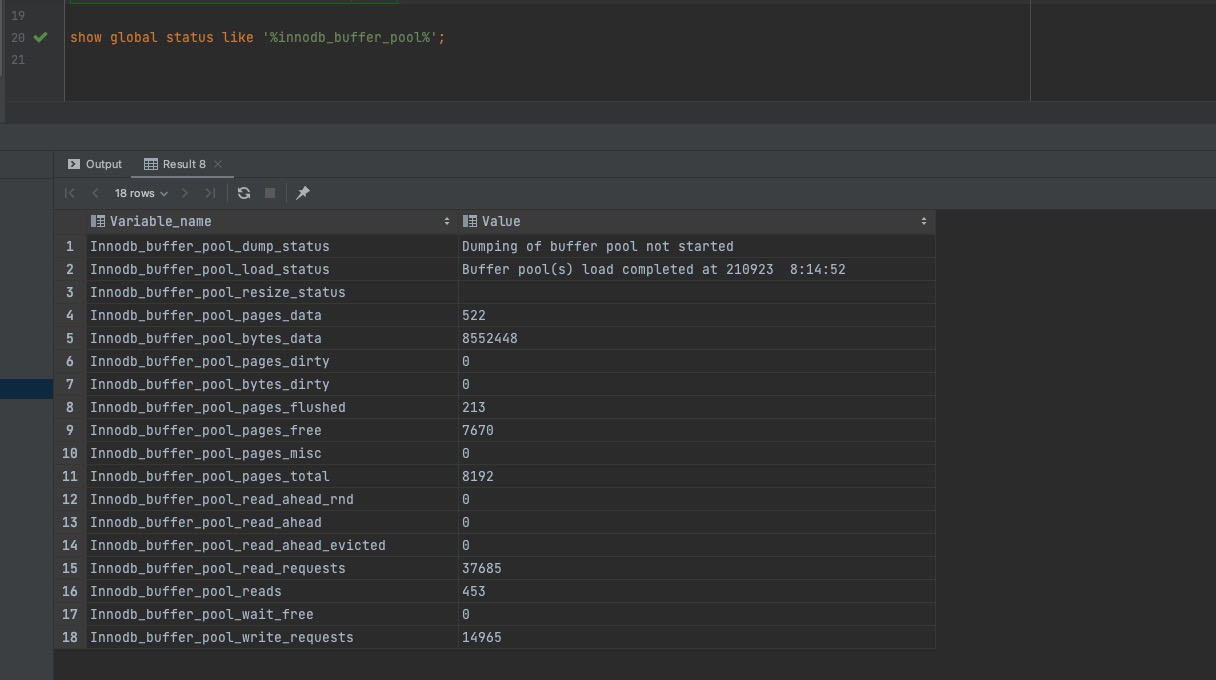
在MySQL使用过程中,我们可能需要查看缓存区的状态,比如已使用空间大小、脏页大小等状态,我们可以通过以下命令查看innodb_buffer_pool的状态,执行结果如下图所示,图中的执行结果中,共有8192页数据。
show global status like '%innodb_buffer_pool%';
缓存区实例
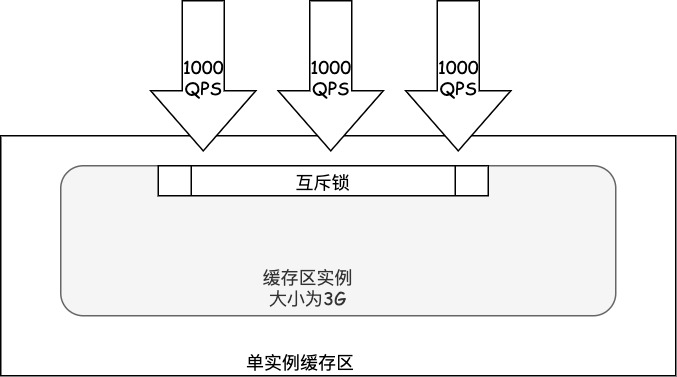
缓存区本身是一块内存空间,在多线程并发访问缓存的情况下,为了保证缓存页数据的正确性,可能会对缓存区单实例锁互斥访问,如果缓存区非常大并且多线程并发访问非常高的情况下,单实例缓存区的可能会影响请求的处理速度。如下图所示,数据库缓存区大小为3G,并发访问QPS为3000,如果缓存区只有一个实例,那么这3000个请求可能需要竞争同一个互斥锁。
MySQL 5.5引入了缓存区实例作为减小内部锁争用来提高MySQL吞吐量的手段,用户可以通过设置innodb_buffer_pool_instances参数来指定InnoDB缓存区实例的数目,默认缓存区实例的数目为1。缓存区实例的大小均为`innodb_buffer_pool_size/innodb_buffer_pool_instances。如下图所示,数据库缓存区大小为3G,并发访问QPS为3000,如果缓存区有3个实例,理想情况下最多每1000个请求会竞争同一个互斥锁。
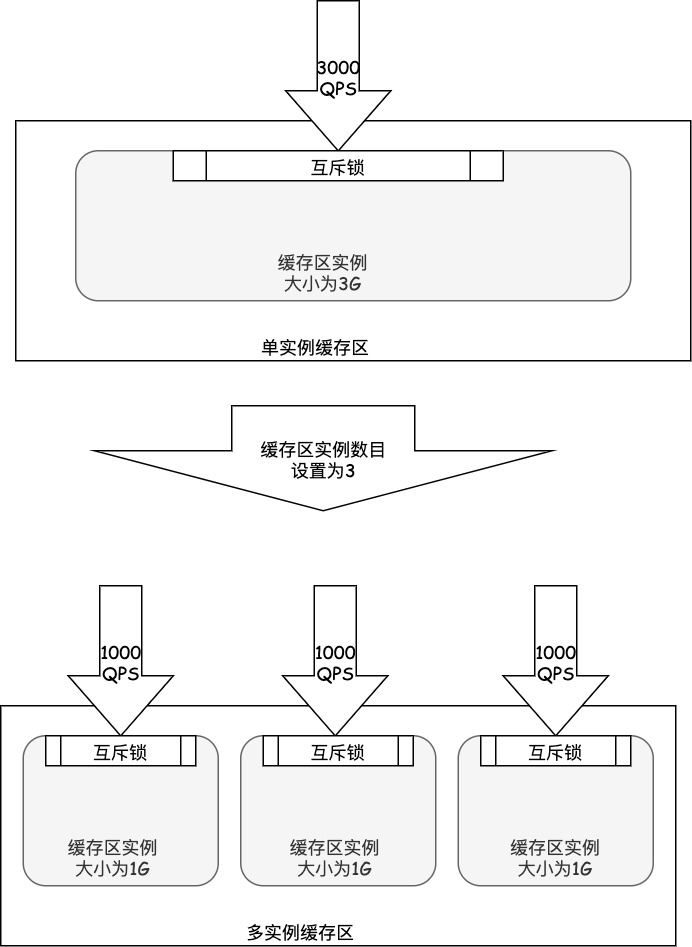
如果缓存区总空间大小小于1G,
innodb_buffer_pool_instances会被重置为1,因为小空间的多个缓存区实例反而会影响查询性能。
缓存区实例有以下特点:
- 缓存区实例有自己的锁/信号量/物理块/逻辑链表,缓存区实例之间没有锁竞争关系;
- 所有缓存区实例的空间在数据库启动时分配,数据库关闭后释放;
- 缓存页按照哈希函数随机分布到不同的缓存实例中;
缓存区实例的BufferChunk
我们知道缓存区可以包含多个缓存区实例,每个缓存区实例包含一块连续的内存空间,InnoDB把这块空间划分为多个BufferChunk,BufferChunk是InnoDB中的底层的物理块,BufferChunck中包含数据页和控制块两部分。
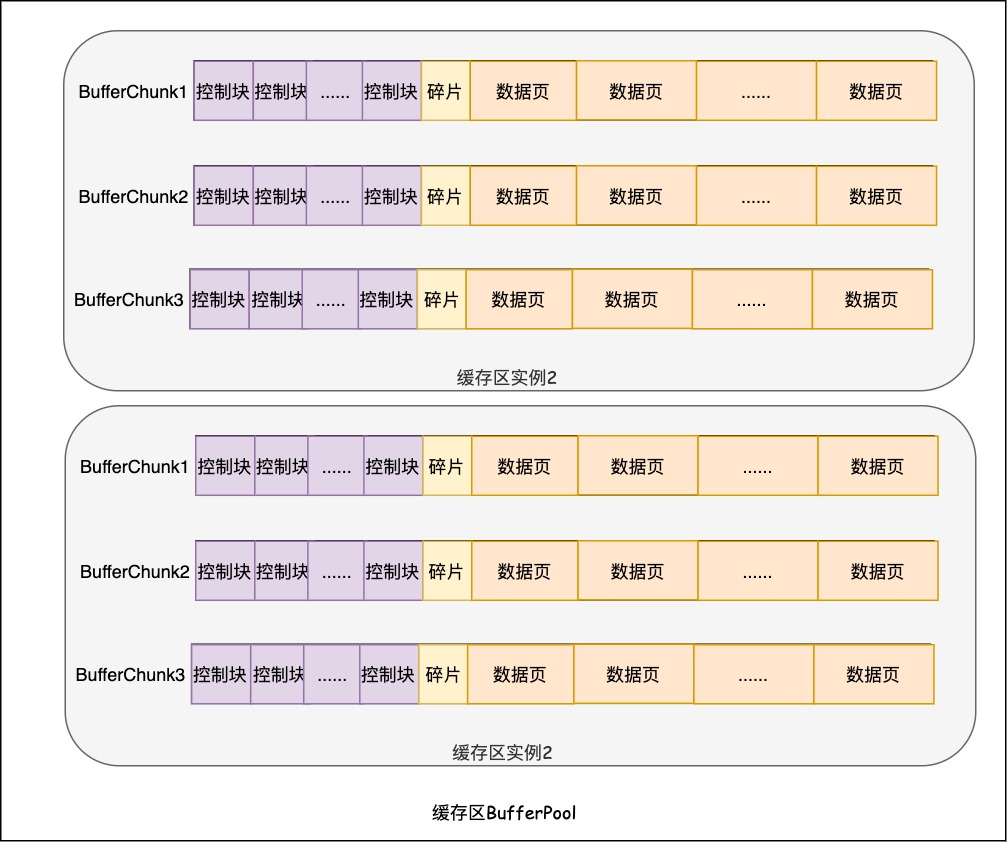
BufferChunk是最低层的物理块,在启动阶段从操作系统申请,直到数据库关闭才释放。通过遍历chunks可以访问几乎所有的数据页,有两种状态的数据页除外:
- 没有被解压的压缩页(BUF_BLOCK_ZIP_PAGE);
- 修改过且解压页已经被驱逐的压缩页(BUF_BLOCK_ZIP_DIRTY);
BufferChunck中包含数据页和控制块两部分,二者存放的数据如下:
- 控制块:页面管理信息/互斥锁/页面的状态等数据块控制信息;
- 数据页:数据库数据/锁数据/自适应哈希数据,数据页的大小默认为16K;
BufferChunck数据块的大小是可配置的,MySQL配置中默认BufferChunck数据块大小如下所示,用户可以在MySQL实例启动之前通过修改配置文件或启动参数中指定,达到自定义BufferChunck数据块的大小的目的。
$> mysqld --innodb-buffer-pool-chunk-size=134217728
[mysqld]
innodb_buffer_pool_chunk_size = 134217728
用户自定义
innodb_buffer_pool_chunk_size参数的大小应当小于单个缓存区实例的空间大小。如果innodb_buffer_pool_chunk_size值乘以innodb_buffer_pool_instances大于初始化缓冲池总大小时, innodb_buffer_pool_chunk_size则截断为innodb_buffer_pool_size/innodb_buffer_pool_instances。
控制块和数据页
通过上文,我们知道InnoDB中的底层物理块是BufferChunk,BufferChunk中包含了控制块和数据页,本节会介绍数据页和控制块分别包含哪些数据。
控制块
InnoDB中的每个数据页都有一个相对应的控制块,用于存储数据页的管理信息,但是这些信息不需要记录到磁盘,而是根据读入数据块在内存中的状态动态生成的。查找或者修改数据页时,总是会通过控制块进行数据块操作,控制块主要包含以下数据:
- 页面管理的普通信息/互斥锁/页面的状态等;
- 空闲链表/LRU链表/FLU链表等链表的管理;
- 按照一定的哈希函数快速定位数据页位置;
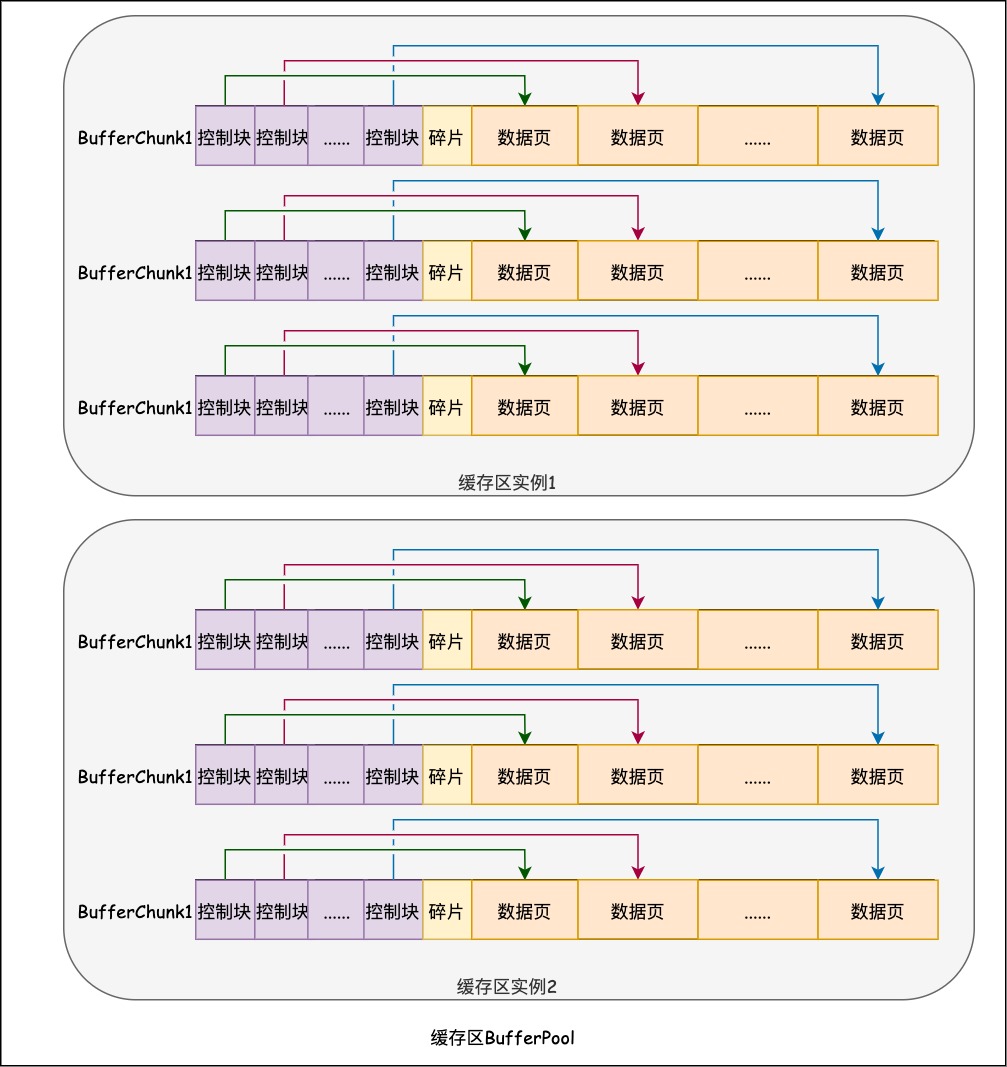
数据页
InnoDB中,数据管理的最小单位为页,默认是16KB,页中除了存储用户数据,还可以存储控制信息的数据。InnoDB IO子系统的读写最小单位也是页。如果对表进行了压缩,则对应的数据页称为压缩页,如果需要从压缩页中读取数据,则压缩页需要先解压,形成解压页,解压页为16KB。压缩页的大小是在建表的时候指定,目前支持16K,8K,4K,2K,1K。即使压缩页大小设为16K,在blob/varchar/text的类型中也有一定好处。假设指定的压缩页大小为4K,如果有个数据页无法被压缩到4K以下,则需要做B-tree分裂操作,这是一个比较耗时的操作。
数据页可以用于存放以下类型的数据,下文中我们会对这些类型的数据结构进行详细介绍:
- 用户数据,聚簇索引和非聚簇索引对应的节点数据;
- 行锁信息,InnoDB锁过多异常时,可以通过增加BufferPool大小解决;
- 自适应哈希,用于缓存热点数据;
- ChangeBuffer缓存;
空闲空间管理
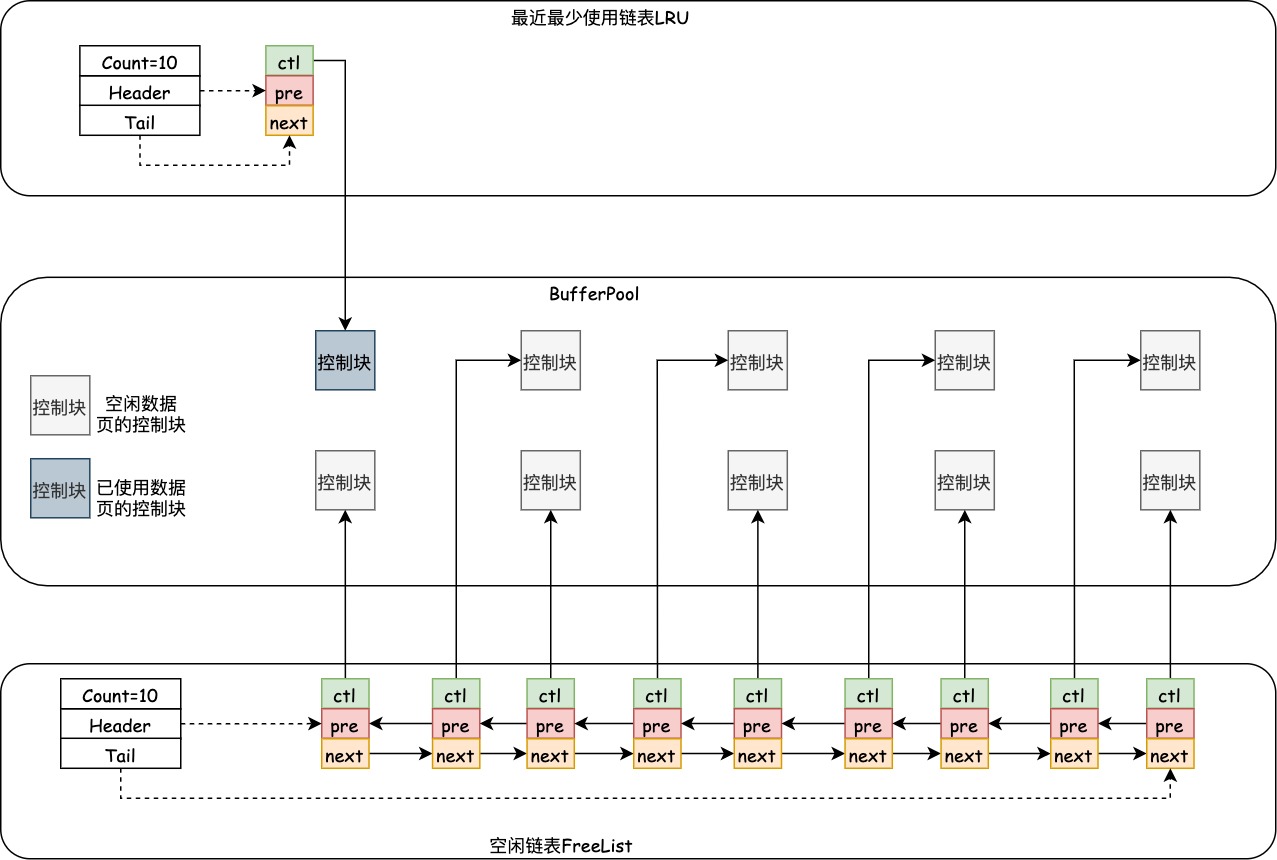
当我们最初启动服务器的时候,需要完成对的初始化过程,就是分配的内存空间,把它划分成若干对控制块和缓存页。但是此时并没有真实的磁盘页被缓存到中(因为还没有用到),之后随着程序的运行,会不断的有磁盘上的页被缓存到中,那么问题来了,从磁盘上读取一个页到中的时候该放到哪个缓存页的位置呢?或者说怎么区分中哪些缓存页是空闲的,哪些已经被使用了呢?我们最好在某个地方记录一下哪些页是可用的,我们可以把所有空闲的页包装成一个节点组成一个双向链表,这个链表也可以被称作(或者说空闲链表)。
如果InnoDB刚刚启动,缓存区的所有缓存页都是空闲的,每一个缓存页都会被加入到空闲链表中,此时空闲列表的结构如下所示(此处省略数据页,空闲链表的指针指向数据块的控制块)。
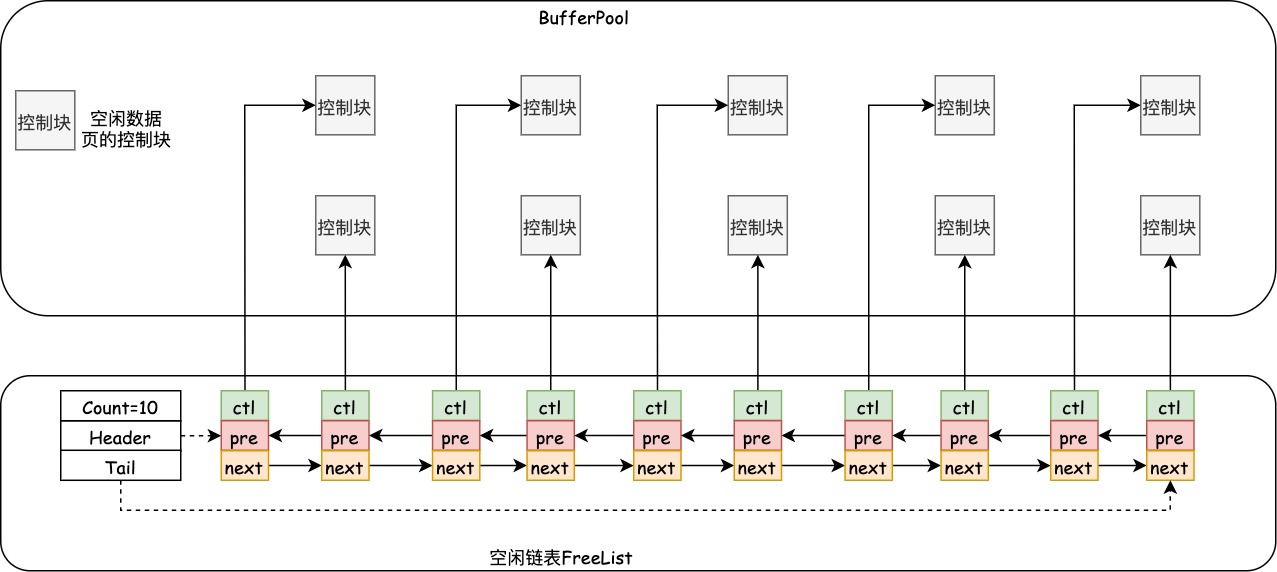
在需要加载缓存页到BufferPool的情况下,如果空闲链表不为空,我们可以从空闲链表中获取一页空闲数据页,将缓存放入空闲的数据页。以LRU(后文详细介绍)为例,InnoDB启动后,LRU加载第一个缓存页之后,BufferPool中的数据情况如下所示。
用户数据管理
用户数据管理是BufferPool中最重要的数据,包含表数据与索引数据等数据,用户数据会按照数据的状态进行管理,主要包含以下数据管理,下文会一一介绍这几种链表:
- 最近最少使用链表(Least Recently Used, LRU):InnoDB中最重要的链表,包含所有读取进来的数据页;
- 脏页链表(Flush LRU List):管理LRU中的脏页,后台线程定时写入磁盘;
- 解压页链表(Unzip LRU List):管理LRU中的解压页数据,解压页数据是从压缩页通过解压而来的;
- 压缩页链表(Zip List):顾名思义,对页数据压缩后组成的链表;
最近最少使用链表LRU
最近最少使用链表LRU用于缓存表数据与索引数据,由于内存大小通常远远小于磁盘大小,内存中无法缓存全部的数据库数据,所以缓存通常需要一定的淘汰策略,淘汰缓存中不经常使用的数据页。InnoDB的BufferPool采用了改进版的LRU的淘汰策略。
如下图所示,LRU链表的结构和空闲链表的结构类似,是一个双向链表,链表中的节点包含指向数据页控制块的指针,可以通过控制块访问数据页中的数据。
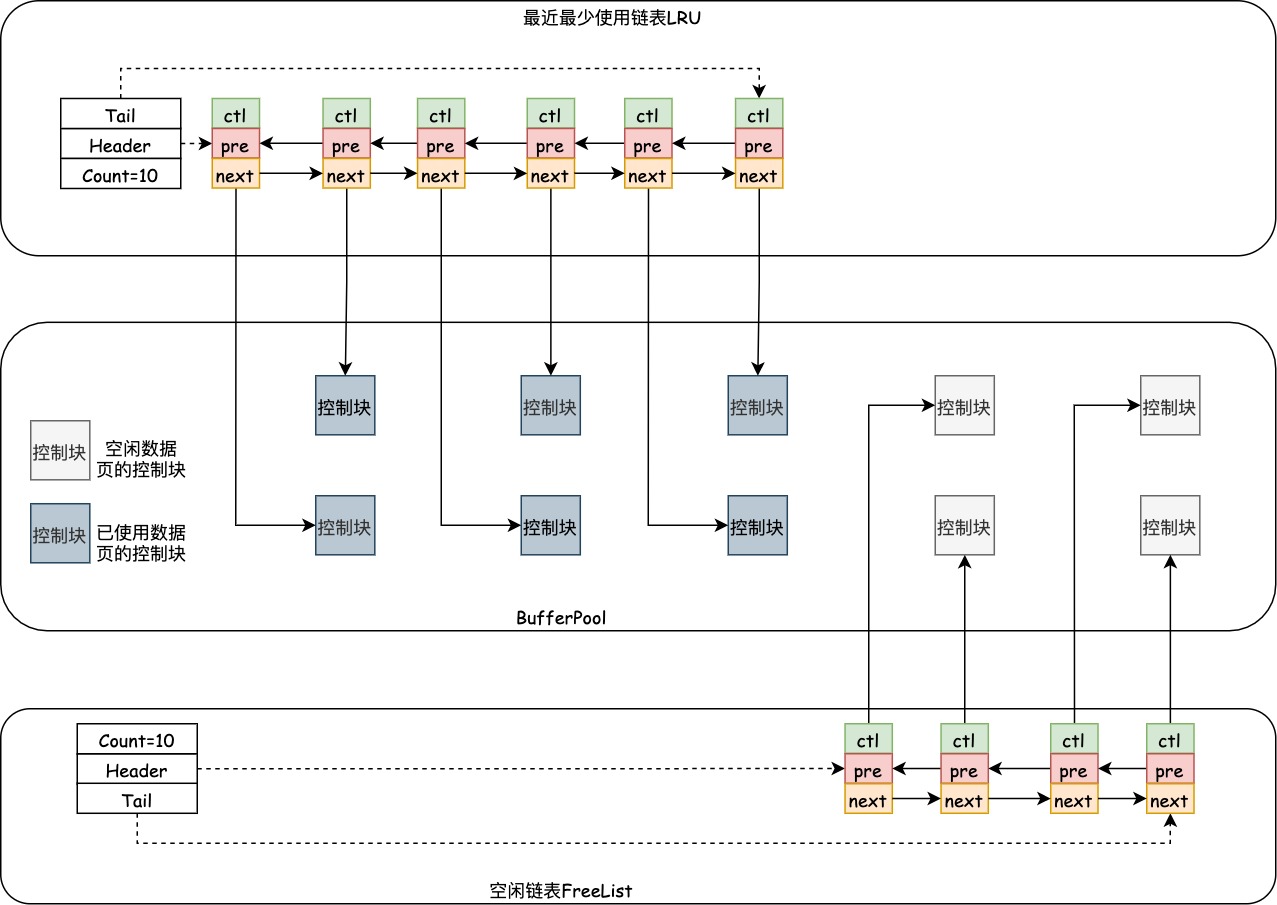
当需要将新数据页添加到缓冲池时,最近最少使用的数据页会可能会从LRU链表中淘汰,并将新数据页添加到LRU链表的中间。此插入点将列LRU链表划分为两个子链表:
- 头部的5/8区域,最近访问多的热数据列表;
- 尾部的3/8区域,最近访问少的冷数据列表;
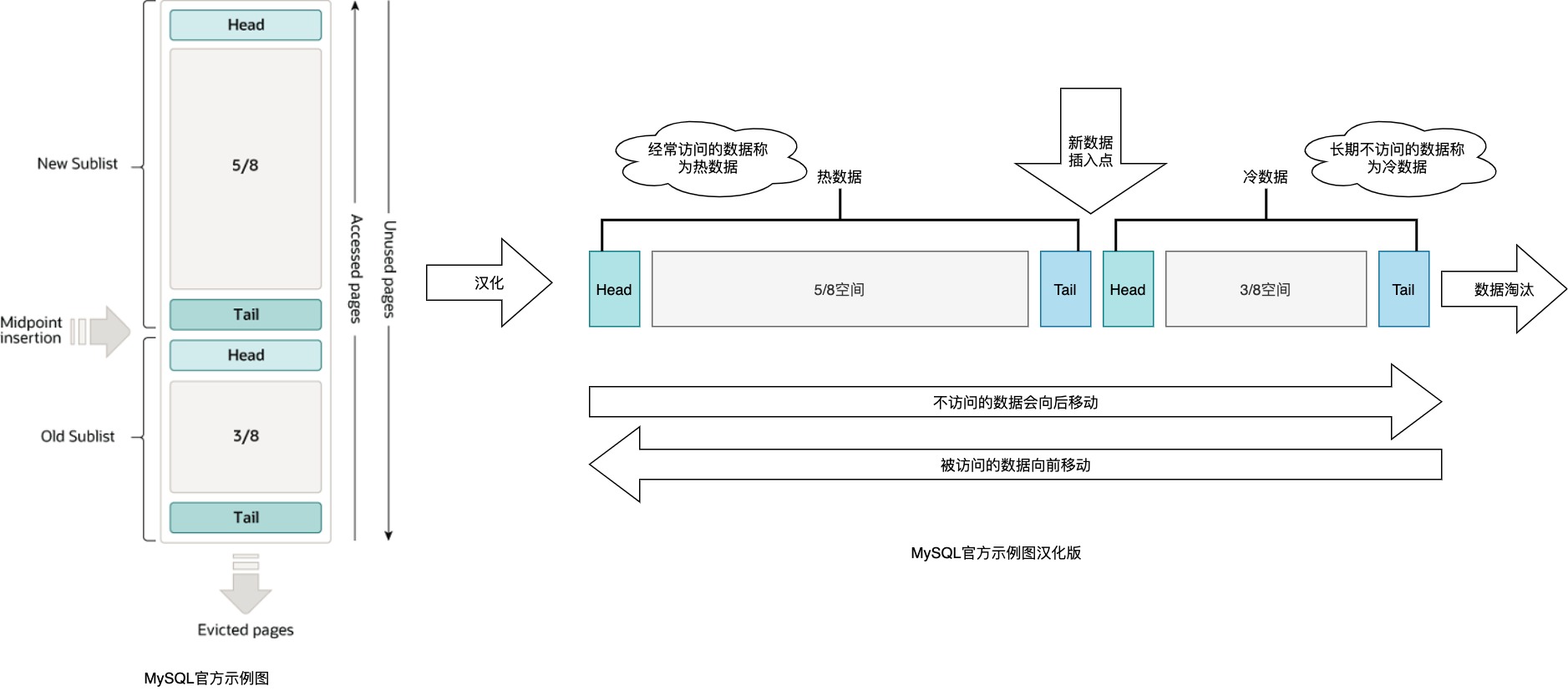
LRU算法会将经常使用的数据页保留在热数据列表中,冷数据列表中包含了不经常访问的数据页,这些数据页是LRU列表满了之后最先被淘汰的数据。默认情况下,算法的流程如下:
- LRU链表的的后3/8区域用于存储冷数据;
- LRU链表的中点是热数据尾部与冷数据头部相交的边界;
- 被访问的冷数据会从冷数据链表移动到热数据链表;
- 热数据链表中的数据如果长时间不访问,会逐渐移入冷数据链表;
- 冷数据长时间不被访问,并且LRU链表满了,那么末尾的冷数据会淘汰出LRU链表;
- 预读的数据只会插入LRU链表,不会被移动到热数据链表;
LRU算法还有一个问题,当某一个SQL语句,要批量扫描大量数据时,由于这些页都会被访问,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。MySQL缓冲池加入了一个冷数据停留时间窗口的机制:
- 假设T=冷数据停留时间窗口;
- 插入冷数据头部的数据页,即使立刻被访问,也不会立刻放入新生代头部;
- 只有满足
被访问并且在冷数据区域停留时间大于T,才会被放入新生代头部;
加入冷数据停留时间窗口策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些短期内仅仅访问了一次的页。
MySQL中LRU链表相关的参数:
innodb_old_blocks_pct:冷数据占整个LRU链长度的比例,默认是3/8,即整个LRU中热数据与冷数据长度比例是5:3。innodb_old_blocks_time:冷数据停留时间窗口机制中冷数据停留时长;
脏数据链表FLU
当需要更新一个数据页时,如果数据页在内存中就直接更新更新内存中的数据,但是由于写回磁盘的代价比较高,所以InnoDB并不会立刻把修改后的数据写回磁盘,此时,就出现了缓存区数据页和磁盘数据页中的数据不一致的情况,这种情况下缓存区数据页被称为脏页,管理所有脏页的链表叫脏数据链表,以下为脏数据链表的示例图:
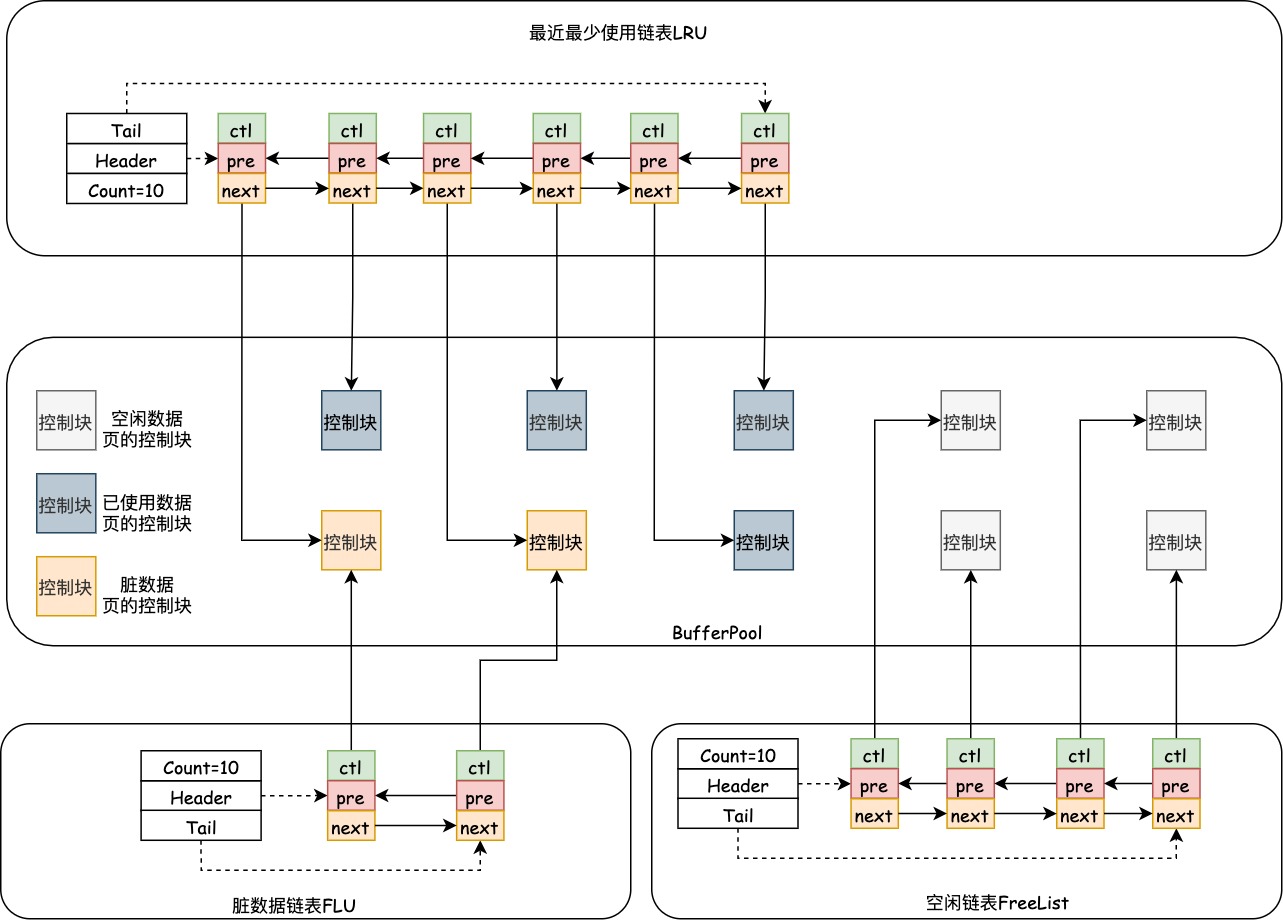
脏数据链表是LRU链表的子集,LRU链表包含了所有的脏页数据。脏页中的数据最终是要写回磁盘的,将内存数据页刷到磁盘的操作称为刷脏,以下是几种会触发InnoDB刷脏的情况
- InnoDB的RedoLog写满了,这时候系统会停止所有更新操作,把Checkpoint往前推进,RedoLog留出空间可以继续写;
- 当系统内存不足,需要把一个脏页要从LRU链表中淘汰时,要先把脏页写回磁盘;
- MySQL在空闲时,会自动把一部分脏页写回磁盘;
- MySQL正常关闭时,会把所有脏页都写回磁盘;
InnoDB中可以通过一些参数设置刷脏行为:
-
innodb_io_capacity:MySQL数据文件所在磁盘的IO能力,innodb_io_capacity参数会影响MySQL刷脏页的速度。磁盘的IOPS可以通过FIO工具来测试,测试命令如下所示:fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest如果不能正确地设置
innodb_io_capacity参数,可能能导致数据库性能问题。举个例子说明:如果MySQL主机磁盘用的是SSD,但是innodb_io_capacity的值设置的是比较低,只有300。这种情况下,InnoDB认为这个系统的IO能力只有300,所以刷脏页刷得特别慢,甚至比脏页生成的速度还慢,这样就造成了脏页累积,影响了查询和更新性能。 -
innodb_flush_neighbors:在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉;而且这个把“邻居”拖下水的逻辑还可以继续蔓延,也就是对于每个邻居数据页,如果跟它相邻的数据页也还是脏页的话,也会被放到一起刷。innodb_flush_neighbors参数就是用来控制这个行为的,值为1的时候会有上述的“连坐”机制,值为0时表示不找邻居,自己刷自己的。对于SSD这类IOPS比较高的设备,IOPS往往不是瓶颈,innodb_flush_neighbors应该设置为0。在MySQL8.0中,innodb_flush_neighbors参数的默认值已经是0了。 -
innodb_max_dirty_pages_pct:脏页比例超过innodb_max_dirty_pages_pct之后,InnoDB会全力刷脏页,如果没超过这个比例,那么刷脏页速度=max(当前脏页比例/innodb_max_dirty_pages_pct*innodb_io_capacity, RedoLog的缓存大小计算刷脏页速度);
压缩页链表(Zip List)
Mysql允许用户对表进行压缩以节省磁盘空间,这些压缩页的数据在进入内存之后,要进行解压之后才能使用。
我们可以通过以下SQL语句建立一张InnoDB数据表:
create table user_info
(
id int primary key,
age int not null,
name varchar(16),
sex bool
)engine=InnoDB;
对于建立好的InnoDB数据表,我们可以通过以下SQL语句对表进行压缩,压缩后表占用的磁盘空间会减小:
alter table user_info row_format=compressed;
InnoDB中的表压缩是针对表数据页的压缩,不仅可以压缩表数据,还可以压缩表索引。压缩页的大小可以是1k/2k/4k/8k。
压缩页链表存储的就是这些压缩后的页,压缩页在加载进内存之后,并不会立即解压,而是在需要使用的时候再进行解压。
压缩页有不同的大小1k/2k/4k/8k,InnoDB使用了伙伴管理算法来管理压缩页。有5个ZipFree链表分别管理1k/2k/4k/8k/16K的内存碎片,8K的链表里存储的都是8K的碎片,如果新读入一个8K的页面,首先从这个链表中查找,如果有则直接返回,如果没有则从16K的链表中分裂出两个8K的块,一个被使用,另外一个放入8K链表中。
解压页链表(Unzip LRU List)
压缩页链表中的数据都是被压缩的,不能直接CRUD,使用前需要解压,解压后的数据都存储在解压页链表中,解压页链表中的数据写回磁盘时需要压缩。
自适应哈希索引
我们知道B+树默认的索引数据结构是B+树,B+树对范围查询或者LIKE语法的支持比较好。
如果数据库中有大量的等值查询,使用哈希索引能显著提升查询效率。Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,会对该热点数据建立内存哈希索引,这个索引被称为自适应哈希索引。
自适应哈希索引默认是开启状态,可以通过设置
innodb_adaptive_hash_index变量或在启动MySQL时添加--skip-innodb-adaptive-hash-index变量启用自适应哈希索引。
InnoDB中可以查看到哈希索引的使用情况,命令及输出如下所示:
mysql> show engine innodb status\G
……
Hash table size 34673, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
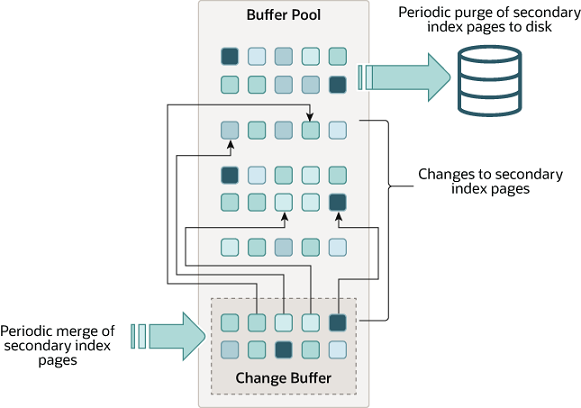
ChangeBuffer
在修改数据库数据时,如果对应的数据页刚刚好在缓存区,可以之间修改缓存区的数据页,并把数据页标记为脏页。
如果修改数据数据时,对应的数据页如果不在缓存区,就需要把数据页从磁盘加载到缓存区,然后进行修改。对于写多读少的场景,会产生大量的磁盘IO,影响数据库的性能。
Change Buffer对数据更新过程有加速作用。 如果数据页没有在内存中,会将更新操作缓存到Change Buffer 中,这样就不需要从磁盘读入这个数据页,减少了IO操作,提高了性能。 先将更新操作,记录在Change Buffer 中,之后再进行 merge,真正进行数据更新。InnoDB Change Buffer比较复杂,我会在后续单独章节中进行介绍。
行锁信息管理
InnoDB支持行锁,可以对数据库中的数据进行加锁操作,这些锁信息也存放在BufferPool中,具体存储格式此处不做详细解释。
既然锁信息都存放在BufferPool中,那么锁的数目肯定受缓存区大小的影响,如果InnoDB中锁占据的空间超过了BufferPool总大小的70%,在新添加锁时会报以下错误:
[FATAL] InnoDB: Over 95 percent of the buffer pool is occupied by lock heaps or the adaptive hash index! Check that your transactions do not set too many row locks. Your buffer pool size is 8 MB. Maybe you should make the buffer pool bigger? We intentionally generate a seg fault to print a stack trace on Linux!For more information, see Help and Support Center at http://www.mysql.com.
我是御狐神,欢迎大家关注我的微信公众号:wzm2zsd

参考文档
- MySQL 8.0 Reference Manual/The InnoDB Storage Engine/InnoDB Architecture
- Chunk Change: InnoDB Buffer Pool Resizing
- 玩转MySQL之十InnoDB Buffer Pool详解
- InnoDB的Buffer Pool简介
- Mysql的Innodb存储引擎缓冲池个人理解
- InnoDB关键特性之自适应hash索引
- InnoDB页压缩技术
本文最先发布至微信公众号,版权所有,禁止转载!
