

【Socket编程】【第一节】【Socket基本原理和套接字】
参考http://c.biancheng.net/view/2351.html
一、scoket套接字(告诉你使用哪种数据传输方式)
这个世界上有很多种套接字(socket),比如 DARPA Internet 地址(Internet 套接字)、本地节点的路径名(Unix套接字)、CCITT X.25地址(X.25 套接字)等。但本教程只讲第一种套接字——Internet 套接字,它是最具代表性的,也是最经典最常用的。以后我们提及套接字,指的都是 Internet 套接字。
1.流格式套接字(SOCK_STREAM)
SOCK_STREAM 是一种可靠的、双向的通信数据流,数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送。
- 数据在传输过程中不会消失;
- 数据是按照顺序传输的;
- 数据的发送和接收不是同步的(有的教程也称“不存在数据边界”)。
为什么流格式套接字可以达到高质量的数据传输呢?因为它使用了TCP协议,会控制你的数据按照顺序到达并且没有错误。
2.数据报格式套接字(SOCK_DGRAM)
数据报格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。
可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:
- 强调快速传输而非传输顺序;
- 传输的数据可能丢失也可能损毁;
- 限制每次传输的数据大小;
- 数据的发送和接收是同步的(有的教程也称“存在数据边界”)。
数据报套接字也使用 IP 协议作路由,但是它不使用 TCP 协议,而是使用 UDP 协议(User Datagram Protocol,用户数据报协议)。
二、OSI 只是存在于概念和理论上的一种模型,它的缺点是分层太多,增加了网络工作的复杂性,所以没有大规模应用。后来人们对 OSI 进行了简化,合并了一些层,最终只保留了 4 层,从下到上分别是接口层、网络层、传输层和应用层,这就是大名鼎鼎的 TCP/IP 模型。
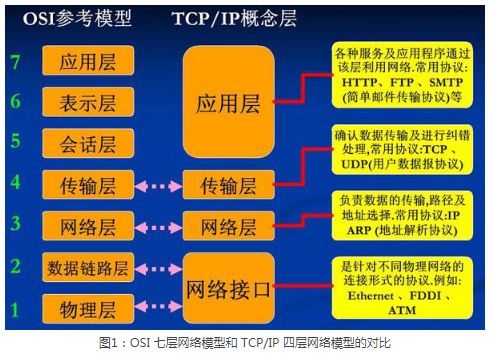
两台计算机进行通信时,必须遵守以下原则:
- 必须是同一层次进行通信,比如,A 计算机的应用层和 B 计算机的传输层就不能通信,因为它们不在一个层次,数据的拆包会遇到问题。
- 每一层的功能都必须相同,也就是拥有完全相同的网络模型。如果网络模型都不同,那不就乱套了,谁都不认识谁。
- 数据只能逐层传输,不能跃层。
- 每一层可以使用下层提供的服务,并向上层提供服务。
到目前为止,大致的了解了应用程序和tcpip协议的大致关系,我们只是知道socket编程是在tcp/IP上的网络编程,但是socket在上述的模型的什么位置呢。这个位置被一个天才的理论家或者是抽象的计算机大神提出并且安排出来.
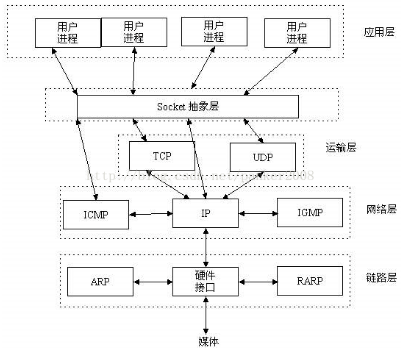
我们可以发现socket就在应用程序的传输层和应用层之间,设计了一个socket抽象层,传输层的底一层的服务提供给socket抽象层,socket抽象层再提供给应用层,问题又来了,应用层和socket抽象层之间和传输层,网络层之间如何通讯的呢,了解这个之前,我们还是回到原点。
要想理解socket编程怎么通过socket关键词实现服务器和客户端通讯,必须得实现的了解tcp/ip是怎么通讯的,在这个的基础上在去理解socket的握手通讯,tcp/ip原理会在另一篇文章中讲到。
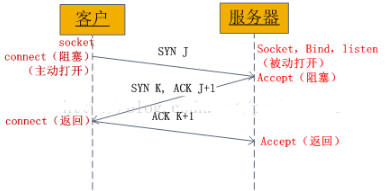
第一次握手:客户端发送一个syn包,尝试连接服务器
第二次握手:服务端接收客户端发送过来的syn包,并进行确认ack=J+1,并发送一个syn包 SYN=K
第三次握手:客户端接收服务端发送的syn包,并向服务器发送确认包ack=k+1,至此,两者之间建立连接
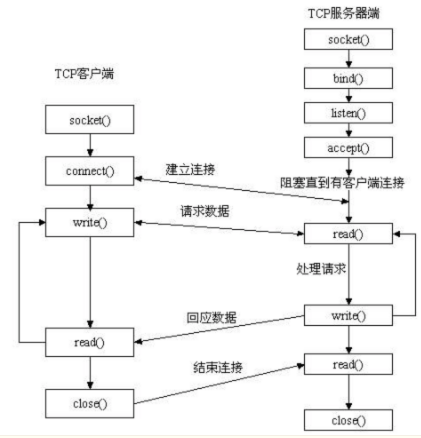
服务端:初始化socket,然后绑定端口,监听端口,调用阻塞,等待接收消息,在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
在重启服务端时可能会遇到Address already in use的情况,这是因为你的服务器仍然存在四次挥手的time_wait状态的占用地址
解决办法:加入一条socket配置,重用ip和端口
phone=socket(AF_INET,SOCK_STREAM)
phone.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加
phone.bind(('127.0.0.1',8080))
三、socket缓冲区以及阻塞模式
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。

四、阻塞模式
对于TCP套接字(默认情况下),当使用 write()/send() 发送数据时:
1) 首先会检查缓冲区,如果缓冲区的可用空间长度小于要发送的数据,那么 write()/send() 会被阻塞(暂停执行),直到缓冲区中的数据被发送到目标机器,腾出足够的空间,才唤醒 write()/send() 函数继续写入数据。
2) 如果TCP协议正在向网络发送数据,那么输出缓冲区会被锁定,不允许写入,write()/send() 也会被阻塞,直到数据发送完毕缓冲区解锁,write()/send() 才会被唤醒。
3) 如果要写入的数据大于缓冲区的最大长度,那么将分批写入。
4) 直到所有数据被写入缓冲区 write()/send() 才能返回。
当使用 read()/recv() 读取数据时:
1) 首先会检查缓冲区,如果缓冲区中有数据,那么就读取,否则函数会被阻塞,直到网络上有数据到来。
2) 如果要读取的数据长度小于缓冲区中的数据长度,那么就不能一次性将缓冲区中的所有数据读出,剩余数据将不断积压,直到有 read()/recv() 函数再次读取。
3) 直到读取到数据后 read()/recv() 函数才会返回,否则就一直被阻塞。
这就是TCP套接字的阻塞模式。所谓阻塞,就是上一步动作没有完成,下一步动作将暂停,直到上一步动作完成后才能继续,以保持同步性。
五、粘包(数据的无边界性,不知道一下提取多少数据,只有TCP协议会出现这个问题)
服务端:接收方不能及时接受缓存区的包,造成多个包接受(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
客户端:发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
解决方法:为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes,参考https://www.cnblogs.com/zhangyingai/p/7097922.html


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· 为DeepSeek添加本地知识库
· 精选4款基于.NET开源、功能强大的通讯调试工具
· DeepSeek智能编程
· 大模型工具KTransformer的安装
· [计算机/硬件/GPU] 显卡