【研究生学习】深度学习中常用的Normalization方法与其Pytorch的调用
本篇博客记录一下在深度学习中常用的Batch Normalization和Layer Normalization方法的基本原理,参考的资料的链接如下:
详解深度学习中的Normalization,BN/LN/WN
NLP中 batch normalization与 layer normalization
【深度学习】batch normalization和layer normalization区别
模型优化之Layer Normalization
独立同分布的数据可以简化常规机器学习模型的训练,提升机器学习模型的预测能力,因此把数据喂给机器学习模型之前,白化是一个重要的数据预处理步骤,其一般包含两个目的,一个是去除特征的相关性,另一个是使得所有特征具有相同的均值和方差
而在深度学习中,神经网络涉及到很多层的叠加,而每一层的参数更新会导致上一层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新,这一现象被称为Internal Covariate Shift。而Normalization方法就是从数据的分布上进行处理,使得每层的输入数据分布范围可控
Batch Normalization
Batch Normalization是对一批样本的同一维度特征做归一化
令batch_size为m,则在一个mini batch中的值为,γ和β是待学习的参数,则整个Batch Normalization的过程计算如下:
输出为:
mini-batch mean:
mini-batch variance:
normalize:
scale and shift:
可见共有两个步骤:
- 标准化
- 尺度变换和偏移:获得新的分布,均值为β,方差为,这些都是需要学习的参数
Layer Normalization
Layer Normalization是对单个样本的所有维度特征做归一化
Batch Normalization和Layer Normalization的比较
关于Batch Normalization和Layer Normalization的比较(以下简称为BN和LN),下面这张图片是比较经典的:
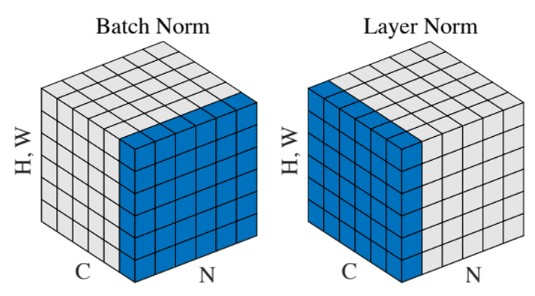
其中N是batch size,C是通道数,H,W是特征的空间维度
在NLP中,N可以代表有N句话,C代表一句话的长度,H,W可以代表词向量的维度,假如词向量的维度为100(即立方体的高),batch size为64(即立方体中的N),则BN和LN分别计算如下:
- BN:固定每句话的第一个位置,则这个切片是(64,100)维度的矩阵
- LN:固定一句话,则切片是(一个句子的长度,100)维度的矩阵
BN取出一条(1,64)的向量并进行缩放,LN则取出一条(1,100)的向量进行缩放
BN和LN都可以较好地抑制梯度消失和梯度爆炸的情况,但是BN不适合RNN、Transformer等序列网络
Pytorch调用几种Normalization方法
这里的Pytorch
torch.nn.BatchNorm2d
torch.nn.LayerNorm
torch.nn.InstanceNorm2d
本文作者:Destiny_zxx
本文链接:https://www.cnblogs.com/yuhengz/p/17420888.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步