【研究生学习】Transformer模型以及Pytorch实现
Transformer是Google在2017年提出的网络架构,仅依赖于注意力机制就可以处理序列数据,从而可以不使用RNN或CNN。当前非常热门的BERT模型就是基于Transformer构建的,本篇博客将介绍Transformer的基本原理,以及其在Pytorch上的实现。
Transformer基本原理
论文《Attention is all you need》中给出了Transformer的整体结构,如下图所示。
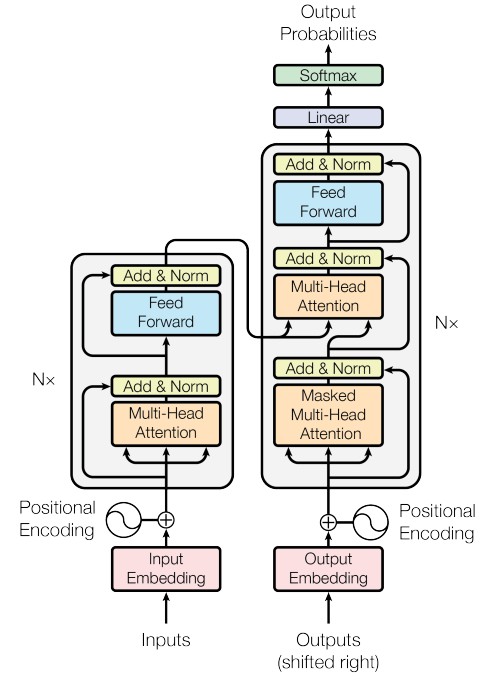
可见Transformer分为两个部分,左边是编码器部分,右边是解码器部分
编码器部分
Input Embedding
由稀疏的one-hot进入一个不带bias的FFN得到一个稠密的连续向量
Positional Encoding
通过sin/cos来固定表征
- 每个位置确定性的
- 对于不同的句子,相同位置的距离一致
- 可以推广到更长的测试句子
pe(pos+k)可以写成pe(pos)的线性组合
通过残差连接来使得位置信息流入深层
Multi-Head self-Attention
多头可以使得建模能力更强,表征空间更丰富
由多组QKV构成,每组单独计算一个attention向量
把每组的attention向量拼起来,并进入一个不带bias的FFN得到最终的向量
Feed Forward
只考虑每个单独位置进行建模,不同位置参数共享
类似于1*1pointwise convolution
解码器部分
Output Embedding
Masked Multi-Head self-Attention
Multi-Head cross-Attention
Feed Forward
Linear和Softmax
Transformer的Pytorch实现
Pytorch中的Transformer API源码
调用:
import torch
torch.nn.Transformer
首先在初始化部分,包含很多超参数,如下图所示。

其中主要参数如下:
- d_model:Transformer的特征维度
- n_head:多头机制中头的数目
- num_encoder_layers:编码器中block的数目
- num_decoder_layers:解码器中block的数目
- dim_feedforward:输入feed forward的特征维度
本文作者:Destiny_zxx
本文链接:https://www.cnblogs.com/yuhengz/p/17420034.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。
分类:
研究生学习



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步