【研究生学习】Pytorch基本知识——神经网络实战分类与回归任务
本博客主要记录一下神经网络实战回归任务中的气温预测和分类任务中MNIST分类任务如何用Pytorch完成
回归任务
气温数据集及任务介绍
首先需要导入数据集,并打印数据集的基本信息:
import pandas as pd
features = pd.read_csv('temps.csv')
print(features.head()) # 取数据的前n行数据,默认是前5行
print(features.shape) # 数据维度
print(features.columns) # 数据参数说明
可以看到运行结果,看一下数据的样子:

数据中的参数如下:
- year,month,day,week:具体时间
- temp_1:昨天的最高温度值
- temp_2:前天的最高温度值
- average:在历史中,每年这一天的平均最高温度值
- actual:标签值,当天的真实最高温度
- friend:不用管
其次需要对时间数据进行处理:
import datetime
years = features['year']
months = features['month']
days = features['day']
dates = [str(int(year))+'-'+str(int(month))+'-'+str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date,'%Y-%m-%d') for date in dates]
数据中的week是字符串,需要转换为独热编码:
features = pd.get_dummies(features) # 独热编码
这样处理后的数据如下图所示:
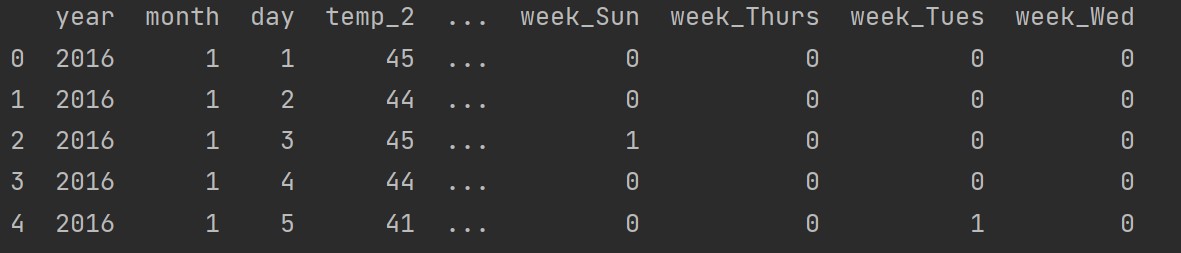
在训练前还需要将标签和输入分开:
labels = np.array(features['actual'])
features = features.drop('actual', axis=1) # 在特征中去除标签作为输入
features = np.array(features) # 转换成合适的格式
最后需要对数据进行标准化,使用sklearn中的预处理模块:
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
按建模顺序构建完成网络架构
首先可以直接按照处理的顺序构造网络,代码如下:
x = torch.tensor(input_features, dtype=float)
y = torch.tensor(labels, dtype=float)
# 权重参数初始化
weights = torch.randn((14, 128), dtype=float, requires_grad=True)
biases = torch.randn(128, dtype=float, requires_grad=True)
weights2 = torch.randn((128, 1), dtype=float, requires_grad=True)
biases2 = torch.randn(1, dtype=float, requires_grad=True)
learning_rate = 0.001
losses = []
for i in range(1000):
# 计算隐藏层
hidden = x.mm(weights)+biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predictions = hidden.mm(weights2)+biases2
# 计算损失
loss = torch.mean((predictions-y)**2)
losses.append(loss.data.numpy())
if i % 100 == 0:
print(loss)
loss.backward()
# 更新参数
weights.data.add_(-learning_rate*weights.grad.data)
biases.data.add_(-learning_rate*biases.grad.data)
weights2.data.add_(-learning_rate*weights2.grad.data)
biases2.data.add_(-learning_rate*biases2.grad.data)
# 每次迭代需要清空
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
上面的代码就是从原理出发一步一步按顺序搭建,但这样子比较麻烦,可以对上面的代码进行简化
简化代码训练网络模型
对上一部分的代码进行简化后的代码如下:
import matplotlib.pyplot as plt
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr=0.001)
losses = []
for i in range(1000):
batch_loss = []
# 采用mini-batch方法训练网络
for start in range(0, len(input_features), batch_size):
end = start+batch_size if start+batch_size<len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype=torch.float, requires_grad=True)
yy = torch.tensor(labels[start:end], dtype=torch.float, requires_grad=True)
predictions = my_nn(xx)
loss = cost(predictions, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
if i % 100 == 0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
# 预测训练结果
x = torch.tensor(input_features, dtype=torch.float)
predict = my_nn(x).data.numpy()
# 创建表格存放标签和预测结果
true_data = pd.DataFrame(data={'date':dates, 'actual':labels})
predict_data = pd.DataFrame(data={'date':dates, 'prediction':predict.reshape(-1)})
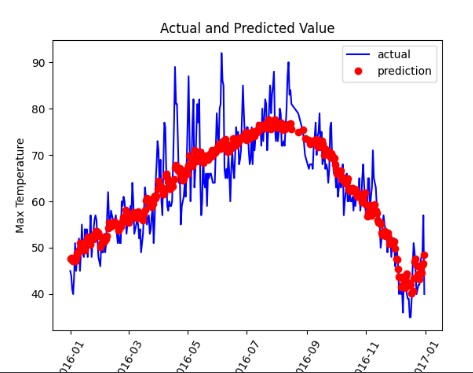
plt.plot(true_data['date'], true_data['actual'], 'b-', label='actual')
plt.plot(predict_data['date'], predict_data['prediction'], 'ro', label='prediction')
plt.xticks(rotation=60)
plt.legend()
plt.xlabel('Date')
plt.ylabel('Max Temperature')
plt.title('Actual and Predicted Value')
plt.show()
最终画出的结果图如下:
分类任务
分类任务概述
首先需要获取MNIST数据集,我是直接在网上下载的mnist.pkl.gz版本
接下来就需要解压、读取数据集,并且选择其中的一张图片显示:
from pathlib import Path
import pickle
import gzip
from matplotlib import pyplot
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
FILENAME = "mnist.pkl.gz"
with gzip.open((PATH/FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
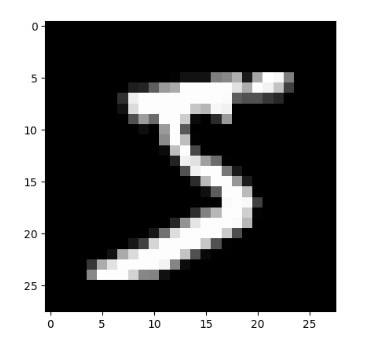
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
pyplot.show()
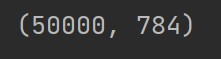
print(x_train.shape)
显示结果和运行结果如下:
在这里我们要实现的分类任务的基本框图如下图所示:

可见神经网络输出的是每一个类别的概率
整体的网络架构如下图所示:
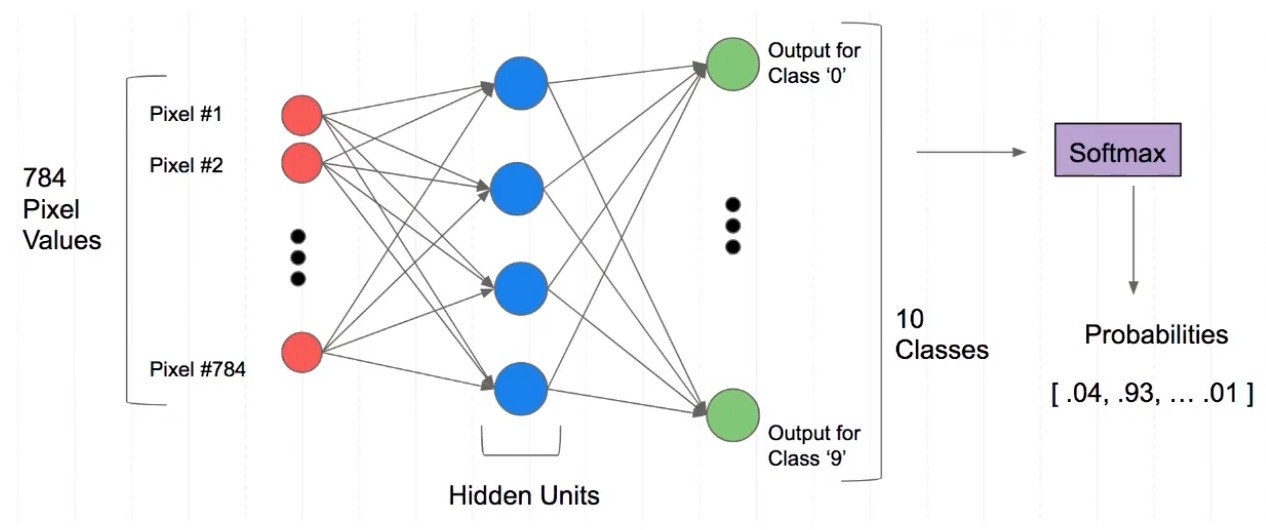
构建分类网络模型
首先需要将数据转换为tensor格式:
import torch
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid))
n, c = x_train.shape
在使用Pytorch时,有时会使用nn.Module,有时会使用nn.functional,一般而言,如果模型有可学习的参数,最好用nn.Module;其他情况nn.functional相对更简单些,比如激活函数、损失函数等
因此可以创建一个简单的模型测试如下代码所示:
import torch.nn.functional as F
def model(xb):
return xb.mm(weights)+bias
loss_func = F.cross_entropy
bs = 64
xb = x_train[0:bs] # a mini-batch from x
yb = y_train[0:bs]
weights = torch.randn([784, 10], dtype=torch.float, requires_grad=True)
bias = torch.zeros(10, requires_grad=True)
print(loss_func(model(xb), yb))
值得注意的是,需要对这里的.cross_entropy(input, target)函数进行理解,交叉熵的公式计算如下:
其中p为真实值,q为预测值
而.cross_entropy(input, target)函数中包含了softmax和log的操作,故而input参数不需要进行这两个操作;同时target参数不需要以one-hot形式表示,而是直接用scalar,scalar的值则是真实类别的index
还可以创建一个model来更简化代码:
- 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数
- 无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播
- Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器
构建的模型如下所示:
from torch import nn
class Mnist_NN(nn.Module):
def __init__(self):
super(Mnist_NN, self).__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = self.out(x)
return x
在训练之前,需要生成一个对象,同时也可以打印一下权重和偏置项:
net = Mnist_NN()
for name, parameter in net.named_parameters():
print(name, parameter, parameter.size())
可见神经网络中的权重和偏置项已经默认完成了初始化
DataSet模块介绍与应用方法
可以使用TensorDataset和DataLoader来简化取数据的过程:
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=64, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=64*2)
接下来就是训练过程,在这里用函数来表示整个训练过程:
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval()
with torch.no_grad():
losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])
val_loss = np.sum(np.multiply(losses, nums))/np.sum(nums)
print('step:'+str(step),'val loss:'+str(val_loss))
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
一般训练模型时加上model.train(),这样子就会正常使用Batch Normalization和Dropout;而在测试的时候一般选择model.eval(),这样就不会正常使用Batch Normalization和Dropout
最后调用函数即可:
from torch import optim
model = Mnist_NN()
opt = optim.SGD(model.parameters(), lr=0.001)
loss_func = F.cross_entropy
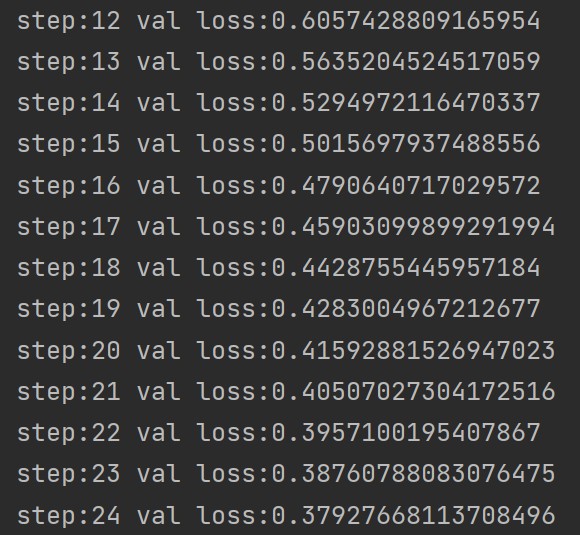
fit(25, model, loss_func, opt, train_dl, valid_dl)
部分运行结果如下:
本文作者:Destiny_zxx
本文链接:https://www.cnblogs.com/yuhengz/p/17297185.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步