OpenStack的HA方案
一.HA服务分类
HA将服务分为两类:
- 有状态服务:后续对服务的请求依赖之前对服务的请求,OpenStack中有状态的服务包括MySQL数据库和AMQP消息队列。对于有状态类服务的HA,如neutron-l3-agent,neutron-metadata-agent、nova-compute,cinder-volume等服务,最简单的方法就是多节点部署。比如某一节点的nova-compute服务挂了,也并不会影响整个云平台不能创建虚拟机,或者所在节点的虚拟机无法使用。(比如ssh等)
- 无状态服务:对服务的请求之间没有依赖关系,是完全对立的。基于冗余实例和负载均衡实现HA,OpenStack中无状态的服务包括nova-api,nova-conductor,glance-api,keystone-api,neutron-api,nova-scheduler等。由于API服务,属于无状态类服务,天然支持Active/Active HA模式。因此,一般使用keepalived +HAProxy方案来做。
二.HA的类型
HA的类型:
HA需要使用冗余的服务器组成集群来运行负载,包括应用和服务,这种冗余性也可以将HA分为两类:
- Active/Passive HA:即主备HA,在这种配置下,系统采用主和备用机器来提供服务。系统只在主设备上提供服务,在主设备故障时,备设备上的服务被启动来替代主设备提供的服务。典型的可以采用CRM软件比如Pacemaker来控制主备设备之间的切换,并提供一个虚拟机IP来提供服务。
- Avtive/Active HA:即主主HA,包括多节点时成为多主,在这种配置下,系统在集群内所有服务器上运行同样的负载,以数据库为例,对于一个实例的更新,会被同步到所有实例上,这种配置下往往采用负载均衡软件,比如HAProxy来提供服务的虚拟IP
三.OpenStack云环境的高可用(HA)
云环境时一个广泛的系统,包括了基础设施层,OpenStack云平台服务层,虚拟机和最终用户应用层。
云环境的HA包括:
- 用于应用的HA
- 虚拟机的HA
- OpenStack云平台服务的HA
- 基础设施层的HA:电力,空调和防火设施,网络设备(如交换机、路由器)、服务器设备和存储设备等。
OpenStack HA架构:
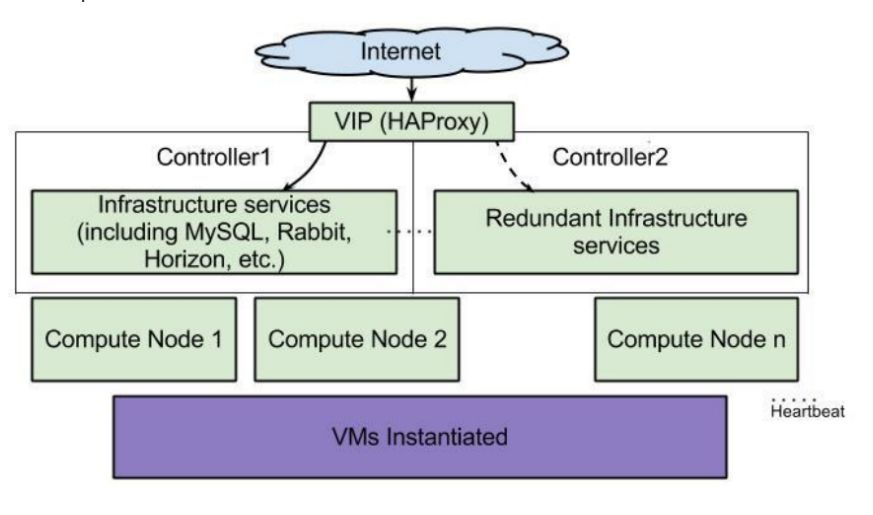
如果从部署层面来划分,OpenStack高可用的内容包括:
- 控制节点(RabbitMQ、Mariadb、Keystone、Nova-API等)
- 网络节点(neutron_dhcp_agent、neutron_l3_agent、neutron_openvswitch_agent等)
- 计算节点(nova-compute、neutron_openvswitch_agent、虚拟机等)
- 存储节点 (cinder-volume、swift等)
- 控制节点HA:
在生产环境中,建议至少部署三台控制节点,其余可做计算节点、网络节点、或存储节点。采用HAProxy + KeepAlived的方式,代理数据库服务和OpenStack服务,对外包括VIP提供API访问。
- RabbitMQ消息队列HA:
RabbitMQ采用原生Cluster集群方案,所有节点同步镜像队列。小规模环境中,三台物理机,其中2个Mem节点主要提供服务,1个Disk节点用于持久化消息,客户端根据需求分别配置主从策略。据说使用ZeroMQ代替默认的RabbitMQ有助于提升集群消息队列性能。
- OpenStack API服务HA:
OpenStack控制节点上运行的基本上是API 无状态类服务,如nova-api、neutron-server、glance-registry、nova-novncproxy、keystone等。因此,可以由 HAProxy 提供负载均衡,将请求按照一定的算法转到某个节点上的 API 服务,并由KeepAlived提供 VIP。
- 网络节点HA:
网络节点上运行的Neutron服务包括很多的组件,比如 L3 Agent,openvswitch Agent,LBaas,VPNaas,FWaas,Metadata Agent 等,其中部分组件提供了原生的HA 支持。
• Openvswitch Agent HA: openvswitch agent 只在所在的网络或者计算节点上提供服务,因此它是不需要HA的
• L3 Agent HA:成熟主流的有VRRP 和DVR两种方案
• DHCP Agent HA:在多个网络节点上部署DHCP Agent,实现HA
• LBaas Agent HA:Pacemaker + 共享存储(放置 /var/lib/neutron/lbaas/ 目录) 的方式来部署 A/P 方式的 LBaas Agent HA
- 存储节点HA
存储节点的HA,主要是针对cinder-volume、cinder-backup服务做HA,最简便的方法就是部署多个存储节点,某一节点上的服务挂了,不至于影响到全局。
- 计算节点和虚拟机 HA
计算节点和虚拟机的HA,社区从2016年9月开始一直致力于一个虚拟机HA的统一方案,但目前仍然没有一个成熟的方案。实现计算节点和虚拟机HA,要做的事情基本有三件,即。
① 监控
监控主要做两个事情,一个是监控计算节点的硬件和软件故障。第二个是触发故障的处理事件,也就是隔离和恢复。
OpenStack 计算节点高可用,可以用pacemaker和pacemaker_remote来做。使用pacemaker_remote后,我们可以把所有的计算节点都加入到这个集群中,计算节点只需要安装pacemaker_remote即可。pacemaker集群会监控计算节点上的pacemaker_remote是否 “活着”,你可以定义什么是“活着”。比如在计算节点上监控nova-compute、neutron-ovs-agent、libvirt等进程,从而确定计算节点是否活着,亦或者租户网络和其他网络断了等。如果监控到某个pacemaker_remote有问题,可以马上触发之后的隔离和恢复事件。
② 隔离
隔离最主要的任务是将不能正常工作的计算节点从OpenStack集群环境中移除,nova-scheduler就不会在把create_instance的message发给该计算节点。
Pacemaker 已经集成了fence这个功能,因此我们可以使用fence_ipmilan来关闭计算节点。Pacemaker集群中fence_compute 会一直监控这个计算节点是否down了,因为nova只能在计算节点down了之后才可以执行host-evacuate来迁移虚拟机,期间等待的时间稍长。这里有个更好的办法,就是调用nova service-force-down 命令,直接把计算节点标记为down,方便更快的迁移虚拟机。
③ 恢复
恢复就是将状态为down的计算节点上的虚拟机迁移到其他计算节点上。Pacemaker集群会调用host-evacuate API将所有虚拟机迁移。host-evacuate最后是使用rebuild来迁移虚拟机,每个虚拟机都会通过scheduler调度在不同的计算节点上启动。
当然,还可以使用分布式健康检查服务Consul等。

