Python编程--类的分析
一.类的概念
python是面向对象的编程语言,详细来说,我们把一类相同的事物叫做类,其中用相同的属性(其实就是变量描述),里面封装了相同的方法,比如:汽车是一个类,它包括价格、品牌等属性。那么我们如果需要打印某一辆车的价格和品牌,只需要使用一句代码print "the car's type 'xxx', price: 'xxx'",但是如果需要打印100种品牌的车时,需要怎么操作呢?
这里涉及函数编程,我们只需要写一个函数,然后将不同的品牌和价格以参数的方式传入到函数里就好,这样可以大大提高代码的重用性,而不需要重复写入print语句100次。相同的功能,我们用类也可以实现,具体可以参考如下
二.类实现的简单介绍
- 函数实现:
def printCarinfo(type, price):
print "The car's info in class:type:%s, price:%d" %(type, price)
printCarinfo("BMW", 250000)
printCarinfo("Ford", 15000)
- 类的实现:
class Carinfo: #定义的类名称
def __init__(self, type, price): #初始化的方法,参数有type,price
self.type = type #初始化变量
self.price = price #初始化变量
def printCarinfo(self): #定义类的方法,方法名
print "The car's info in class:type:%s, price:%d" %(self.type, self.price) #定义类的方法的函数执行体
BMW = Carinfo("BMW", 500000) #对象的初始化
Ford = Carinfo("Ford", 25000) #对象的初始化
BMW.printCarinfo() #对象调用类的方法
Ford.printCarinfo() #对象调用类的方法
三.类方法的详细介绍
-
Carinfo类中的方法我们已经了解,printCarinfo里面传递的'self'是什么?
self就表示对象,查看上面的代码,我们如何调用Carinfo类中的printCarinfo方法的,和我们调用函数的方式是不一样的。前面加了一个BMW和Ford(使用了Carinfo的对象),后面也没有加参数,直接就可以打印出type和price两个变量的值。
解释:Carinfo是一个类,它拥有品牌和价格两个属性。BMW和Ford是两个品牌的车,是车的一种,那么它们就拥有车的属性,品牌和价格。不仅拥有,它们的属性还是具体的,有值的。所以当我们使用BMW这个对象去调用printCarinfo这个方法的时候,其实是做了这样一步操作,printCarinfo(BMW),把BMW这个对象传给了printCarinfo方法,BMW这个对象又包括了两个属性type,price。我们在Python中规定这样使用一个对象中的变量:BMW.type, BMW.price
总结:我们调用函数时,传入的BMW对象的BMW.type和BMW.price被类中的printCarinfo以self身份接收,所以我们在使用参数的时候自然就变成了self.type和self.price -
类的初始化
BMW = Carinfo("BMW", 500000) #对象的初始化
Ford = Carinfo("Ford", 25000) #对象的初始化
对象如果想使用对象中的这两个变量,得告诉python每个对象的属性。我们叫做对象的初始化。
这句话实际上完成了两个功能:
- 1.从Carinfo中实例出一个对象BMW/Ford
- 2.给新对象的属性赋值类似于:BMW = Carinfo() BMW.type = "BMW" BMW.price = 25000。其中BMW = Carinfo()只是做了一样事,把对象传给了类,并没有进行赋值,所以我们看__init__方法里,这个时候BMW对象的type和price都是空值,知道后面赋值之后,BMW的属性才有了它的意义。这样我们了解了__init__是什么了,这个方法就是我们在创建对象的时候自动执行的方法,当我们通过Carinfo类实例化一个对象的时候,程序会自动执行这个类的__init__方法,然后也会自动的按照init方法中的代码给这个对象中的属性赋值。
*类中方法的定义和使用
def printCarinfo(self): #定义类的方法,方法名
print "The car's info in class:type:%s, price:%d" %(self.type, self.price) #定义类的方法的函数执行体
查看上面的代码,我们可以看出,Carinfo中的参数在printCarinfo方法中换成了self,在方法的调用中就是用self.属性名来调用了。勒种的函数调用之前先进行类的实例化-----创建一个对象,然后给这个对象的属性赋值。然后才可以调用类中的方法,调用方式是:对象名.方法名()
四.Python中类的方法和属性变为私有
- 私有变量和私有方法的定义:在变量名或函数名前加上"__"两个下划线,那么这个变量就是私有的了
在内部,python使用一种name mangling技术,将__membername替换成_classname__membername,也就是说类的内部定义中,所有以双下划线开始的名字都被翻译成前面加上单下划线和类名的形式。例如:为了保证不能在class之外访问私有变量,python会在类的内部自动的把我们定义的__spam私有变量的名字替换为_classname__spam,因此用户在外部访问__spam的时候就会提示找不到相应的变量。
例如如下示例:
class A(object):
def __init__(self):
self.__data = [] #这里可以翻译成self_A__data = []
self.name = "yushengyin"
def add(self, item):
self.__data.append(item) #这里可以翻译成self._A__data.append(item)
def printData(self):
print self.__data #这里可以翻译为self._A__data
a = A()
print a.__data #外界不能访问私有变量AttributeError: 'A' object has no attribute '__data'
print a._A__data #通过这种方式,在外面也能够访问"私有"变量。这一点在调试中比较重要。
a.add("hello")
a.add("python")
a.printData()
五.以下划线开头的变量解析
- (1) '_xxx' "单下划线"开始的成员变量叫做保护变量,意思是只有类实例和子类实例能访问到这些变量,需通过类提供的接口进行访问,不能用
from module import *导入 - (2) '__xxx' "双下划线"开始的表示类的私有变量/方法名,这是私有成员,只有类对象自己能够访问,子类对象也不能访问到这个数据
class C():
def __init__(self):
self.__name = "python"
class D(C):
def func(self):
print self.__name
instance = D()
#instance.func() #报错提示AttributeError: D instance has no attribute '_D__name' 子类不能访问到父类的私有属性
print instance.__dict__
print instance._C__name
执行结果:
{'_C__name': 'python'}
python
- (3) 'xxx '系统定义名字,前后均有一个"双下划线",代表python里,特殊方法专用的标识,如__init__()代表类的构建函数。
执行代码示例如下:
class B():
def __init__(self):
self.__name = "python" #私有变量,翻译成self._B__name = "python"
def __say(self): #私有方法,翻译成def _B__say(self)
print self.__name #翻译成self._B__name
b = B()
print b.__dict__ #查询示例b的属性的集合
#print b.__name #访问私有属性时,会提示报错AttributeError: B instance has no attribute '__name'
print b._B__name #这样可以访问私有变量
print dir(b) #获取实例的所有属性和方法
print b._B__say() #这样可以调用私有方法
执行结果如下:
{'_B__name': 'python'}
python
['_B__name', '_B__say', '__doc__', '__init__', '__module__']
python
None
六.类的三大特征介绍:封装、多态、继承
-
封装:属性和方法放到类内部,通过对象访问属性或者方法,隐藏功能的实现细节,当然还可以设置党文权限
-
继承:子类需要服用父类里面的属相或者方法,当前子类还可以提供自己的属性和方法
-
多态:同一个方法不同对象调用同一个方法功能的表现形式不一样,例如:1.不同的两个对象,字符串的加法和证书的加法,同样是加法,实现的功能是不一样的2.这两个对象之间没有任何直接继承关系,但是所有对象的最终父类都是元类
-
(1) 封装是什么?为什么要封装?
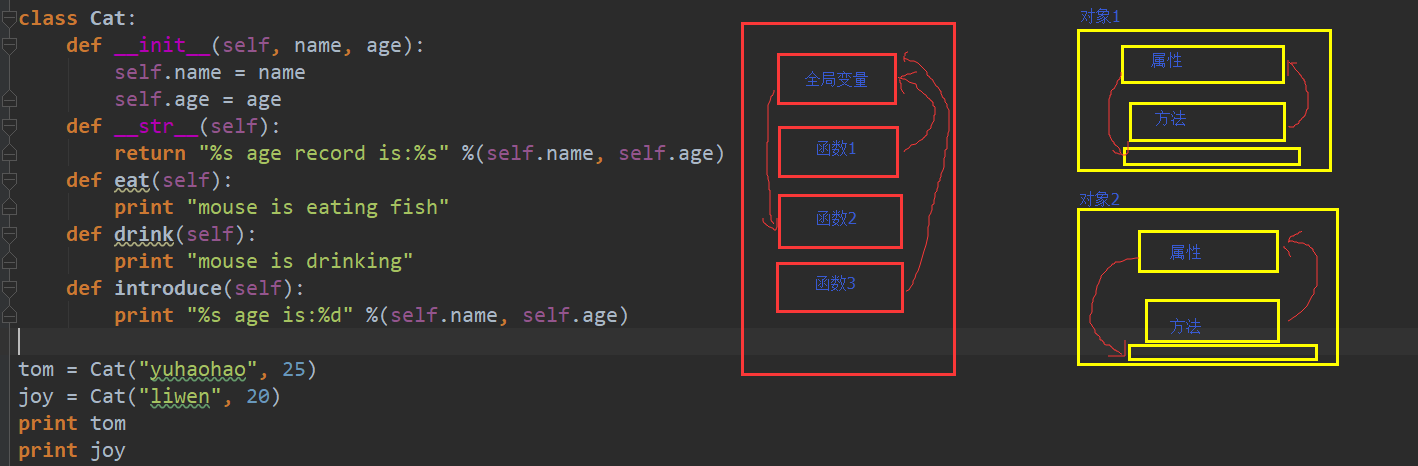
面向过程的本质,就像一个开放的箱子,所有的变量和方法都是暴露在外面的,一个线程下,所有的方法共享全局变量,这个全局变量可以被所有的方法修改,这就带来一个问题:如果一个方法F1想要全局变量只被它使用,但是其它方法肯定也要用的,这样就会造成变量修改的冲突。
这时,类的概念应运而生,所有的变量和方法封装在类内部,类属性相当于类内部的全部变量,实例属性相当于方法内部的局部变量,这样只需要通过类创建不同实例a,b,c,d,实例a,b,c,d可以将这些属性、方法全部私有化。
- 类的本质:
1)是将属性(全部变量),方法(函数)封装在一个类中
2)类里面的方法可以共享属性,属性的修改不会影响类的外部变量,这就是类封装的优势
3)同时类可以被继承,子类可以拥有和父类一样的属性和方法
4)并且子类可以有新的属性,新的方法
#!/usr/bin/python
class Cat:
def __init__(self, name, age):
self.name = name
self.age = age
self.high = 20 #全局变量
def __str__(self):
return "%s age record is:%s" %(self.name, self.age)
def eat(self):
self.high = 88 #类方法中属性的修改为88
print "mouse is eating fish"
return self.high #返回类方法的属性值
def drink(self):
print "mouse is drinking"
return self.high #类方法中的属性值
def introduce(self):
print "%s age is:%d" %(self.name, self.age)
tom = Cat("yuhaohao", 25)
joy = Cat("liwen", 20)
print tom
print joy
print "tom eat is: %d" %tom.eat()
print "joy drink is: %d" %joy.drink()
输出结果如下:
yuhaohao age record is:25
liwen age record is:20
mouse is eating fish
tom eat is: 88 #修改类的属性值为88,然后返回值,查看在此方法内,修改类的属性是否能被修改,答案是在类方法中,可以修改属性值,但是不会修改影响类的全局变量
mouse is drinking
joy drink is: 20 #此对象调用的方法引用的属性值任然是全部变量的值,没有被上面的方法修改全局变量
- (2) 继承是什么?为什么要继承?什么是单继承?什么是多继承?继承链是什么?
继承就是指子类继承父类的属性和方法
单继承就相当于子类COPY了父类,而且子类是可以突变的,可以自我重构父类的方法和属性,变成和父类不一样的类。
多继承就是指子类有很多父类,继承了所有的父类的属性方法,如果子类继承的父类中有好几个方法重名,都叫做run,那么如果子类要用父类的run方法,肯定就会冲突,为了解决这个问题,自然而然的就有了继承链,子类继承父类时是有顺序的,那么子类用的run方法就是根据继承链找到的第一个拥有改方法名run的父类的run方法
class person(object):
def __init__(self, name, age):
self.name = name
self.age = age
class student(person):
def __init__(self, name, age, score):
super(student, self).__init__(name, age)
self.score = score
如上所示,定义了person类,需要定义student类时,可以直接从person类继承,只需要将额外的属性加上,例如score
注意:一定要用super(student,self).init(name,age)去初始化父类,否则,继承自person的student将没有name和age。
函数super(student,self)将返回当前类继承的父类,即person,然后调用__init__()方法,至于self参数在super()中传入,在__init__()中将隐式传递。
- (3) 什么是多态?
类具有继承关系,并且子类类型可以向上转型看做父类类型。如果我们从person派生出studen和teacher,并都写了一个whoami()方法:
class person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def whoami(self):
return "I am a person, my name is %s" %self.name
class student(person):
def __init__(self, name, age, score):
super(student, self).__init__(name, age)
self.score = score
def whoami(self):
return "I am a student, my name is %s" %self.name
class teacher(person):
def __init__(self, name, age, course):
super(teacher, self).__init__(name, age)
self.course = course
def whoami(self):
return "I am a teacher, my name is %s" %self.name
def who_am_i(x):
print x.whoami()
p = person("yuhaohao", 20)
s = student("lim", 25, 90)
t = teacher("zhang",35, "english")
who_am_i(p)
who_am_i(s)
who_am_i(t)
在上面的函数中,我们接收一个变量X,则无论该X是person,student,还是teacher,都可以正确打印出结果:
I am a person, my name is yuhaohao
I am a student, my name is lim
I am a teacher, my name is zhang
这种行为称为多态,也就是说,方法调用将作用在x的实际类型上,s是student类型,它实际上拥有自己的whoami()方法以及从person集成的whoami方法,但调用s.whoami()总是先查找它自身的定义,如果没有定义,则顺着继承链向上查找,直到在某个父类找到为止。
class person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def whoami(self):
return "I am a person, my name is %s" %self.name
class student(person):
def __init__(self, name, age, score):
super(student, self).__init__(name, age)
self.score = score
# def whoami(self): #调用中一般先查找自身的定义,如果没有定义,顺着继承链向上查找,直到在person父类找到为止
# return "I am a student, my name is %s" %self.name
class teacher(person):
def __init__(self, name, age, course):
super(teacher, self).__init__(name, age)
self.course = course
def whoami(self):
return "I am a teacher, my name is %s" %self.name
def who_am_i(x):
print x.whoami()
p = person("yuhaohao", 20)
s = student("lim", 25, 90)
t = teacher("zhang",35, "english")
who_am_i(p)
who_am_i(s)
who_am_i(t)
多重继承:
class A(object):
def __init__(self, a):
print "init A..."
self.a = a
class B(A):
def __init__(self, a):
super(B, self).__init__(a)
print "init B..."
class C(A):
def __init__(self, a):
super(C, self).__init__(a)
print "init C..."
class D(B, C):
def __init__(self, a):
super(D, self).__init__(a)
print "init D..."
print (D.mro())
d = D('d')
输出结果为:
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <type 'object'>]
init A...
init C...
init B...
init D...
上面的mro用来定义继承方法的调用顺序,MRO采用广度优先的规则定义,按照广度优先的规则出来的顺序就是[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <type 'object'>] ,每次调用super()则是,调用MRO中下一个函数,上面的例子中,super(D, self)则指向MRO中的下一个类B-->于是调用B的init-->在B的init中,又调用super(),于是调用MRO的下一个类C-->在C的初始化中,又调用super()-->调用MRO的下一个函数A-->A调用下一个object,object什么有也未干-->返回A中,print init A...-->返回C中-->print init C...-->返回B中print init B...-->返回D中,print init D... 【执行顺序判断较为复杂,可以不必深入了解。我们可以通过mro()函数打印出来】
- 注意:super(type, obj).func()函数调用的是,obj实例在MRO中下一个父类的可调用func,而不是type的父类中的func()
调用关系如下图所示:
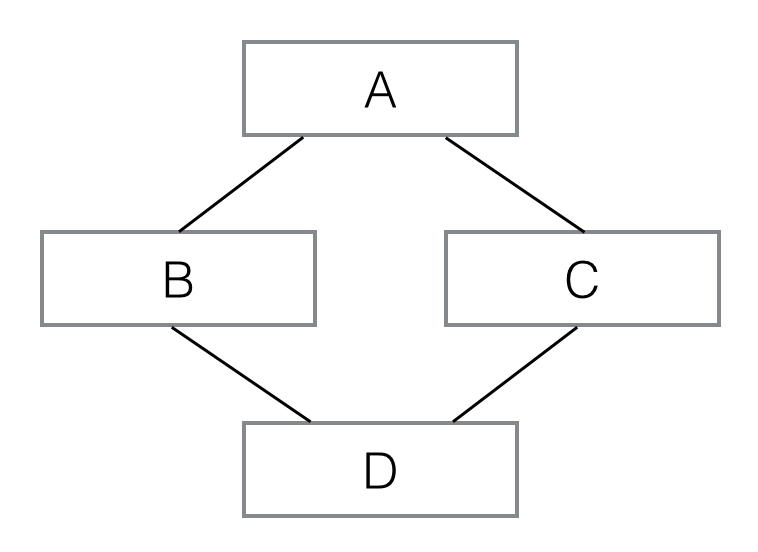
像这样,D同时继承自B和C,也就是D拥有了A、B、C的全部功能,多重继承通过super()调用__init__()方法时,A虽然被继承了两次,但__init__()只调用一次。
参考链接:http://www.cnblogs.com/Eva-J/p/5009377.html
参考链接:https://blog.csdn.net/simuLeo/article/details/80067619
参考链接:https://www.cnblogs.com/Nyan-Workflow-FC/p/5675461.html

