
scrapy

1. 创建项目
scrapy startproject <projectName>
2. 创建爬虫(项目目录下 cd <projectName>)
scrapy genspider <spiderName> <start_url>
3. 运行爬虫(项目目录下)
scrapy crawl <spiderName>
======
爬虫技巧
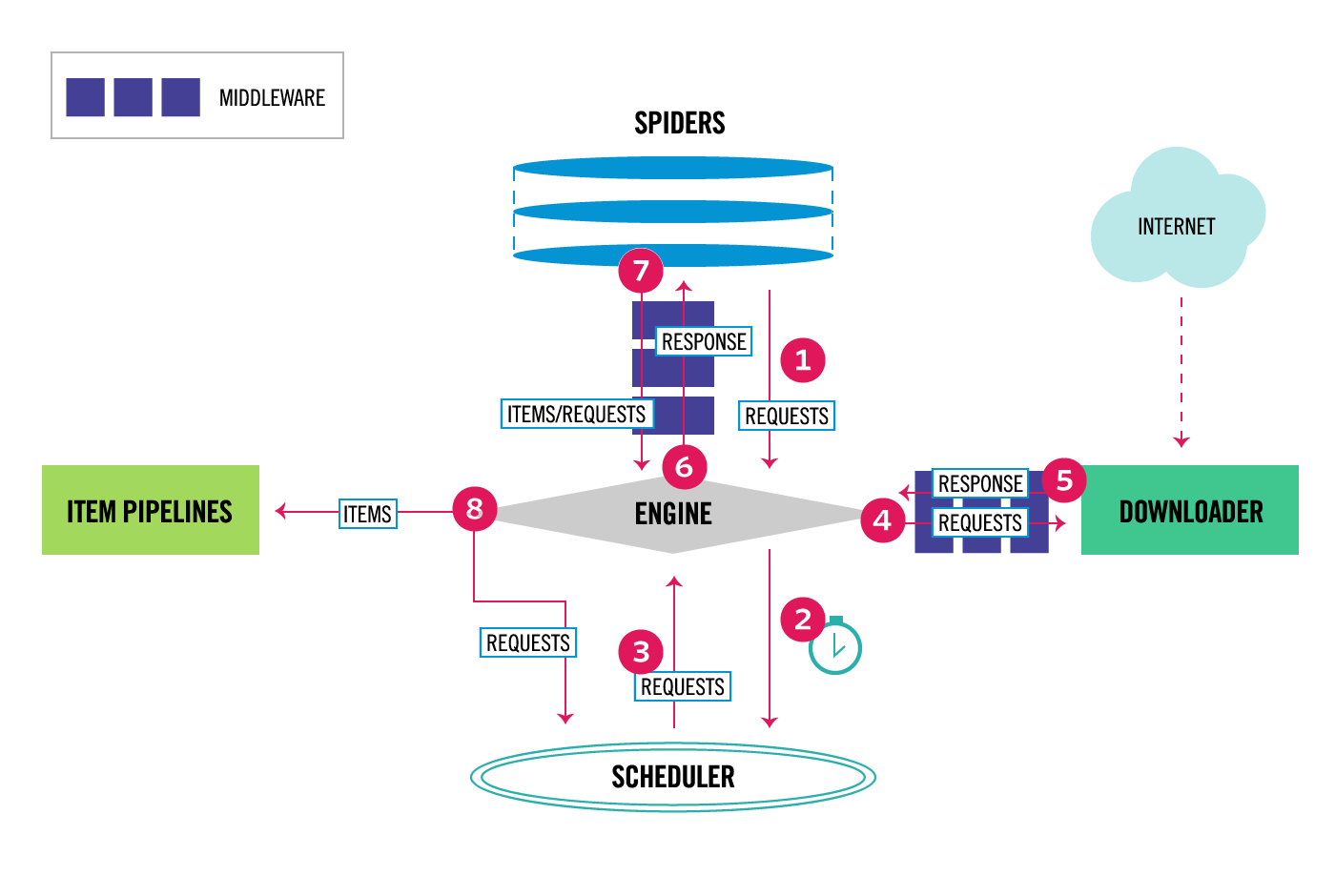
设置setting.py
1. 设置不遵循 ROBOTSTXT_OBEY
ROBOTSTXT_OBEY = False
2. 设置延时
DOWNLOAD_DELAY = 3
3. 设置 USER_AGENT 和 DEFAULT_REQUEST_HEADERS
1 # Crawl responsibly by identifying yourself (and your website) on the user-agent 2 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 3 4 # Override the default request headers: 5 DEFAULT_REQUEST_HEADERS = { 6 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 7 'Accept-Language': 'en', 8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 9 }
4. 设置 中间件(设置爬虫的headers和proxoy)
4.1 下载中间件 设置开启
// project_dir/settings.py
# Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'ADemo.middlewares.ProxyMilldeware': 301, # 下载中间件 [调度器与引擎之间的数据管道] }
// project_dir/middlewares.py
1 class ProxyMilldeware(object): # request 来自调度器 [用去处理或配置到下载器之前的 request 对象] 2 def process_request(self, request, spider): 3 # print('*'*100) 4 request.meta['proxy'] = 'http://127.0.0.1:1080' 5 request.headers.setdefault('User-Agent', '在这里设置成你的浏览器用户代理')
request.cookies = {'在这里设置你的cookies, 以字典的格式'} 6 7 def process_response(self, request, response, spider): # response 来自下载器 [用于处理下载器下载过来的 response 对象] 8 print(response.status) 9 print(response.text) 10 return response
4.2 爬虫中间件 设置开启
// project_dir/settings.py
1 # Enable or disable spider middlewares 2 # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 3 SPIDER_MIDDLEWARES = {5 'ADemo.middlewares.SpiderMiddleware': 543, # 爬虫中间件 [spider与引擎之间的数据管道] 6 }
5. 设置是否允许重定向,重试次数
// project_dir/settings.py
1 # 设置重试次数 2 RETRY_ENABLED = False 3 # RETRY_TIMES = 1 4 # RETRY_HTTP_CODECS = [400, 500] 5 6 # 设置重定向 7 REDIRECT_ENABLED = False
6. 日志
1 {'downloader/request_bytes': 288, # 请求字节数 2 'downloader/request_count': 1, # 请求次数 3 'downloader/request_method_count/GET': 1, # get 请求数 4 'downloader/response_bytes': 71860, # 响应字节数 5 'downloader/response_count': 1, # 响应次数 6 'downloader/response_status_count/200': 1, # 响应成功状态码为200的次数 7 'finish_reason': 'finished', # 结束原因: 运行完成! 8 'finish_time': datetime.datetime(2018, 1, 10, 6, 35, 53, 633178), # 程序结束时间 9 'log_count/DEBUG': 2, 10 'log_count/INFO': 7, 11 'response_received_count': 1, 12 'scheduler/dequeued': 1, 13 'scheduler/dequeued/memory': 1, 14 'scheduler/enqueued': 1, 15 'scheduler/enqueued/memory': 1, 16 'start_time': datetime.datetime(2018, 1, 10, 6, 35, 51, 585036)}
====== settings.py 示例文件 ======
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for ADemo project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # http://doc.scrapy.org/en/latest/topics/settings.html 9 # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html 10 # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'ADemo' 13 14 SPIDER_MODULES = ['ADemo.spiders'] 15 NEWSPIDER_MODULE = 'ADemo.spiders' 16 17 18 # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 20 21 # Obey robots.txt rules 22 ROBOTSTXT_OBEY = False # 一般设为False 23 24 # Configure maximum concurrent requests performed by Scrapy (default: 16) 25 #CONCURRENT_REQUESTS = 32 26 27 # Configure a delay for requests for the same website (default: 0) 28 # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay 29 # See also autothrottle settings and docs 30 DOWNLOAD_DELAY = 3 31 # The download delay setting will honor only one of: 32 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 33 #CONCURRENT_REQUESTS_PER_IP = 16 34 35 # Disable cookies (enabled by default) 36 #COOKIES_ENABLED = False 37 38 # Disable Telnet Console (enabled by default) 39 #TELNETCONSOLE_ENABLED = False 40 41 42 # Override the default request headers: 43 DEFAULT_REQUEST_HEADERS = { 44 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 45 'Accept-Language': 'en', 46 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 47 } 48 49 # Enable or disable spider middlewares 50 # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 51 SPIDER_MIDDLEWARES = { 52 # 'ADemo.middlewares.AdemoSpiderMiddleware': 543, 53 # 'ADemo.middlewares.SpiderMiddleware': 543, 54 } 55 56 # Enable or disable downloader middlewares 57 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html 58 DOWNLOADER_MIDDLEWARES = { 59 'ADemo.middlewares.ProxyMilldeware': 301, 60 } 61 62 # Enable or disable extensions 63 # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html 64 #EXTENSIONS = { 65 # 'scrapy.extensions.telnet.TelnetConsole': None, 66 #} 67 68 # Configure item pipelines 69 # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html 70 #ITEM_PIPELINES = { 71 # 'ADemo.pipelines.AdemoPipeline': 300, 72 #} 73 74 # Enable and configure the AutoThrottle extension (disabled by default) 75 # See http://doc.scrapy.org/en/latest/topics/autothrottle.html 76 #AUTOTHROTTLE_ENABLED = True 77 # The initial download delay 78 #AUTOTHROTTLE_START_DELAY = 5 79 # The maximum download delay to be set in case of high latencies 80 #AUTOTHROTTLE_MAX_DELAY = 60 81 # The average number of requests Scrapy should be sending in parallel to 82 # each remote server 83 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 84 # Enable showing throttling stats for every response received: 85 #AUTOTHROTTLE_DEBUG = False 86 87 # Enable and configure HTTP caching (disabled by default) 88 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 89 #HTTPCACHE_ENABLED = True 90 #HTTPCACHE_EXPIRATION_SECS = 0 91 #HTTPCACHE_DIR = 'httpcache' 92 #HTTPCACHE_IGNORE_HTTP_CODES = [] 93 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' 94 95 # 设置重试次数 96 RETRY_ENABLED = True 97 RETRY_TIMES = 2 98 # RETRY_HTTP_CODECS = [320, 500] 99 100 # 设置重定向 101 # REDIRECT_ENABLED = False
// 分布式爬虫,配置 redis
# SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# REDIS_URL = "redis://user:password@host:port"
cookies的处理 [将前端浏览器request请求头中的headers字符串中的cookies字符串复制给cookies]
1 cookies_string = '__utma=160444991.1773391101.1513841173.1515472372.1515564585.4; __utmc=160444991; __utmz=160444991.1515564585.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic' 2 cookies = {} 3 for item in cookies_string.split(';'): 4 key = item.split('=')[0].strip() 5 value = item.split('=')[1].strip() 6 cookies[key] = value
7 print(cookies)
headers的处理 [将前端浏览器request请求头中的headers字符串复制给headers_string]
1 headers_string = '' 2 headers = {} 3 for item in headers_string.split('\n'): 4 lst = item.split(':') 5 key = lst[0].strip() 6 value = lst[1] 7 headers[key] = value.strip() 8 print(headers)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号