相关分析
相关分析
相关分析:
- 衡量事物之间或称变量之间线性相关程度的强弱,并用适当的统计指标表示出来的过程。
- 比如,家庭收入和支出、一个人所受教育程度与其收入、子女身高和父母身高等
相关系数:
- 衡量变量之间相关程度的一个量值
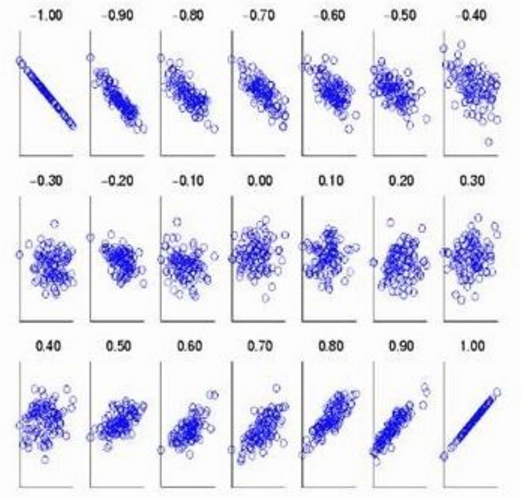
- 相关系数r的数值范围是在一1到十1之间
- 相关系数r的正负号表示变化方向。“+”号表示变化方向一致,即正相关;“-”号表示变化方向相反,即负相关
- r的绝对值表示变量之间的密切程度(即强度)。绝对值越接近1,表示两个变量之间关系越密切;越接近0,表示两个变量之间关系越不密切
- 相关系数的值,仅仅是一个比值。它不是由相等单位度量而来(即不等距),也不是百分比,因此,不能直接作加、减、乘、除运算
- 相关系数只能描述两个变量之间的变化方向及密切程度,并不能揭示两者之间的内在本质联系,即存在相关的两个变量,不一定存在因果关系
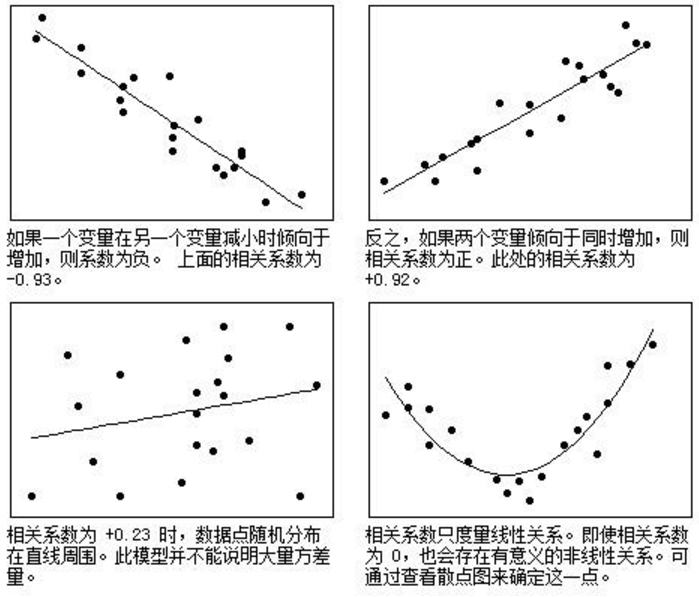
连续变量的相关分析
-
连续变量即数据变量,它的取值之间可以比较大小,可以用加减法计算出差异的大小。如“年龄”、“收入”、“成绩”等变量。
-
当两个变量都是正态连续变量,而且两者之间呈线性关系时,通常用Pearson相关系数来衡量
皮尔森Pearson相关系数
协方差:
协方差是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值
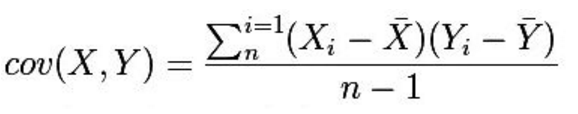
虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的关联程度。
在二维空间中分布着一些数据,我们想知道数据点坐标X轴和Y轴的相关程度,如果X与Y的相关程度较小但是数据分布的比较离散,这样会导致求出的协方差值较大,用这个值来度量相关程度是不合理的
为了更好的度量两个随机变量的相关程度,引入了Pearson相关系数,其在协方差的基础上除以了两个随机变量的标准差
pearson相关系数
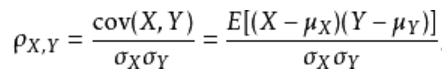
pearson是一个介于-1和1之间的值,当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
np.corrcoef(a)可计算行与行之间的相关系数,np.corrcoef(a,rowvar=0)用于计算各列之间的相关系数
import numpy as np
tang = np.array([[10, 10, 8, 9, 7],
[4, 5, 4, 3, 3],
[3, 3, 1, 1, 1]])
tang
输出:
array([[10, 10, 8, 9, 7],
[ 4, 5, 4, 3, 3],
[ 3, 3, 1, 1, 1]])
np.corrcoef(tang)
输出:
array([[ 1. , 0.64168895, 0.84016805],
[ 0.64168895, 1. , 0.76376262],
[ 0.84016805, 0.76376262, 1. ]])
np.corrcoef(tang,rowvar=0)
输出:
array([[ 1. , 0.98898224, 0.9526832 , 0.9939441 , 0.97986371],
[ 0.98898224, 1. , 0.98718399, 0.99926008, 0.99862543],
[ 0.9526832 , 0.98718399, 1. , 0.98031562, 0.99419163],
[ 0.9939441 , 0.99926008, 0.98031562, 1. , 0.99587059],
[ 0.97986371, 0.99862543, 0.99419163, 0.99587059, 1. ]])
伦敦的月平均气温与降水量

计算伦敦市月平均气温(t)与降水量(p)之间的相关系数
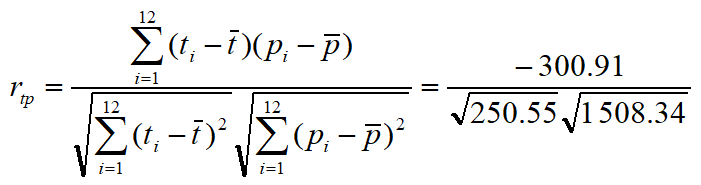
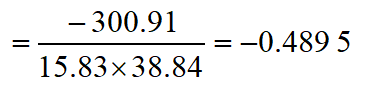
计算结果表明,伦敦市的月平均气温(t)与降水量(p)之间呈负相关,即异向相关
相关系数的显著性检验
假设
- H0: ρ=0
- H1: ρ≠0
统计量
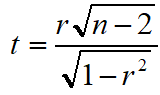
10个学生初一数学分数与初二数学分数的相关系数为0.87,问从总体上来说,初一与初二数学分数是否存在相关?
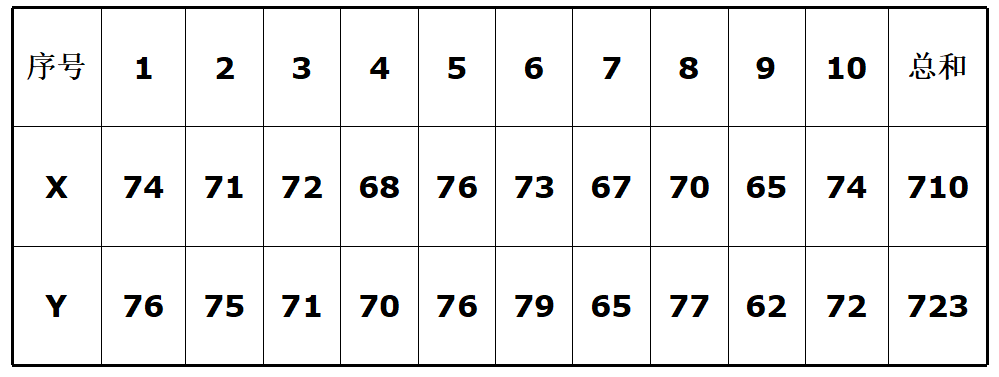
计算检验统计量:
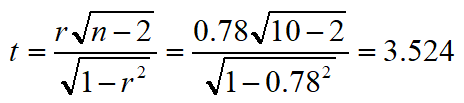
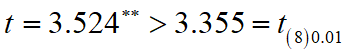
所以,从总体上说,初一数学分数与初二数学分数存在正相关。
import numpy as np
import scipy.stats as stats
import scipy
# https://docs.scipy.org/doc/scipy-0.19.1/reference/stats.html#module-scipy.stats
x = [10.35, 6.24, 3.18, 8.46, 3.21, 7.65, 4.32, 8.66, 9.12, 10.31]
y = [5.1, 3.15, 1.67, 4.33, 1.76, 4.11, 2.11, 4.88, 4.99, 5.12]
correlation,pvalue = stats.stats.pearsonr(x,y)
print ('correlation',correlation)
print ('pvalue',pvalue)
输出:
correlation 0.989176319869
pvalue 5.92687594648e-08
import matplotlib.pyplot as plt
plt.scatter(x,y)
plt.show()
输出:
等级变量的相关分析
当测量得到的数据不是等距或等比数据,而是具有等级顺序的数据;或者得到的数据是等距或等比数据,但其所来自的总体分布不是正态的,不满足求皮尔森相关系数(积差相关)的要求。这时就要运用等级相关系数。
先来看一个小实验,两个基因A、B,他们的表达量关系是B=2A,在8个样本中的表达量值如下:

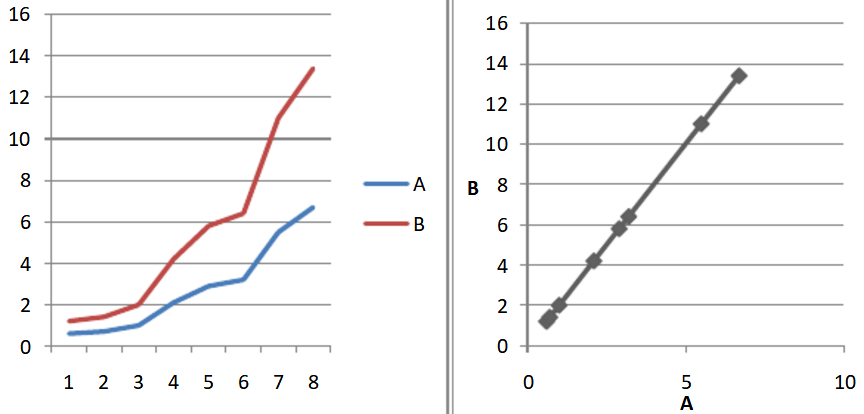
计算得出,他们的皮尔森相关系数r=1,P-vlaue≈0,从以上可以直观看出,如果两个基因的表达量呈线性关系,则具有显著的皮尔森相关性。
以上是两个基因呈线性关系的结果。如果两者呈非线性关系,例如幂函数关系(曲线关系),那又如何呢? 我们再试试。
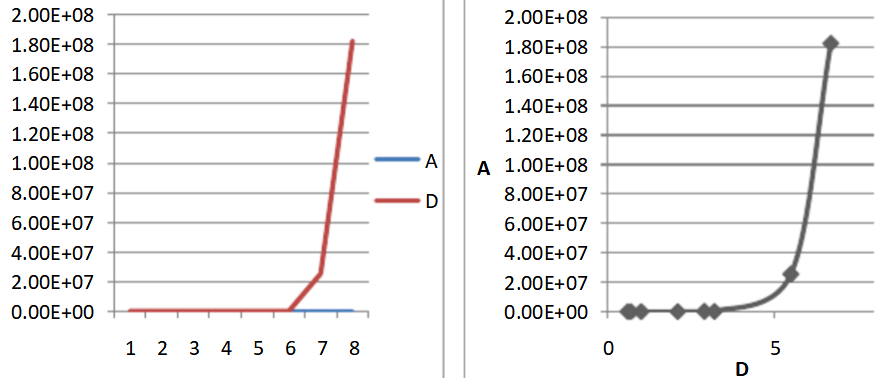
两个基因A、D,他们的关系是D=A^10,在8个样本中的表达量值如下:

import numpy as np
import scipy.stats as stats
import scipy
x = [0.6,0.7,1,2.1,2.9,3.2,5.5,6.7]
y = np.power(x,10)
correlation,pvalue = stats.stats.pearsonr(x,y)
print ('correlation',correlation)
print ('pvalue',pvalue)
输出:
correlation 0.765928796314
pvalue 0.0266964972088
可以看到,基因A、D相关系数,无论数值还是显著性都下降了。皮尔森相关系数是一种线性相关系数,因此如果两个变量呈线性关系的时候,具有最大的显著性。对于非线性关系(例如A、D的幂函数关系),则其对相关性的检测功效会下降。
这时我们可以考虑另外一个相关系数计算方法:斯皮尔曼等级相关。
斯皮尔曼等级相关
当两个变量值以等级次序排列或以等级次序表示时,两个相应总体并不一定呈正态分布,样本容量也不一定大于30,表示这两变量之间的相关,称为Spearman等级相关。
简单点说,就是无论两个变量的数据如何变化,符合什么样的分布,我们只关心每个数值在变量内的排列顺序。如果两个变量的对应值,在各组内的排序顺位是相同或类似的,则具有显著的相关性。
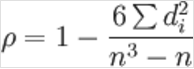
- n为等级个数
- d为二列成对变量的等级差数
将上表转换成排序等级
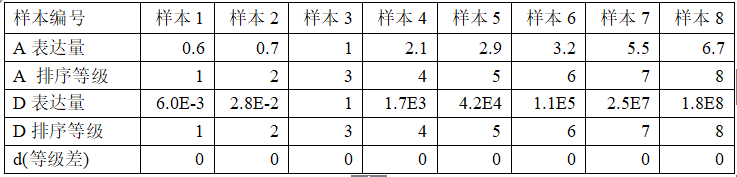
利用斯皮尔曼等级相关计算A、D基因表达量的相关性,结果是:r=1,p-value = 4.96e-05
这里斯皮尔曼等级相关的显著性显然高于皮尔森相关。这是因为虽然两个基因的表达量是非线性关系,但两个基因表达量在所有样本中的排列顺序是完全相同的,因为具有极显著的斯皮尔曼等级相关性。
x = [10.35, 6.24, 3.18, 8.46, 3.21, 7.65, 4.32, 8.66, 9.12, 10.31]
y = [5.13, 3.15, 1.67, 4.33, 1.76, 4.11, 2.11, 4.88, 4.99, 5.12]
correlation,pvalue = stats.stats.spearmanr(x,y)
print ('correlation',correlation)
print ('pvalue',pvalue)
输出:
correlation 1.0
pvalue 6.64689742203e-64
x = [10.35, 6.24, 3.18, 8.46, 3.21, 7.65, 4.32, 8.66, 9.12, 10.31]
y = [5.13, 3.15, 1.67, 4.33, 1.76, 4.11, 2.11, 4.88, 4.99, 5.12]
x = scipy.stats.stats.rankdata(x)
y = scipy.stats.stats.rankdata(y)
print (x,y)
correlation,pvalue = stats.stats.spearmanr(x,y)
print ('correlation',correlation)
print ('pvalue',pvalue)
输出:
[ 10. 4. 1. 6. 2. 5. 3. 7. 8. 9.] [ 10. 4. 1. 6. 2. 5. 3. 7. 8. 9.]
correlation 1.0
pvalue 6.64689742203e-64
斯皮尔曼实例
10名高三学生学习潜在能力测验与自学能力测验成绩如下表所示,问两者相关情况如何?
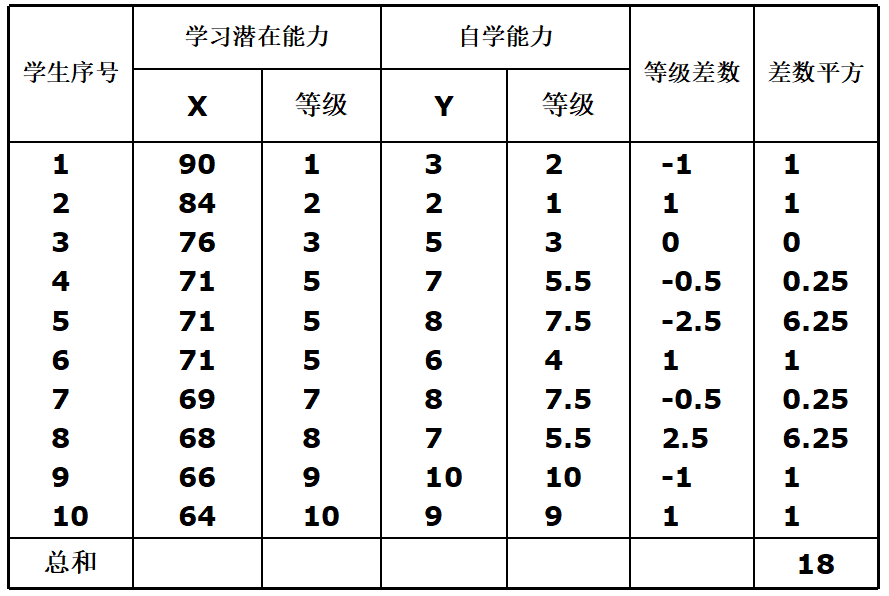
计算等级相关系数
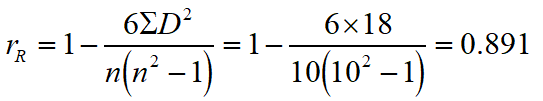
等级相关系数的显著性检验
- 与积差相关系数检验的方法相同
10个学生学习潜在能力与自学能力测验成绩相关系数为0.891,问从总体上说,两者是否存在相关?
计算检验统计量的值:
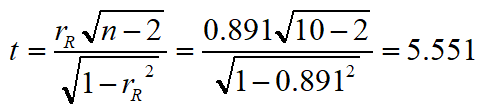
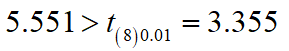
所以学生的学习潜在能力与自学能力之间存在着较高的正相关。
肯德尔和谐系数(Kendall)
当多个(两个以上)变量值以等级次序排列或以等级次序表示,描述这几个变量之间的一致性程度的量,称为肯德尔和谐系数。它常用来表示几个评定者对同一组学生成绩用等级先后评定多次之间的一致性程度。
同一评价者无相同等级评定时,计算公式:
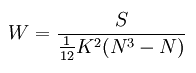
- N—被评的对象数;
- K—评分者人数或评分所依据的标准数;
- S—每个被评对象所评等级之和Ri与所有这些和的平均数的离差平方和
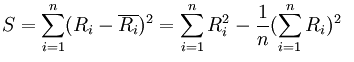
当评分者意见完全一致时,S取得最大值,和谐系数是实际求得的S与其最大可能取值的比值,故0≤W≤1。
同一评价者有相同等级评定时,计算公式
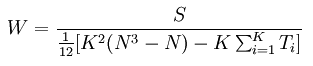
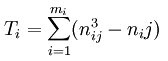
- mi为第i个评价者的评定结果中有重复等级的个数。
- nij为第i个评价者的评定结果中第j个重复等级的相同等级数。
- 对于评定结果无相同等级的评价者,Ti = 0,因此只须对评定结果有相同等级的评价者计算Ti。
实例1:同一评价者无相同等级评定时
某校开展学生小论文比赛,请6位教师对入选的6篇论文评定得奖等级,结果如下表所示,试计算6位教师评定结果的kandall和谐系数。
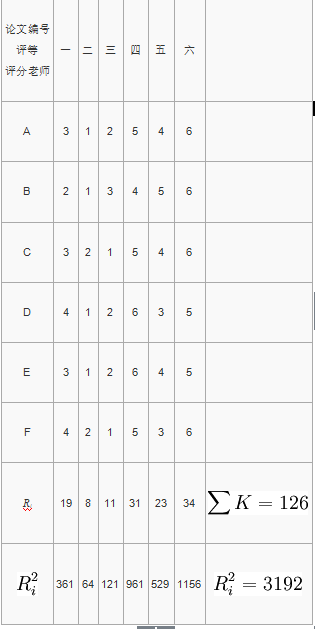
由于每个评分老师对6篇论文的评定都无相同的等级:
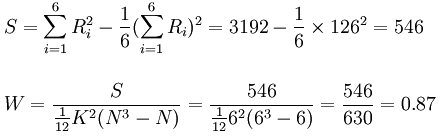
由W=0.87表明6位老师的评定结果有较大的一致性
实例2:同一评价者有相同等级评定时
3名专家对6篇心理学论文的评分经等级转换如下表所示,试计算专家评定结果的肯德尔和谐系数
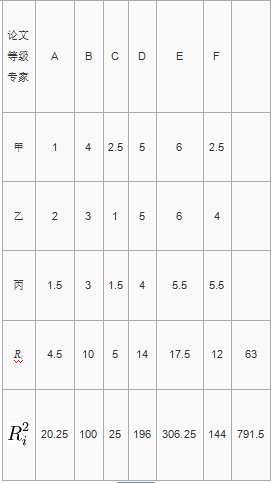
由于专家甲、丙对6篇论文有相同等级的评定
甲T = 23 − 2 = 6
丙T = (23 − 2) + (23 − 2) = 12
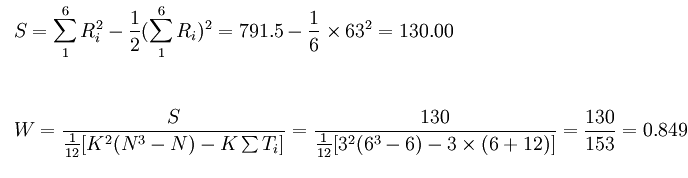
由W=0.85可看出专家评定结果有较大的一致性
肯德尔和谐系数的显著性检验
评分者人数(k)在3-20之间,被评者(N)在3-7之间时,可查《肯德尔和谐系数(W)显著性临界值表》,检验W是否达到显著性水平。若实际计算的S值大于k、N相同的表内临界值 ,则W达到显著水平。
当K=6 N=6,查表得检验水平分别为α = 0.01,α = 0.05的临界值各为S0.01 = 282.4,S0.05 = 221.4,均小于实算的S=546,故W达到显著水平,认为6位教师对6篇论文的评定相当一致。
当被评者n>7时,则可用如下的x2统计量对W是否达到显著水平作检验。
x1 = [10, 9, 8, 7, 6]
x2 = [10, 8, 9, 6, 7]
tau, p_value = stats.kendalltau(x1, x2)
print ('tau',tau)
print ('p_value',p_value)
输出:
tau 0.6
p_value 0.141644690295
质量相关分析
质量相关是指一个变量为质,另一个变量为量,这两个变量之间的相关。如智商、学科分数、身高、体重等是表现为量的变量,男与女、优与劣、及格与不及格等是表现为质的变量。
质与量的相关主要包括二列相关、点二列相关、多系列相关。
二列相关
当两个变量都是正态连续变量.其中一个变量被人为地划分成二分变量(如按一定标推将属于正态连续变量的学科考试分数划分成及格与不及格,录取与未录取,把某一体育项目测验结果划分成通过与未通过,达标与末达标,把健康状况划分成好与差,等等),表示这两个变量之间的相关,称为二列相关。
二列相关的使用条件:
- 两个变量都是连续变量,且总体呈正态分布,或总体接近正态分布,至少是单峰对称分布。
- 两个变量之间是线性关系。
- 二分变量是人为划分的,其分界点应尽量靠近中值。
- 样本容量应当大于80。

二列相关实例:
10名考生成绩如下,包括总分和一道问答题,试求该问答题的区分度(6分以上为通过,包括6分)

问答题,被人为的分成两类,通过和不通过,应求二列相关。

区分度略高
点二列相关
当两个变量其中一个是正态连续性变量,另一个是真正的二分名义变量(例如,男与女,已婚和未婚,色盲与非色盲,生与死,等等),这时,表示这两个变量之间的相关,称为点二列相关。

点二列相关实例:
有50道选择题,每题2分,有20人的总成绩和第五题的情况,第五题与总分的相关程度如何。
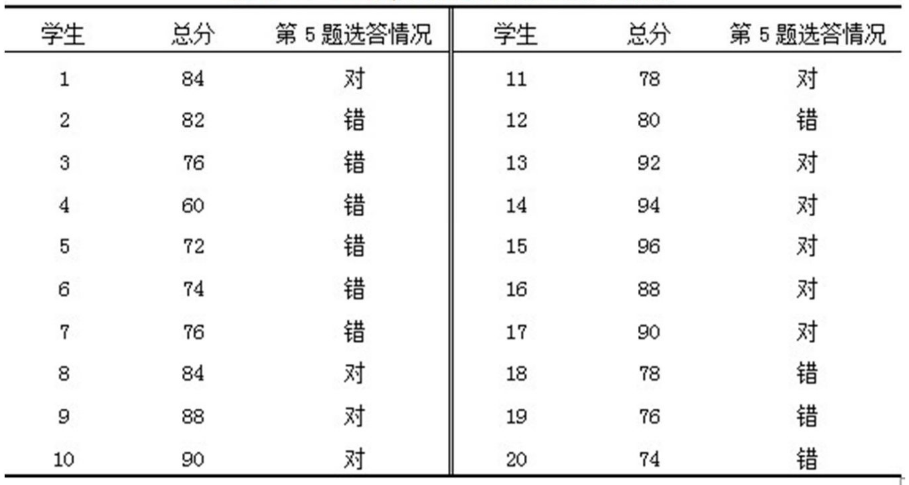
p(答对学生的比例) = 10/20 = 0.5 ,q = 1-p = 0.5
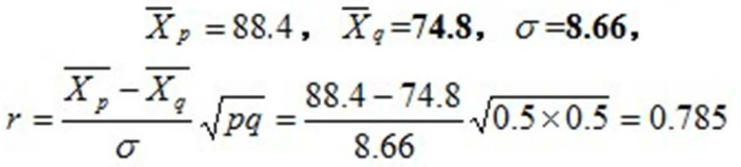
相关系数较高,第五题的情况与总分有一致性(区分度较高)
x = [1,0,0,0,0,0,0,1,1,1,1,0,1,1,1,1,1,0,0,0]
y = [84,82,76,60,72,74,76,84,88,90,78,80,92,94,96,88,90,78,76,74]
stats.pointbiserialr(x, y)
输出:
PointbiserialrResult(correlation=0.7849870641173371, pvalue=4.1459279734903919e-05)
品质相关分析
两个变量都是按质划分成几种类别,表示这两个变量之间的相关称为品质相关。
如,一个变量按性别分成男与女,另一个变量按学科成绩分成及格与不及格;又如,一个变量按学校类别分成重点及非重点,另一个变量按学科成绩分成优、良、中、差,等等。
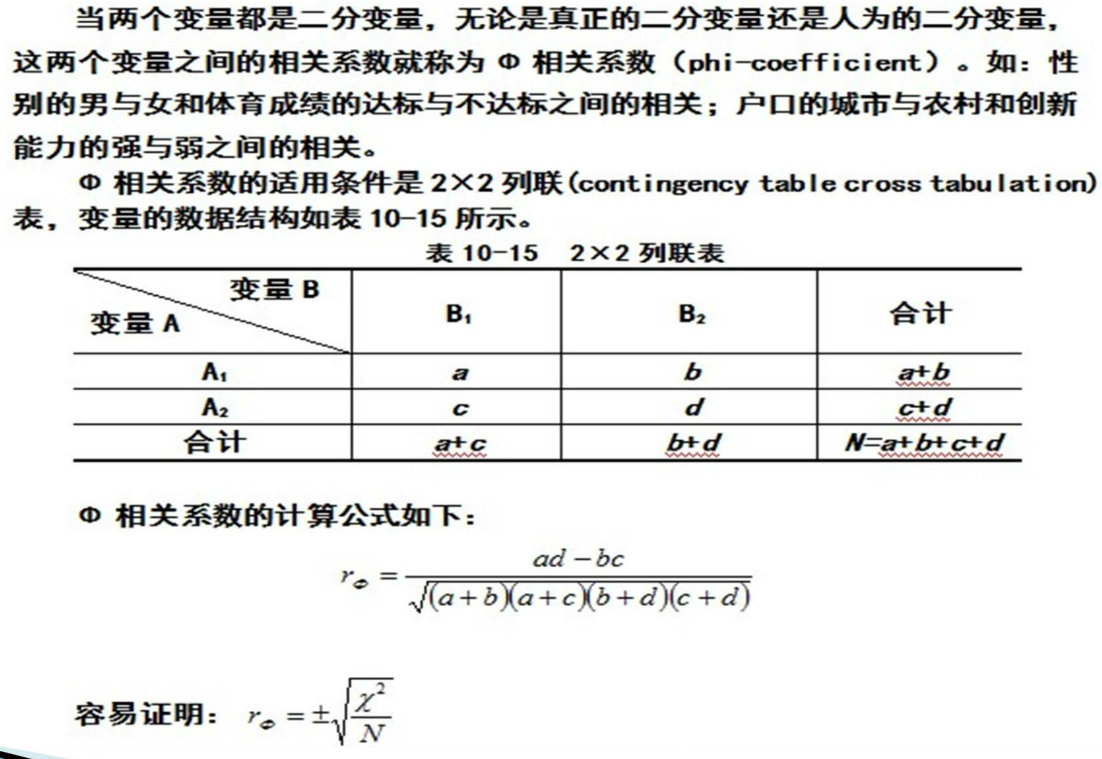
列联相关系数

2531名学生和教师进行了抽样调查,计算调查对象和态度之间的列联相关系数,并进行统计显著检验
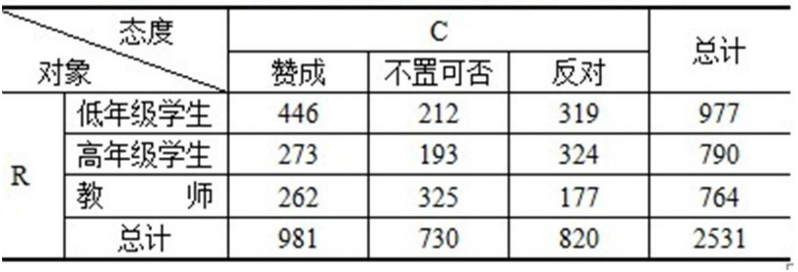

φ相关
为了研究青年大学生对性别与对心里测验态度的关系,选取了170名青年进行心里测验,计算性别对测验态度的φ相关系数

偏相关分析
在多要素所构成的一个系统中,先不考虑其它要素的影响,而单独研究两个要素之间的相互关系的密切程度,这称为偏相关。用以度量偏相关程度的统计量,称为偏相关系数。
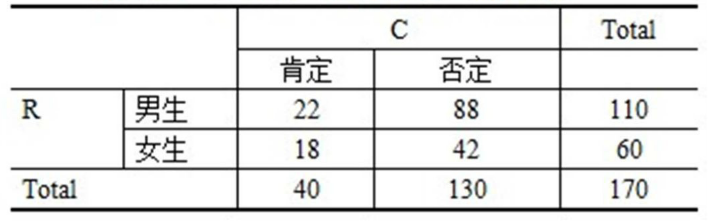
在分析变量x1和x2之间的净相关时,当控制了变量x3的线性作用后,x1和x2之间的一阶偏相关系数定义为:
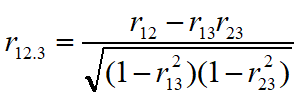
对于某四个地理要素x1,x2,x3,x4的23个样本数据,经过计算得到了如下的单相关系数矩阵:
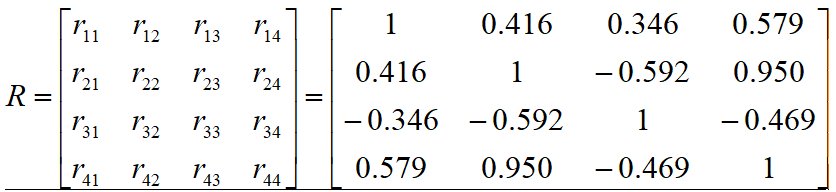
计算可得部分偏相关系数:

偏相关系数的性质
- 偏相关系数分布的范围在-1到1之间
- 偏相关系数的绝对值越大,表示其偏相关程度越大
- 偏相关系数的绝对值必小于或最多等于由同一系列资料所求得的复相关系数,即 R1·23≥|r12·3|
偏相关系数的显著性检验

- n:样本容量
- k是剔除了的变量数
- r是偏相关系数
当有3个要素时,有三个偏相关系数,称为一级偏相关系数
当有4个要素时,则有六个偏相关系数,则称他们为二级偏相关系数
复相关系数
-
反映几个要素与某一个要素之间 的复相关程度。复相关系数介于0到1之间。
-
复相关系数越大,则表明要素(变量)之间的相关程度越密切。复相关系数为1,表示完全相关;复相关系数为0,表示完全无关。
-
复相关系数必大于或至少等于单相关系数的绝对值。
测定一个变量y,当有两个自变量时:
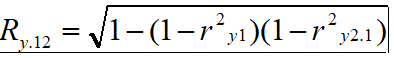
当有三个自变量时:
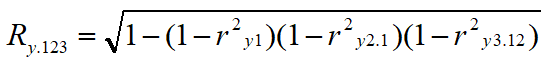
实例:
在上例中,若以x4为因变量,x1,x2,x3为自变量,试计算x4与x1,x2,x3之间的复相关系数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号