4.4.1 12306抢票
4.4.1 12306抢票[1]
可以学习到selenium的ActionChains,Keys,Select的使用
from selenium.webdriver import Chrome, ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
# 根据xpath找到元素:
driver.find_element_by_xpath("/html/body/div[2]/div[2]/ul/li[2]/a").click()
driver.find_elements_by_xpath('//*[@id="queryLeftTable"]/tr[not(@datatran)]')
tr.find_element_by_xpath("./td[1]/div/div[1]/div/a").text
# 根据类名找到元素:注意element与elements
driver.find_element_by_class_name("ok").click()
driver.find_elements_by_class_name("active")[1].click()
# 根据id查找并发送值
driver.find_element_by_id("J-userName").send_keys(username)
# Keys使用
from_input = driver.find_element_by_id("fromStationText")
from_input.click()
from_input.send_keys(from_station)
from_input.send_keys(Keys.ENTER) # 回车失去焦点
# 切换标签页
driver.switch_to.window(driver.window_handles[-1])
# 下拉菜单选择
seat_type = driver.find_element_by_id("seatType_1")
seat_type.click()
# ActionChains使用
ActionChains(driver).move_to_element_with_offset(img, x+10, y+30).click().perform()
span = driver.find_element_by_id("nc_1_n1z")
action = ActionChains(driver)
action.click_and_hold(span) # 点击并保持
action.move_by_offset(350, 0).perform() # x轴移动350, y轴移动为0
# 执行脚本:
driver.execute_script('document.getElementById("train_date").removeAttribute("autocomplete")') # 取消标签只读模式
预先使用账号登录12306,将乘车人信息录入。
查询余票
打开12306网站,输入出发地、到达地、出发日期,进行查询:
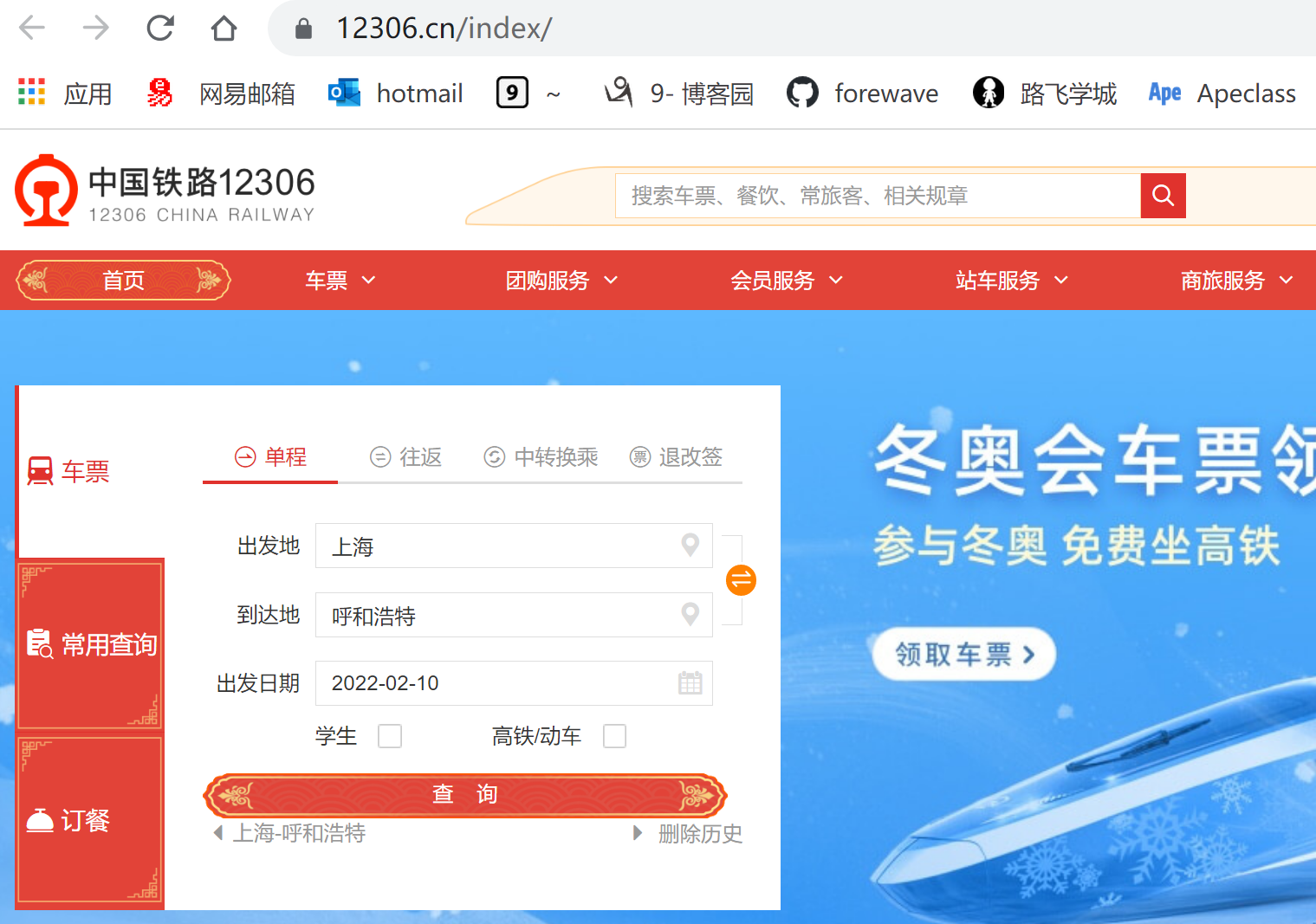
F12,查询请求相关信息:
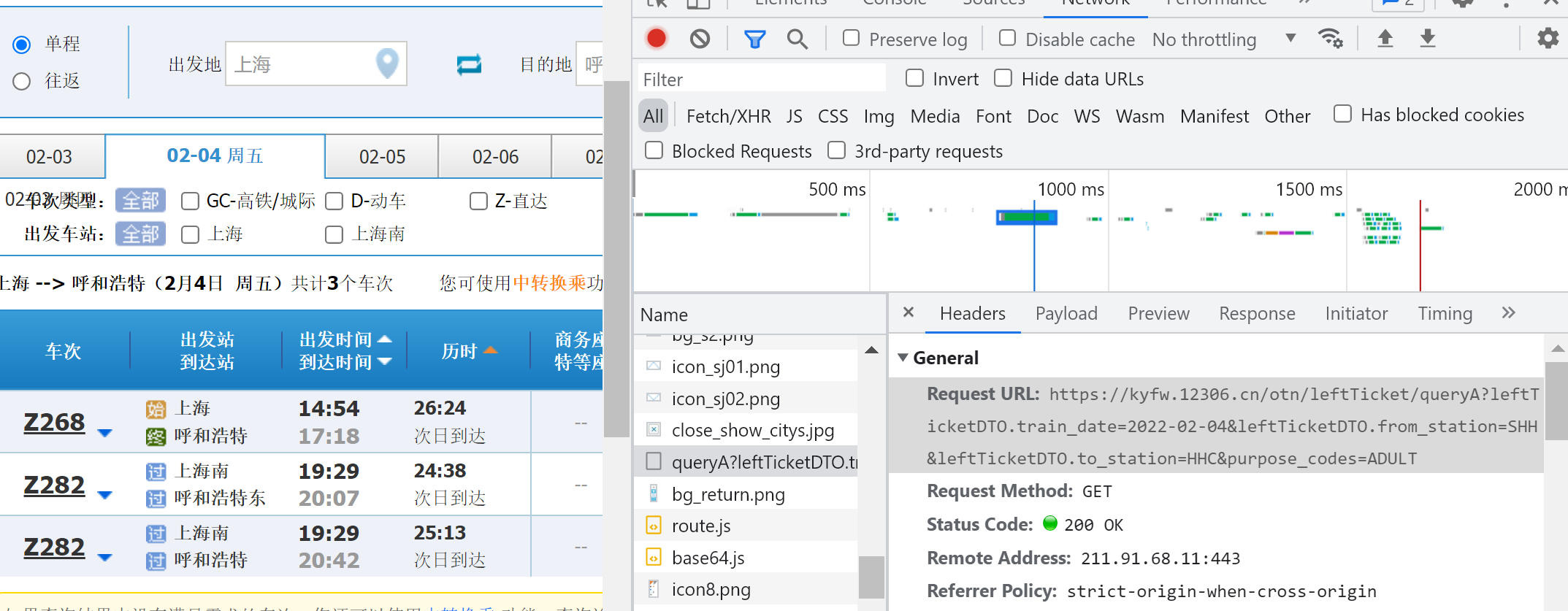
可以看到请求的URL为:
其中leftTicketDTO.train_date=2022-02-10,出发日期即为输入日期,但&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=HHC中的出发地和到达地却不是输入汉字而变为字母代号,所以需要把输入汉字转换为字母代号。往上查看,可以看到有station_name.js和favorite_name.js两个js文件,都是处理站名转换的。其请求URL为:
https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9226
https://kyfw.12306.cn/otn/resources/js/framework/favorite_name.js
有了URL就可以发请求进行站名转换了,得到应答为:
var station_names ='@bjb|北京北|VAP|beijingbei|bjb|0@bjd|北京东|BOP|beijingdong|bjd|1@bji|北京|BJP|beijing|bj|2@bjn|北京南|VNP|beijingnan|bjn|3@bjx|北京西|BXP|beijingxi|bjx|4
...
可见用@和| split后就可以得到转换对应,填入查询请求URL,开始进行余票查询,得到应答:
['jqez6%2B4XWDs2BkXxnOLS%2FoMal6q5kxAGCRf3ucl8D%2Fe0rSllnpdy%2BJ5AZQmQNnwTIFPIa9aeaQhB%0AweCKImEsSgyNkDwaMx3ZlvjqgzdGsE5aPuYzcOzDM5ghfQVn%2Buk7ek1hHvUIw%2BB7MB6wYsSNZgWn%0AVGivkfVeGI9H5sDvayZXW3sonXQZdanfG%2F0LoZvA3HzAoK%2FS4Az1xK4RWUSZtjyYrw2rzoI%2FZSgZ%0AadRBQdH6PaXbSDKaTsxDxveQxxWVITH9X7D%2F1MhKORonhq4wqst0i75qWwNXrn4teRvjbJaNClRM%0AoCosWjoOY2L9H1jfolcA%2FrTR5PXr2uWVPqOgZw%3D%3D|预订|550000Z26808|Z268|SHH|HHC|SHH|HHC|14:54|17:18|26:24|Y|jqkA2LLJoebavG0QdGEYc2Cak3lym2tgCsL6VQIeNrfxyob1SYKpvcZp1m659Rz8hHKF%2FmWd5ik%3D|20220211|3|H1|01|28|1|0||无||14|||无||10|无|||||60403010W0|64311|1|1||61274500004068750014304345001010254500001025453000|0|||||1|#0#0#0||7',
...
可以看出Z268|SHH|HHC|SHH|HHC|14:54|17:18|26:24,第3项为车次,第8,9,10项分别是出发时间、到达时间、历时时长。但其后的信息很难看出商务座、一等座、硬卧等的对应,在js代码找了一会没搞明白。对应实际查询显示应该能找出对应关系但笨拙又费时,就百度了一下别人的实现,找到了对应:
seat = {
21:'高级软卧',
23:'软卧',
26:'无座',
28:'硬卧',
29:'硬座',
30:'二等座',
31:'一等座',
32:'商务座',
33:'动卧'
}
这样解析响应可以得到余票查询结果:
2022-02-11 上海->呼和浩特 查询成功!
Z268车次还有余票.
出发时间:14:54 到达时间:17:18 历时时长:26:24 软卧:有14张票 硬卧:有10张票
Z282车次还有余票.
出发时间:19:29 到达时间:20:07 历时时长:24:38 软卧:有7张票 硬卧:有票 硬座:有票
Z282车次还有余票.
出发时间:19:29 到达时间:20:42 历时时长:25:13 软卧:有7张票 硬卧:有票 硬座:有票
模拟登录
- 通过selemium打开一个登录浏览窗口
- 防止12306禁止selemium
实际操作登录,记录过程如下:
- 点击账号登录,输入用户名密码
保存图片验证码(以前12306有,现在好像没有了,不知是不是访问多了才会出现)识别验证码的图片- 模拟点击效果,立即登录
- 弹出滑动验证码,破解,完成登录
1.通过selemium打开一个登录浏览窗口
https://kyfw.12306.cn/otn/resources/login.html
遇到了“selenium.common.exceptions.WebDriverException: Message: ‘chromedriver...”的异常,是Chrome驱动不匹配所致,Baidu搜索搞定。
# 1. 通过selemium打开一个登录浏览窗口
driver = Chrome()
driver.maximize_window()
driver.get("https://kyfw.12306.cn/otn/resources/login.html")
2.防止12306禁止selemium
# 2. 防止12306禁止selemium
script = "Object.defineProperty(navigator, 'webdriver', {get:()=>undefined,});"
driver.execute_script(script)
3.点击账号登录,输入用户名密码
F12,找到用户名框,密码框,立即登录按钮等id:
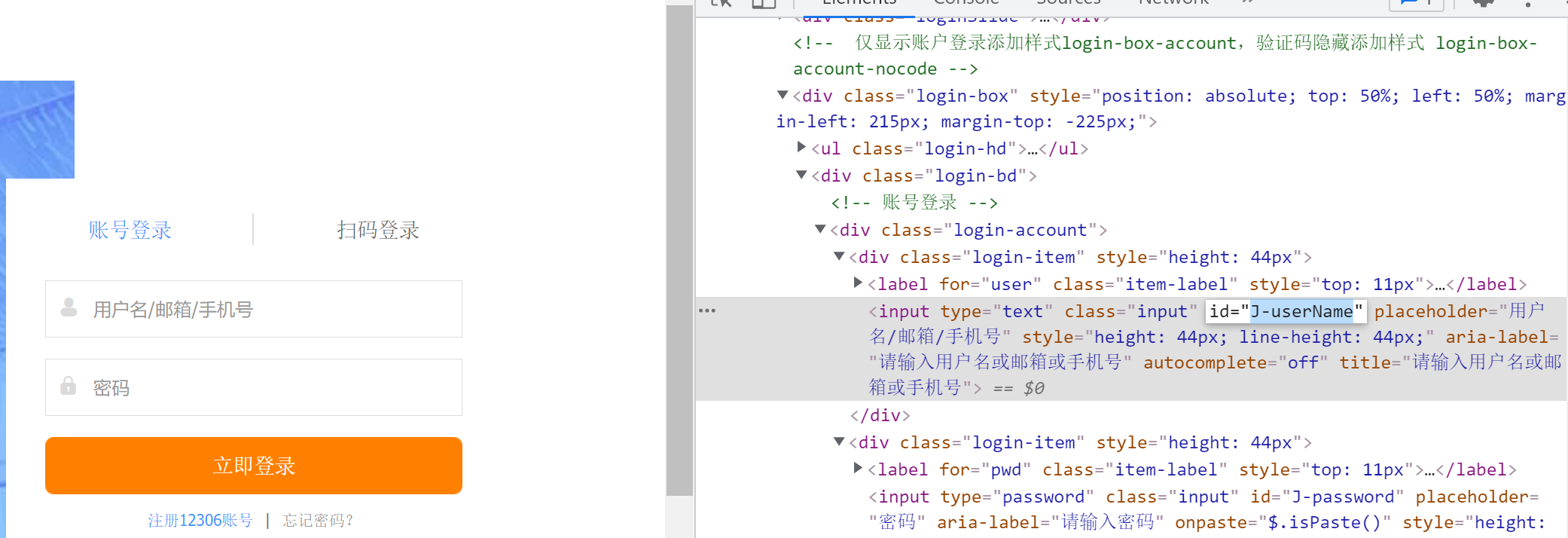
# 3. 点击账号登录,输入用户名密码
# 输入账号密码
driver.find_element_by_id("J-userName").send_keys(username)
time.sleep(1)
driver.find_element_by_id("J-password").send_keys(password)
time.sleep(1)
4.保存图片验证码[2]
F12,找到图片的id,根据src属性的url,将图片base64解密后保存为文件,供第三方接口识别。
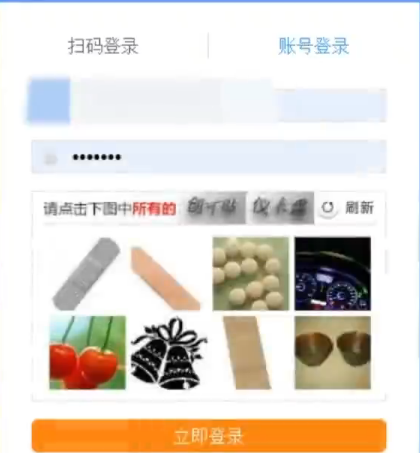
# 4. 保存图片验证码
# img = driver.find_element_by_id("J-loginImg")
# pic_url = img.get_attribute("src")
# pic = base64.b64decode(pic_url.split(',')[1]) # 去除逗号前的"data:image/jpg;base64," 无用数据
# with open("pic.png","wb") as f:
# f.write(pic)
5.识别验证码的图片
将保存图片发给第三方接口识别,会返回正确图片的序号。根据序号及每张图片的坐标,正确点击通过图片验证。
# 5. 识别验证码的图片
# answer_list = discern_captcha()
# for l in answer_list:
# x = l[0]
# y = l[1]
#
# ActionChains(driver).move_to_element_with_offset(img, x+10, y+30).click().perform()
# time.sleep(1)
def discern_captcha():
''' 通过第三方接口识别图片验证码 '''
url_captcha = "http://littlebigluo.qicp.net:47720/"
files = {
"pic_xxfile": open("pic.png", "rb")
}
res = requests.post(url=url_captcha, files=files, verify=False)
img_num = re.search("<B>(.*?)</B>", res).group(1).replace(" ",",")
img_num_list = img_num.split(",")
answer_list = []
# 图片坐标
coordinate = {
'1': (31,35),
'2': (116,46),
'3': (191,24),
'4': (243,50),
'5': (22,114),
'6': (117,94),
'7': (167,120),
'8': (251,105),
}
# 循环遍历,构建数据结构[[x1,y1], [x2,y2]...]
for i in img_num_list:
x_y = []
x_y.append(coordinate[i][0])
x_y.append(coordinate[i][1])
answer_list.append(x_y)
return answer_list
6.模拟点击效果,立即登录
F12,找到立即登录按钮的id,模拟点击登录。
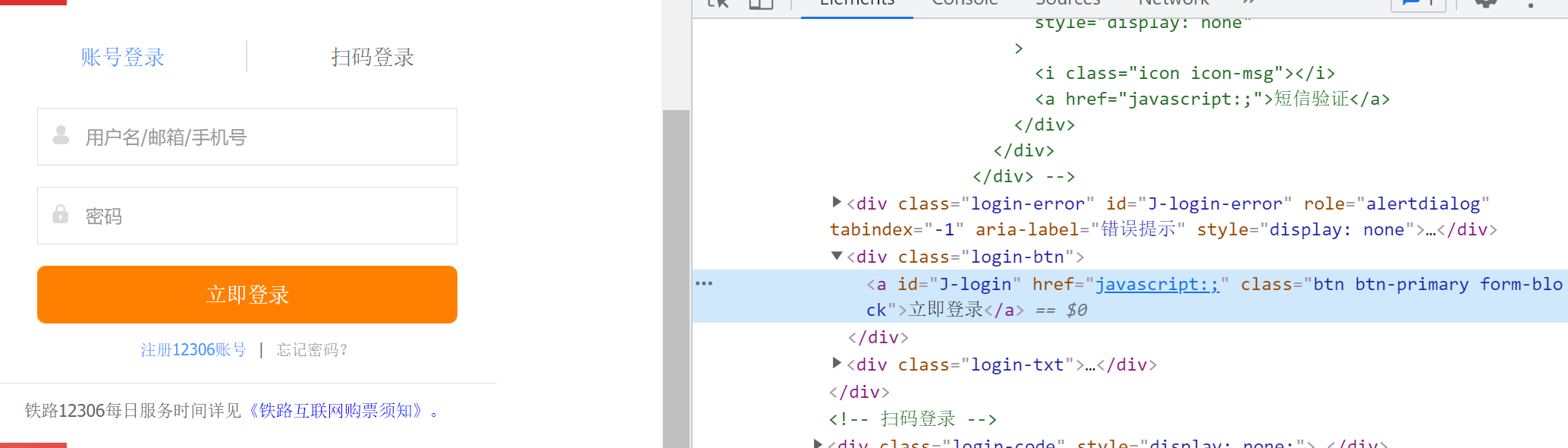
# 6. 模拟点击效果,立即登录
driver.find_element_by_id("J-login").click()
time.sleep(3)
7.弹出滑动验证码,破解,完成登录
F12,找到滑动块id,点击拖拽到最后,完成登录。
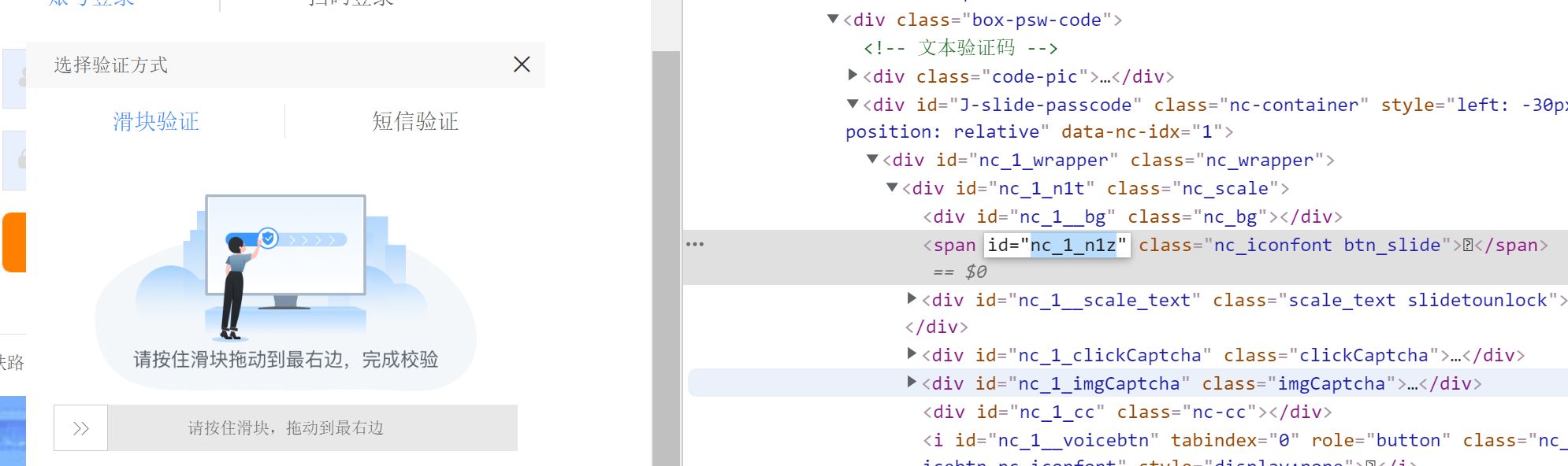
拖拽距离:
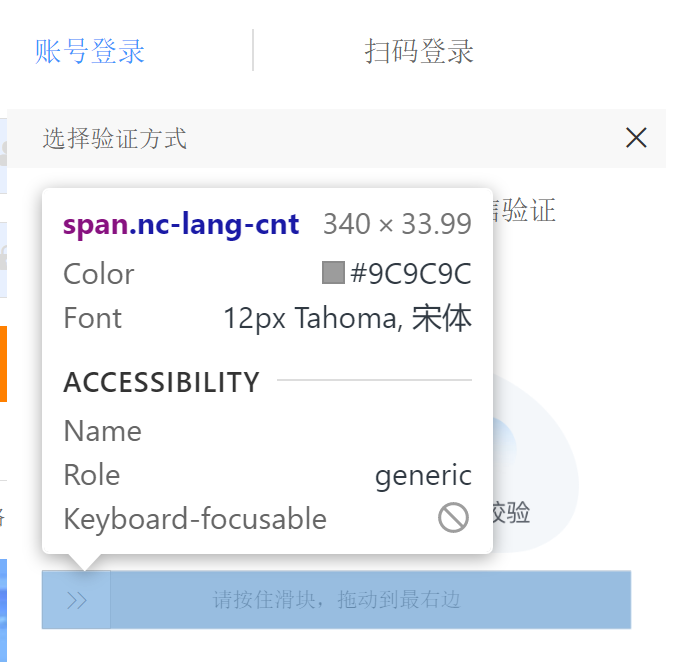
# 7. 弹出滑动验证码,破解,完成登录
span = driver.find_element_by_id("nc_1_n1z")
action = ActionChains(driver)
action.click_and_hold(span)
action.move_by_offset(350, 0).perform() # x轴移动350, y轴移动为0
time.sleep(5)
进行订票
实际操作,记录操作步骤:
- 关闭疫情弹窗
- 点击首页
- 输入购票信息(出发地,到达地,日期)
- 点击查询并切换到新的标签页
确认弹窗(最新版本没有了)- 选择自己想要的班次,默认使用第二个
- 选择乘车人
- 选择席别下拉框,选择想要的席位
- 提交订单
- 确认订单并关闭弹窗(至此订单成功,请在半小时内完成出票)
1.关闭疫情弹窗
F12,找到弹窗确定按钮id,点击。
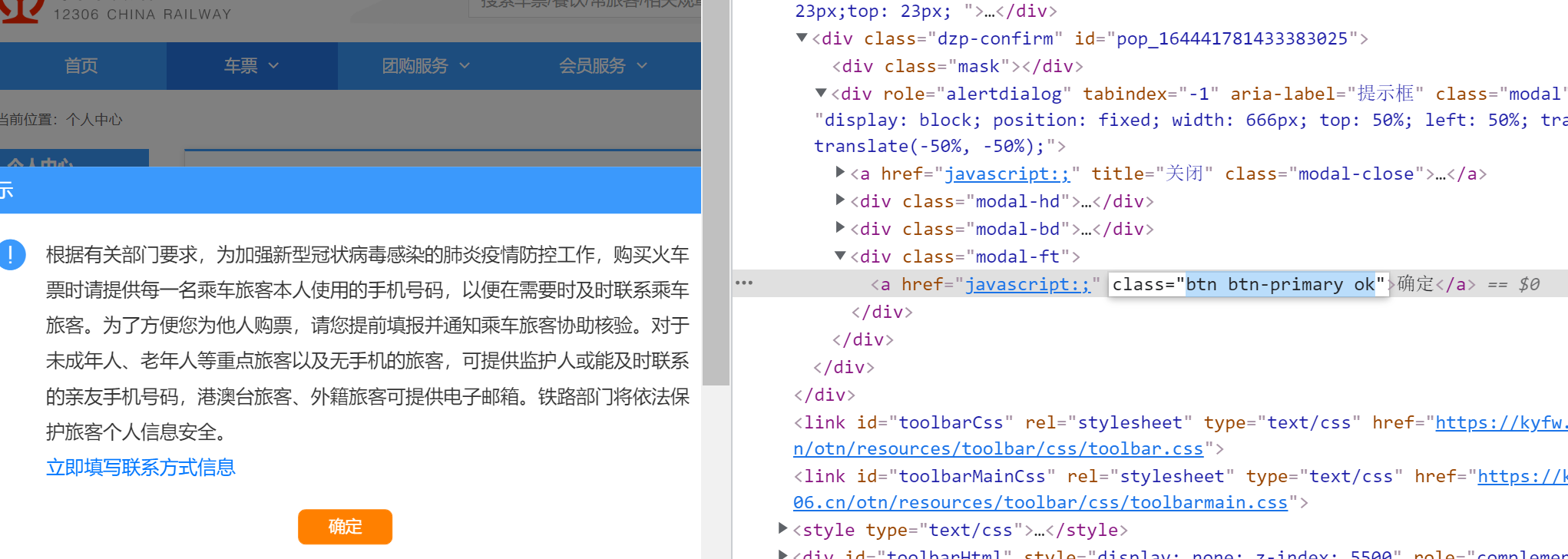
# 1). 关闭疫情弹窗
driver.find_element_by_class_name("ok").click()
2.点击首页
# 2). 点击首页
driver.find_element_by_id("J-index").click()
3.输入购票信息(出发地,到达地,日期)
输入出发地,到达地,出发日期。其中出发日期是只读,需要先去除其只读属性再发送值。
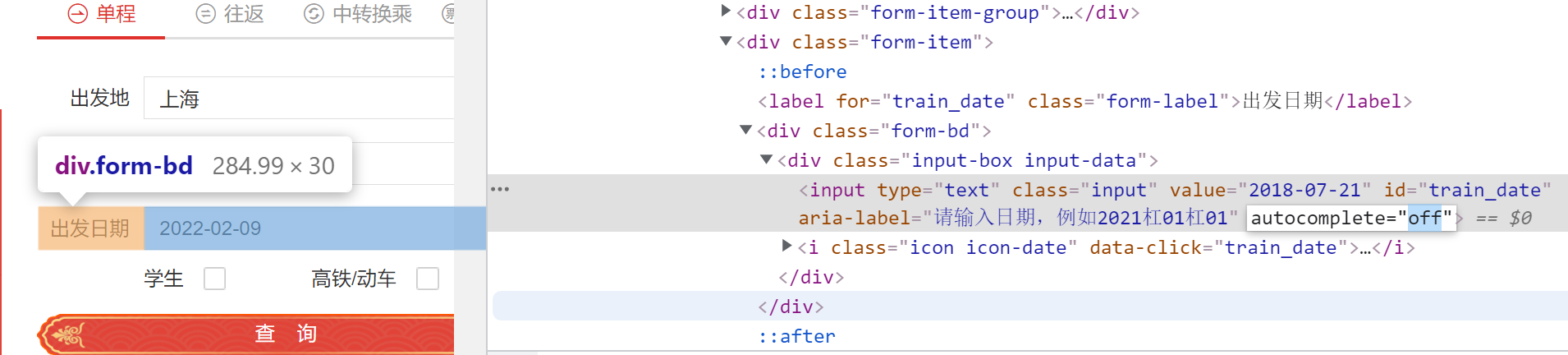
# 3). 输入购票信息(出发地,到达地,日期)
# 输入出发地
from_input = driver.find_element_by_id("fromStationText")
from_input.click()
from_input.send_keys(from_station)
from_input.send_keys(Keys.ENTER) # 回车失去焦点
time.sleep(1)
# 输入到达地
to_input = driver.find_element_by_id("toStationText")
to_input.click()
to_input.send_keys(to_station)
to_input.send_keys(Keys.ENTER)
time.sleep(1)
# 输入日期
driver.execute_script('document.getElementById("train_date").removeAttribute("autocomplete")') # 取消标签只读模式
date_input = driver.find_element_by_id("train_date")
date_input.clear()
date_input.click()
date_input.send_keys(date)
# 回车无法失去焦点,想办法:点击”车票“让其失去焦点
driver.find_elements_by_class_name("active")[1].click()
time.sleep(1)
4.点击查询(切换到新的标签页)
点击查询按钮,会切换到一个新标签页。
# 4). 点击查询(切换到新的标签页)
driver.find_element_by_id("search_one").click()
time.sleep(1)
# 打开一个新页面,窗口需要切换
driver.switch_to.window(driver.window_handles[-1])
time.sleep(1)
5.确认弹窗
6.选择自己想要的班次,默认使用第二个
# 6). 选择自己想要的班次,默认使用第二个
driver.find_elements_by_class_name("btn72")[1].click()
7.选择乘车人
# 7). 选择乘车人
# driver.find_element_by_id("normalPassenger_0").click()
driver.find_element_by_xpath("//div//ul[@id='normal_passenger_id']//li//label[contains(text(), %s)]" %name).click()
8.选择席别下拉框,选择想要的席位
# 8). 选择席别下拉框,选择想要的席位
seat_type = driver.find_element_by_id("seatType_1")
seat_type.click()
Select(seat_type).select_by_visible_text(seat_name)
9.提交订单
# 9). 提交订单
driver.find_element_by_id("submitOrder_id").click()
10.确认订单并关闭弹窗
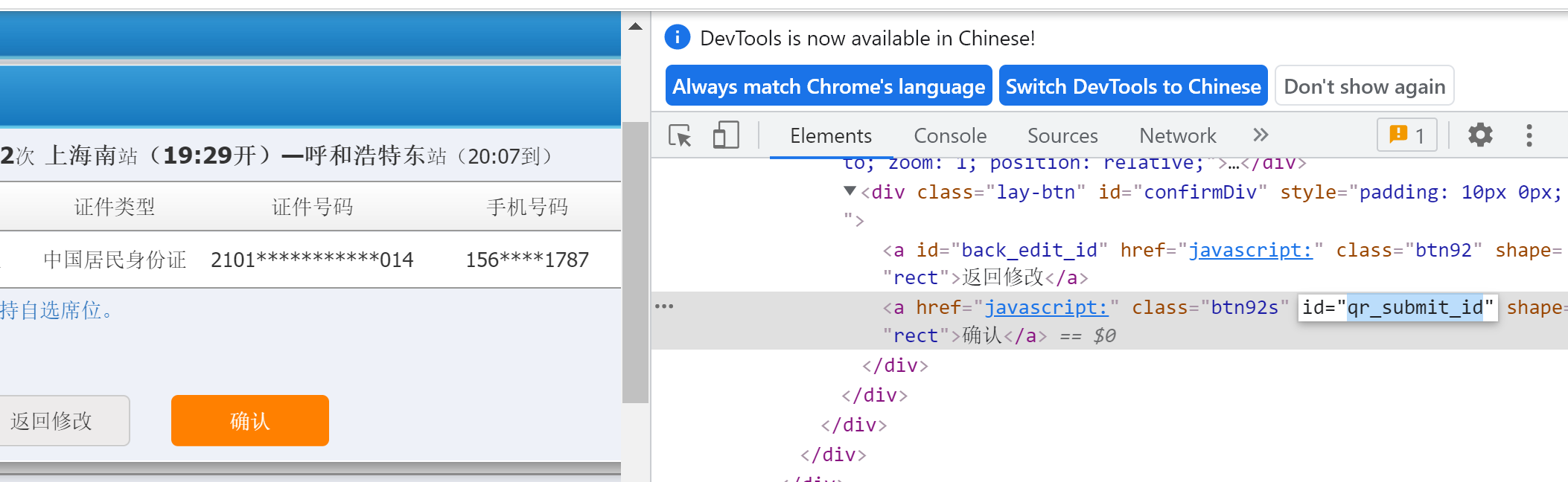
# 10). 确认订单并关闭弹窗(至此订单成功,请在半小时内完成出票)
driver.find_element_by_id("qr_submit_id").click()
References
网上使用第三方接口识别验证码案例:
# 利用requests和selenium实现调用接口识别验证码并登陆12306
import base64
import re
import time
import requests
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class Login(object):
def __init__(self, username, password):
# 图片验证码坐标
self.coordinate = [[-105, -20], [-35, -20], [40, -20], [110, -20], [-105, 50], [-35, 50], [40, 50], [110, 50]]
self.username = username
self.password = password
def login(self):
# 初始化浏览器对象
driver = webdriver.Chrome()
# 12306登陆页面
login_url = "https://kyfw.12306.cn/otn/resources/login.html"
# 设置浏览器长宽
driver.set_window_size(1200, 900)
# 打开登陆页面
driver.get(login_url)
# 找到账号登陆按钮
account = driver.find_element_by_class_name("login-hd-account")
# 点击按钮
account.click()
# 找到用户名输入框
userName = driver.find_element_by_id("J-userName")
# 输入用户名
userName.send_keys(self.username)
# 找到密码输入框
passWord = driver.find_element_by_id("J-password")
# 输入密码
passWord.send_keys(self.password)
self.driver = driver
def getVerifyImage(self):
try:
# 找到图片验证码标签
img_element = WebDriverWait(self.driver, 100).until(
EC.presence_of_element_located((By.ID, "J-loginImg"))
)
except Exception as e:
print(u"验证码图片未加载!")
# 获取图片验证码的src属性,就是图片base64加密后的数据
base64_str = img_element.get_attribute("src").split(",")[-1]
# base64解码得到图片的数据
imgdata = base64.b64decode(base64_str)
# 存入img.jpg
with open('img.jpg', 'wb') as file:
file.write(imgdata)
self.img_element = img_element
def getVerifyResult(self):
# 12306验证码识别网址
url = "http://littlebigluo.qicp.net:47720/"
# 发送post请求把图片数据带上
response = requests.request("POST", url, data={"type": "1"}, files={'pic_xxfile': open('img.jpg', 'rb')})
result = []
print(response.text)
# 返回识别结果
for i in re.findall("<B>(.*)</B>", response.text)[0].split(" "):
result.append(int(i) - 1)
self.result = result
print(result)
def moveAndClick(self):
try:
# 创建鼠标对象
Action = ActionChains(self.driver)
for i in self.result:
# 根据获取的结果取坐标选择图片并点击
Action.move_to_element(self.img_element).move_by_offset(self.coordinate[i][0],
self.coordinate[i][1]).click()
Action.perform()
except Exception as e:
print(e)
def submit(self):
# 点击登陆按钮
self.driver.find_element_by_id("J-login").click()
def __call__(self):
self.login()
time.sleep(3)
self.getVerifyImage()
time.sleep(1)
self.getVerifyResult()
time.sleep(1)
self.moveAndClick()
time.sleep(1)
self.submit()
time.sleep(1000)
if __name__ == '__main__':
# 用户名和密码
username = '******'
password = '******'
Login(username, password)()
# 调用第三方接口识别12306验证码并自动登陆
import time
import json
import base64
import random
import requests
from bs4 import BeautifulSoup
def get_pic_point(image):
point_map = {
'1': '37,46',
'2': '110,46',
'3': '181,46',
'4': '253,46',
'5': '37,116',
'6': '110,116',
'7': '181,116',
'8': '253,116',
}
url= "http://littlebigluo.qicp.net:47720/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',}
files={'pic_xxfile':('image.png',image,'image/png'),}
res=requests.post(url,headers = headers,files=files)
if res.status_code == 200:
soup = BeautifulSoup(res.text,'lxml')
points = soup.select_one('font').text
return ','.join([point_map[point] for point in points.split()])
else:
return None
def get_point_360(imgbase64):
url = "http://60.205.200.159/api"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',}
data = {"base64":imgbase64,}
res = requests.post(url,headers = headers,json = data).json()
check = res['check']
data = {
'=':'',
'check':check,
'img_buf':imgbase64,
'logon':1,
'type':'D',}
url = "http://check.huochepiao.360.cn/img_vcode"
res = requests.post(url,json = data,headers = headers).json()
res = res['res']
res = res.replace('(','')
res = res.replace(')','')
return res
def check_captcha():
captcha_url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64'
headers = {
'Host': 'kyfw.12306.cn',
'Referer': 'https://kyfw.12306.cn/otn/leftTicket/init',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
}
random_data = random.random()
session = requests.Session()
params = {
'login_site':'E',
'module':'login',
'rand':'sjrand',
'_':random_data,
}
response = session.get(captcha_url,params = params,headers = headers)
try:
data = response.json()
img_base64 = data['image']
except:
print ("验证码获取失败!")
return
#points = get_point_360(img_base64)
points = get_pic_point(base64.b64decode(img_base64))
params.pop('module')
params['_'] = int(1000 * time.time())
params['answer'] = points
check_captcha = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
response = session.get(check_captcha,params = params,headers = headers)
data = response.json()
if data['result_code'] != '4':
print ("验证码识别失败!")
return
form_data = {
'username': "*************", #12306账号
'password': "*************", #12306密码
'appid': 'otn'
}
login_url = 'https://kyfw.12306.cn/passport/web/login'
response = session.post(login_url, data = form_data)
res = response.json()
if res["result_code"] == 0:
uamtk_url = 'https://kyfw.12306.cn/passport/web/auth/uamtk'
response = session.post(uamtk_url, data={'appid': 'otn'})
res = response.json()
if res["result_code"] == 0:
check_token_url = 'https://kyfw.12306.cn/otn/uamauthclient'
response = session.post(check_token_url, data={'tk': res['newapptk']})
data = response.json()
print ("{0}!欢迎你:{1}!".format(data['result_message'],data['username']))
if __name__ == '__main__':
check_captcha()
python selenium自动化屏蔽chrome“正受到自动化测试软件的控制”、“开发者模式”、“保存密码提示”:
from selenium import webdriver
option = webdriver.ChromeOptions()
#屏蔽自动化受控提示 && 开发者提示
option.add_experimental_option("excludeSwitches", ['enable-automation', 'load-extension'])
# 屏蔽'保存密码'提示框
prefs = {}
prefs["credentials_enable_service"] = False
prefs["profile.password_manager_enabled"] = False
option.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(options=option)
陈涛视频 ↩︎
https://www.10qianwan.com/articledetail/746462.html 《Python爬虫学习(八)识别12306的验证码信息》 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号