1.1.2 链表Linklist
1.1.2 链表Linklist[1]
链表是实现了数据之间保持逻辑顺序,但存储空间不必按顺序的方法。可以用一个图来表示这种链表的数据结构:
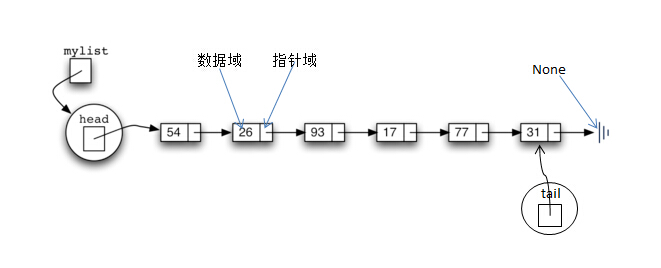
基本要素:
- 结点(也可以叫节点或元素),每一个结点有两个域,左边部份叫
值域,用于存放用户数据;右边叫指针域,一般是存储着到下一个元素的指针 - head结点,head是一个特殊的结节,head结点永远指向第一个结点
- tail结点,tail结点也是一个特殊的结点,tail结点永远指向最后一个节点
- None,链表中最后一个结点指针域的指针指向None值,因也叫
接地点,所以有些资料上用电气上的接地符号代表None
常用方法:
- LinkedList() 创建空链表,不需要参数,返回值是空链表
- is_empty() 测试链表是否为空,不需要参数,返回值是布尔值
- append(data) 在尾部增加一个元素作为列表最后一个。参数是要追加的元素,无返回值
- iter() 遍历链表,无参数,无返回值,此方法一般是一个生成器
- insert(idx,value) 插入一个元素,参数为插入元素的索引和值
- remove(idx) 移除1个元素,参数为要移除的元素或索引,并修改链表
- size() 返回链表的元素数,不需要参数,返回值是个整数
- search(item) 查找链表某元素,参数为要查找的元素或索引,返回是布尔值
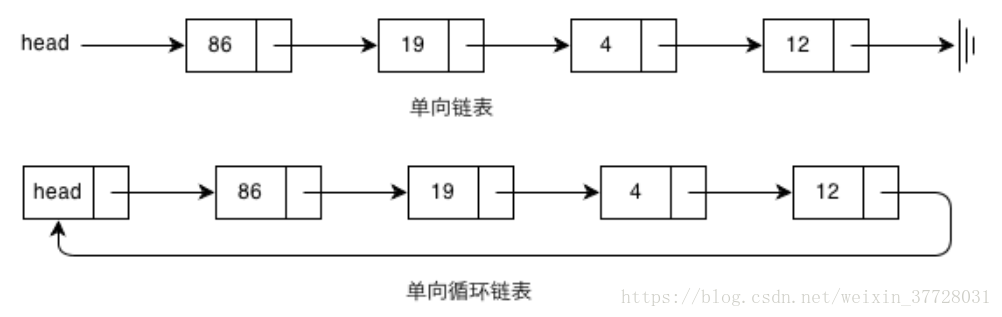
链表种类:单向链表、单向循环链表、双向链表、双向循环链表
节点类
python用类来实现链表的数据结构,节点(Node)是实现链表的基本模块,每个节点至少包括两个重要部分。首先,包括节点自身的数据,称为“数据域”(也叫值域)。其次,每个节点包括下一个节点的“引用”(也叫指针)
实现一个Node类:
class Node:
def __init__(self, data):
self.data = data
self.next = None
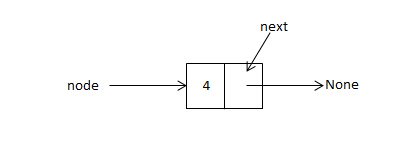
此节点类只有一个构建函数,接收一个数据参数,其中next表示指针域的指针,实例化后得到一个节点对象,如下:
node = Node(4)
此节点对象数据为4,指针指向None。
这样一个节点对象可以用一个图例来更形象的说明,如下:
链表类
LinkedList类的构建函数:
class LinkedList:
def __init__(self):
self.head = None
self.tail = None
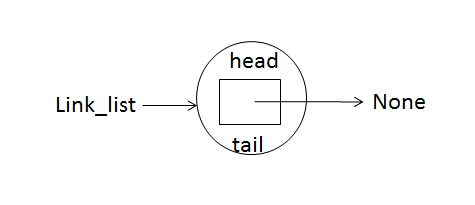
此类实例后会生成一个链表对象,初始化了head和tail节点,且两节点都指向None,实例化代码如下:
link_list = LinkedList()
也可以用图形象的表示这个链表对象,如下:
is_empty方法实现
is_empty方法检查链表是否是一个空链表,这个方法只需要检查head节点是否指向None即可,代码如下:
def is_empty(self):
return self.head is None
如果是空列表返回True,否则返回False
append方法实现
append方法表示增加元素到链表,这和insert方法不同,前者使新增加的元素成为链表中第一个节点,而后者是根据索引值来判断插入到链表的哪个位置。代码如下:
def append(self, data):
node = Node(data)
if self.head is None:
self.head = node
self.tail = node
else:
self.tail.next = node
self.tail = node
既然要新增加节点,首先把Node类实例化得到一个node对象。这里有两种情况需要考虑,一是链表是一个空链表时怎样append一个节点;二是当链表不是空链表时又怎样append一个节点?
当if self.head is None:为True时,把链表的head和tail都指向了node,假如我们执行了
link_list(append(4))
此时的链表结构如下图:
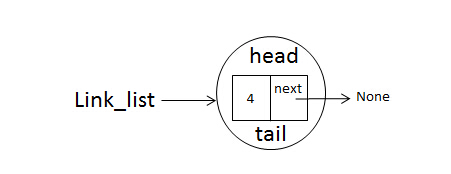
当if self.head is None:为False时,说明链表已经增加了一个节点了,再增加一个节点时head已经指向了第一个节点,所以不为None,比如增加的第二个节点为:
link_list(append(5))
增加第二个节点的操作需要分两步完成,第一步:self.tail.next = node,即把上一个节点的next指针指向当前node;第二步:self.tail = node,把tail移动到node,如下图:
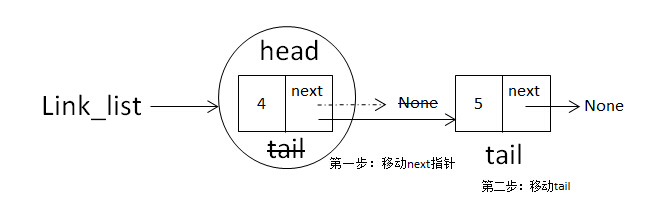
移动完成后就成这样了:
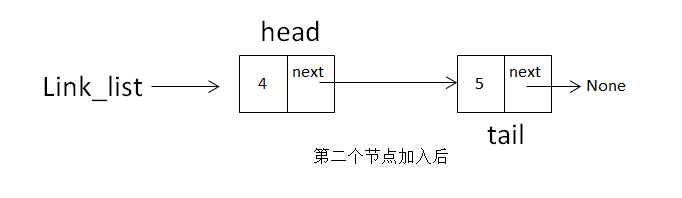
当增加第三个、第四个等节点时,按照上边的操作依次类推。
iter方法实现
iter方法表示遍历链表。在遍历链表时也要首先考虑空链表的情况。遍历链表时从head开始,直到一个节点的next指向None结束,代码如下:
def iter(self):
if not self.head:
return
cur = self.head
yield cur.data
while cur.next:
cur = cur.next
yield cur.data
当是遍历一个空链表时,if not self.head:为True,直接返回None;如果不是空链表就让一个局部变量cur指向head,并把head的data属性yield出来,再对cur的next指针指向的对象做while循环,直到next指向None,这样就遍历了链表。
insert方法实现
假如采取append方法又增加了两个节点,增加完成后如下图:
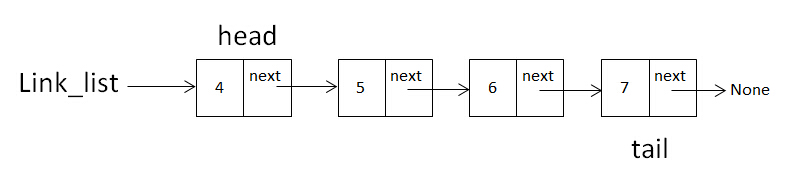
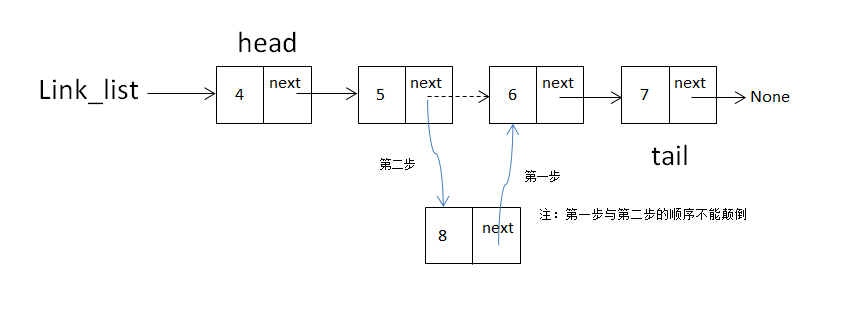
如果想在数据域为6的那节点处插入一个节点,需要做的操作有两步:
- 把新节点的next指针指向数据域为
6的这个节点,即为数据域为5节点的next指向指向的对象 - 把数据域为
5节点的next指针指向新加的节点
注: 这两个步骤不能颠倒,如果颠倒,数据域为6的节点会被丢失,数据域为7的节点不再是链表的节点。
示意图如下:
还要额外考虑两种情况:
- 空链表时
- 插入位置超出链表节点的长度时
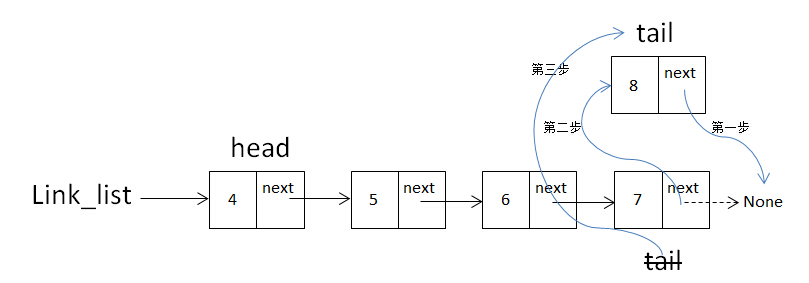
- 插入位置是链表的最后一个节点时,需要移动tail
当是在链表最后一个节点插入时,示意图如下:
要在指定的索引位置插入一个节点,前提是需要找到这个位置,在链表中只有采用遍历的方式,具有O(n)的速度,最糟糕时会遍历链表的所有节点,而当找到插入点时,我们并不需要当前节点的信息,而是需要前一个节点的信息,所以代码中巧妙的使用了while cur_idx < idx-1:的方式,这样能使用cur这个变量能指向插入点上一个节点对象。
实现insert方法的代码如下:
def insert(self, idx, value):
cur = self.head
cur_idx = 0
if cur is None:
raise Exception('The list is an empty list')
while cur_idx < idx-1:
cur = cur.next
if cur is None:
raise Exception('list length less than index')
cur_idx += 1
node = Node(value)
node.next = cur.next
cur.next = node
if node.next is None:
self.tail = node
remove方法实现
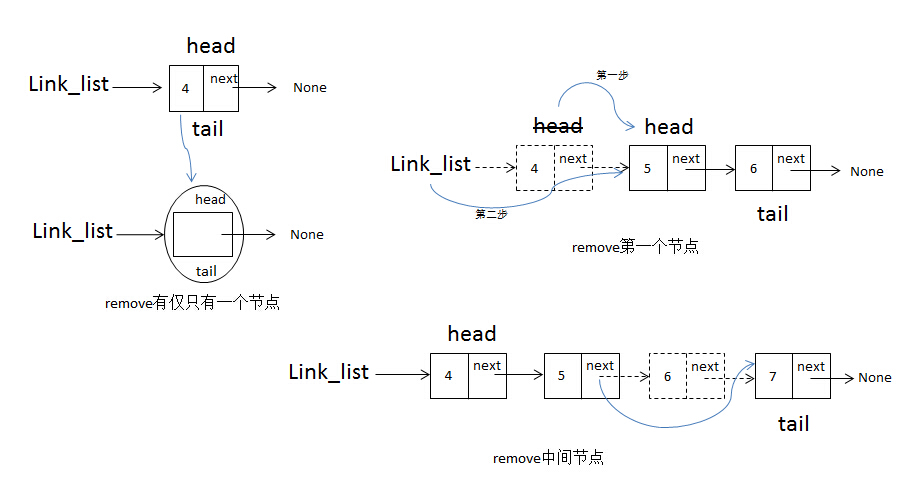
remove方法接收一个idx参数,表示要删除节点的索引,此方法要考虑以下几种情况:
- 空链表,直接抛出异常
- 删除第一个节点时,移动head到删除节点的next指针指向的对象
- 链表只有一个节点时,把head与tail都指向None即可
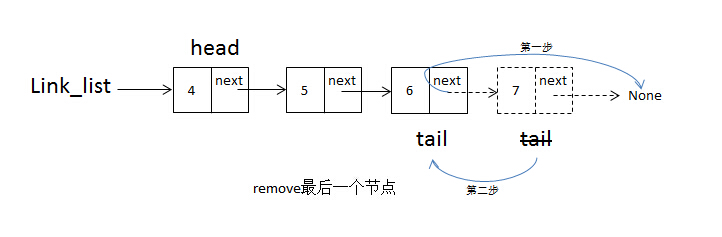
- 删除最后一个节点时,需要移动tail到上一个节点
- 遍历链表时要判断给定的索引是否大于链表的长度,如果大于则抛出异常信息
请看下边图例:
以下为remove函数的代码:
def remove(self, idx):
cur = self.head
cur_idx = 0
if self.head is None: # 空链表时
raise Exception('The list is an empty list')
while cur_idx < idx-1:
cur = cur.next
if cur is None:
raise Exception('list length less than index')
cur_idx += 1
if idx == 0: # 当删除第一个节点时
self.head = cur.next
cur = cur.next
return
if self.head is self.tail: # 当只有一个节点的链表时
self.head = None
self.tail = None
return
cur.next = cur.next.next
if cur.next is None: # 当删除的节点是链表最后一个节点时
self.tail = cur
size函数实现
size函数不接收参数,返回链表中节点的个数,要获得链表的节点个数,必定会遍历链表,直到最后一个节点的next指针指向None时链表遍历完成,遍历时可以用一个累加器来计算节点的个数,如下代码:
def size(self):
current = self.head
count = 0
if current is None:
return 'The list is an empty list'
while current is not None:
count += 1
current = current.next
return count
search函数实现
search函数接收一个item参数,表示查找节点中数据域的值。search函数遍历链表,每到一个节点把当前节点的data值与item作比较,最糟糕的情况下会全遍历链表。如果查找到有些数据则返回True,否则返回False,代码如下:
def search(self, item):
current = self.head
found = False
while current is not None and not found:
if current.data == item:
found = True
else:
current = current.next
return found
双链表
单链表结点中只有一个指向其后继的指针,这使得单链表只能从头结点依次顺序的向后遍历,访问后继结点时间复杂度为O(1),访问前驱结点的时间复杂度为O(n).

双链表仅仅是在单链表的结点中增加一个指向其前驱的prior指针,因此,在双链表中执行按值查找和按位查找的操作和单链表相同。但双链表在插入和删除操作的实现上,和单链表有着较大的不同。这是因为“链”变化时也需要对prior指针做出修改,其关键在于保证在修改的过程中不断链。此外,双链表可以很方便地找到其前驱结点,因此,插入,删除结点算法的时间复杂度为O(1).
双链表的结点定义:
class linknode():#每个结点有两个数据成员,结点元素和指向下一个结点的指针
def __init__(self,item):
self.item=item
self.next=None
self.prior=None
插入节点:
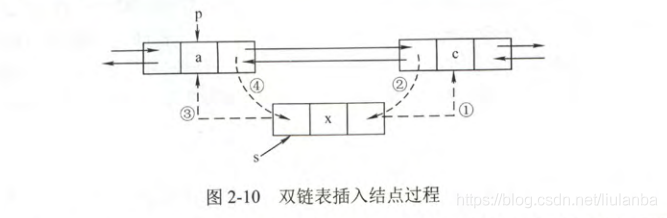
在双链表中p指向的结点之后插入s指向的节点,执行代码为:
s->next=p->next
s->prior=p
p->next->prior=s
p-next=s
删除节点
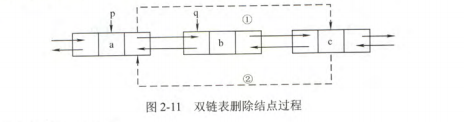
删除双链表中q指向的结点,执行代码:
p->next=q->next
q->next->prior=p
循环链表
循环单链表
循环单链表和单链表的区别在于,表中最后一个结点的指针不是NULL,而改为指向头结点,从而整个链表形成一个环。

表尾指针的next指向头结点,因此表中没有指针域为NULL的结点,因此循环单链表的判空条件为:
头结点->next==L?True:False
循环双链表
和循环单链表的不同在于:头结点的prior指针还要指向尾结点,其余的结点也都有两个指针域,prior指向它的前驱结点。
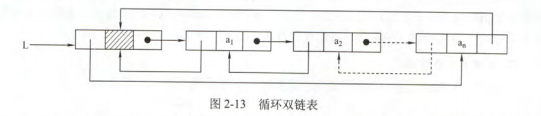
当循环双链表为空表时,其头结点的prior和next都等于L
代码实现
│ 1_singly_linked_list.py 单链表实现
│ 2_doubly_linked_list.py 双链表实现
│ 3_circular_linked_list.py 循环单链表实现
│ 4_deque_doubly.py 双向队列链表实现
│ 5_sorted_linked_lists.py 排序队列实现
│ skip_list.py 跳表实现,放到树中
│
│ 链表Linklist.md 链表简要说明笔记
│
├─exercises
│ from_sequence.py 列表生成链表
│ has_loop.py 链表中是否有循环
│ is_palindrome.py 回文
│ print_reverse.py 反序打印
│ swap_nodes.py 交换两个节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号