


Redis限流和GeoHash
断尾求生一一简单限流
除了控制流量,限流还有一个应用目的是控制用户行为,避免垃圾请求。
如何使用 Redis 来实现简单限流策略
用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 申的一个 key 保存下来。同一个用户的同一种行为用一个 zset 记录。为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户, 滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。通过统计滑动窗口内的行为数量与阈值 max _count 进行比较就可以得出当前的行为是否被允许。
整体设计思路:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。 zset 集合中只有 score 值非常重要, value 值只需要保证它是唯一的就可以了。 因为这几个连续的 Redis 操作都是针对同一个 key 的,使用pipeline 可以显著提升 Redis 存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录, 如果这个量很大,会消耗大量的存储空间。
一毛不拔一一漏斗限流
漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着系统允许该行为的最大频率。
Redis-Cell
Redis 4.0 提供了一个限流 Redis 模块 ,它叫 Redis-Cell 。该模块也使用了漏斗算法,并提供了原子的限流指令。
cl . throttle key: reply 15(capacity容量) 30 60 1(可选参数,默认值是1) 30/60是漏水速率
cl . throttle key: reply 15 30 60
-
(integer) 0 # 表示允许,1 表示拒绝
-
(integer) 15#漏斗容量 capacity
-
(integer) 14#漏斗剩余空间 left quota
-
(integer) -1 #如果被拒绝了,需要多长时间后再试(漏斗有空间了,单位秒)
5 ) (integer) 2 #多长时间后,漏斗完全空出来( left_quota==capacity ,单位秒)
cl.throttle 指令在执行限流指令时,如果被拒绝了,会自动算出重试时间,可以用异步定时任务防止阻塞线程。
近水楼台——GeoHash
Redis在3.2 版本以后增加了地理位置 Geo 模块。
用数据库来算附近的人
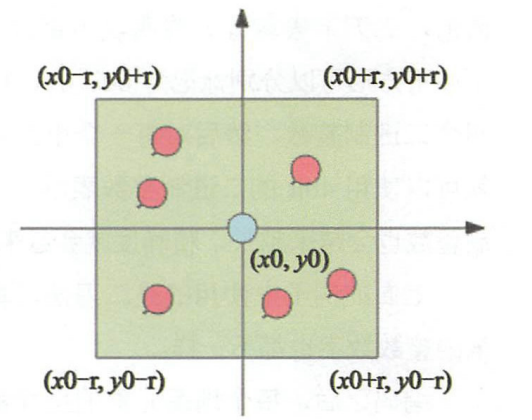
如果现在元素的经纬度坐标使用关系数据库 (元素 id,经度 x,纬度 y)存储,你 该如何计算?
一般的方法都是通过矩形区域来限定元素的数量,然后对区域内的元素进行全量距离计算再排序。指定 一个半径 r ,使用一条 SQL 就可以圈出来。 如果用户对筛出来的结果不满意,那就扩大半径继续筛选。
为了满足高性能的矩形区域算法,数据表需要把经纬度坐标加上双向复合索号 (x, y),这样可以最大优化查询性能。
select id from positions where x0-r < x < x0+r and y0 - r < y < y0+r
GeoHash算法
GeoHash 算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。计算“附近的人”时,将目标映射到这条线上,在这个一维的线上获取附近的点就行了。
算法实现:将整个地球看成一个二维平面,然后划分成了一 系列正方形的方格,就好比围棋棋盘。所有的地图元素坐标都将被放置于唯一的方格中。方格越小,坐标越精确。然后对这些方格进行整数编码,越是靠近的方格编码越是接近。用切蛋糕法编码。
在使用 Redis 进行 Geo 查询时,我们要时刻想到它的内部结构实际上只是一个 zset (skiplist )。通过 zset 的score 排序就可以得到坐标附近的其他元素,通过将 score 还原成坐标值就可以得到元素的原始坐标。
Geo指令的基本用法
geoadd key x y value 增加
geodist key value1 value2 km/m/ml/ft 距离
geopos key value1 value2 获取元素位置
geohash key value 获取元素的 hash值
附近的公司
georadiusbymember 指令可以用来查询指定元素附近的其他元素
georadiusbymember company ireader 20 km count 3 asc #范围 20 公里以内最多3个元素按距离正排,它不会排除自身
三个可选参数 withcoord withdist(显示距离) withhash(hash值) 用来携带附加参数
根据坐标值来查询附近的元素的指令 georadius
georadius key x y rank km withdist count number asc/desc
注意事项
建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。如果数据量过亿个,甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分、按市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个zset 集合的大小。

