Redis 核心原理
一、Redis 的单线程和高性能
1、Redis是单线程的,为什么还这么快呢?
(1)它的数据都是在内存中的,所有的运算都是内存级别的运算;
(2)单线程避免了多线程的上下文切换消耗的性能;
当然,redis单线程也有缺点:在执行一些耗时的 redis 指令时候要谨慎,可能会造成 redis 的卡顿;
比如使用 keys 命令,获取所有满足特定正则字符串规则的key,当数据量非常大时就会造成 redis 卡顿;
keys 命令的使用:
keys * //查询所有key
keys con* //查询所有以 con 开始的key
keys con*st //查询所有以 con开始,并且以 st 结尾的key
那应该使用什么方法去获取 redis 中符合条件的 key 呢?
可以使用 scan 命令
Scan命令的介绍
SCAN cursor [MATCH pattern] [COUNT count]
scan 提供了三个参数,第一个是 cursor 整数值,第二个是 key 的正则模式,第三个是一次遍历的key的数量,并不是符合条件的结果数量。第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。
实际上 scan 相当于是分页查询,只不过下一次查询开始的 cursor 是由上一次查询结果返回的。
例如: 查询 redis 中的所有 key;
> scan 0 match * count 3
1) "2"
2) 1) "user:1"
2) "user:2:like"
3) "article:readcount:999"
> scan 2 match * count 3
1) "1"
2) 1) "user:1:name"
2) "user:cart:100"
3) "user:2:name"
> scan 1 match * count 3
1) "15"
2) 1) "user"
2) "cart:1001"
3) "user:1:age"
4) "user:1:balance"
5) "user:2:age"
> scan 15 match * count 3
1) "0"
2) 1) "china"
说明: 每个 scan 的查询结果都有2行,第1行是下次 scan 查询的 cursor 的值,直到查询结果的第1行返回的 cursor 为 0,才表示查询完了;
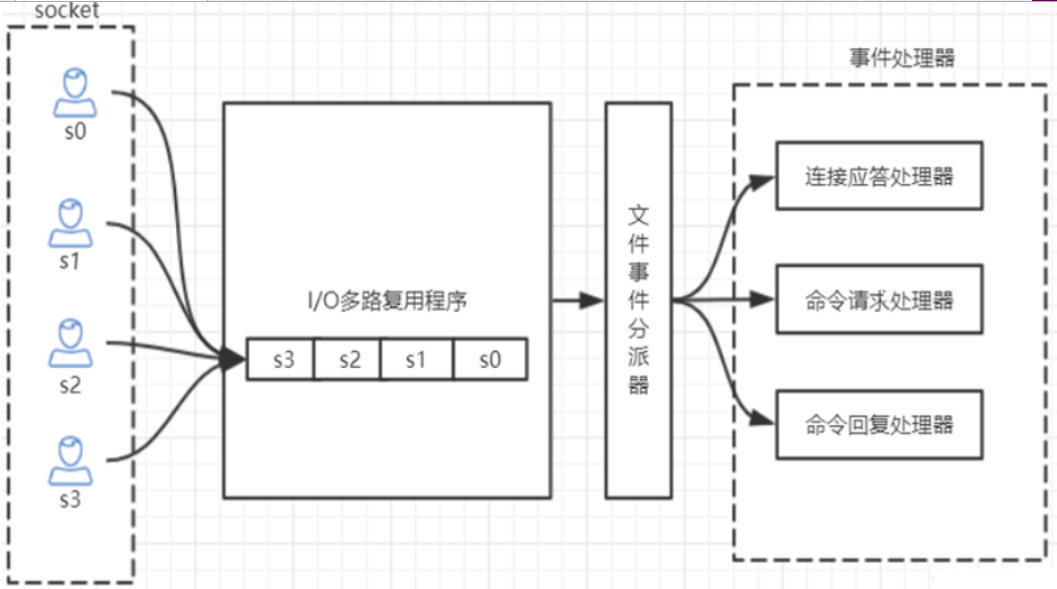
2、Redis 是单线程,它如何处理那么多的并发客户端连接?
Redis 利用 epoll 来实现了 IO 多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器;
设置redis支持最大连接数:可以在 redis 的 配置文件 redis.conf 文件中设置最大连接数,默认是 1000;# maxclients 10000
查看redis的最大连接数:使用命令 config get maxclients;
二、Redis 持久化
1、RDB快照(snapshot)
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。
保存策略的配置格式:
save N M 表示 “ N 秒内数据集至少有 M 个改动 ” 这一条件被满足时, 自动保存一次数据集。
注意:
改动指的是值的修改,查询操作是不计数的;
配置多个 save 的时候,只要有一个符合条件就会触发一次保存;
每次保存数据是将内存中的所有数据保存到二进制 rdb 文件中;
save 900 1 # 900秒内至少有1个改动时,自动保存一次数据
save 300 10 # 300秒内至少有10个改动时,自动保存一次数据
save 60 10000 # 60秒内至少有10000个改动时,自动保存一次数据
关闭 RDB 只需要将所有的 save 保存策略注释掉就可以了;
优点:生成的 rdb 快照文件是经过压缩的,比较小,在 redis 重新启动恢复数据的时候较快;
缺点:每次保存是保存内存中的所有数据到 rdb 二进制文件中,当数据量过大的时候,保存需要较长的时间,所以时间和改动数不能同时配置的太小;
若配置的策略为 save 60 10000 ,在 55 秒时候经过了 9999 个改动,然后redis 给挂掉了,那么数据就丢失掉了;数据的安全性方面很容易丢失数据;
手动生成快照文件
进入到 redis 客户端,执行命令 save 或 bgsave 命令可以生成 dump.rdb 文件,每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。
save是同步命令,不会fork一个子进程出来,在保存的时候,redis不能处理其他操作的;
bgsave是异步命令,会从redis主进程fork(fork()是linux函数)出一个子进程专门用来生成rdb快照文件,不会对其他redis操作阻塞;
save与bgsave对比
| 命令 | save | bgsave |
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子进程执行调用fork函 数时会有短暂阻塞) |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
配置文件中自动生成rdb文件的后台使用的是bgsave方式 。
2、AOF(append-only file)
RDB功能的在数据安全性方面容易丢失数据:如果 redis 因为某些原因而造成故障停机,那么服务器将丢失最近写入、且仍未保存到快照中的数据。
从1.1版本,redis 增加了 一种完全耐久的持久化方式:AOF持久化,它将修改的每一条指定记录到 appendonly.aof 文件中。
2.1 AOF配置的开启:将配置文件中的 appendonly 后的值修改为 yes:appendonly yes
2.2 Redis 的数据同步到 appendonly.aof 文件的方式:
- appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
- appendfsync everysec:每秒 fsync 一次,足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
- appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
这3中方式只能配置1个,推荐(并且也是默认)的方式为每秒 fsync 一次(appendfsync everysec), 这种 fsync 策略可以兼顾速度和安全性。
2.3 AOF重写
AOF文件里面记录了每次修改的指令,它里可能有太多的没用指令,造成文件过大;在 Redis 重启起来的时候,会读取AOF文件的一条一条的指定,接着一条条的去执行,这样就会很慢, 所以AOF会定期根据内存的最新数据生成aof文件;
例如: 连续执行了 incr count 命令6次,它全部存到 aof 文件中去了,但是如果只存储: set count 6 这一条指令,那 aof 文件的大小就变小。
执行了 incr count 指定之后,执行 bgrewriteaof 指令去手动触发AOF重写; aof 文件的内容:
*3
$3
set
$5
count
$1
6
说明: *3:表示了 set key value 指令有3个占位;
$3:表示了下一行 set 的长度为3;
$5:表示了下一行 count 的长度为 5;
$1:表示了下一行 6 的长度为 1;
AOF重写的频率配置
# auto-aof-rewrite-min-size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大;
# auto-aof-rewrite-percentage 100 //aof文件自上一次重写之后,直到文件大小增长了100% 之后,则再次触发重写;
AOF的手动重写
进入redis客户端执行命令 bgrewriteaof 来重写AOF;
注意:AOF重写redis会fork出一个子进程去做,不会对redis正常命令处理有太多影响。
RDB 和 AOF 的比较
| 命令 | RDB | AOF |
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
注意:redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为 aof 一般来说数据更全一点。
3、Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。
混合持久化 配置的开启: aof-use-rdb-preamble yes
若开启了混合持久化,AOF在重写时,不再是单纯的将内存数据转为 RESP 命令写入AOF文件,而是将重写这一刻之前的内存做 RDB 快照处理; 之后的再次命令的写入时候又是以 RESP 命令的方式写入到新的 AOF 文件中。 实际上,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,原子的覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的AOF 全量文件重放,因此重启效率大幅得到提升。
混合持久化的AOF文件内容:
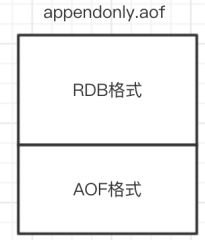 新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,原子的覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,原子的覆盖原有的AOF文件,完成新旧两个AOF文件的替换。

