MySQL索引数据结构红黑树,Hash,B+树详解
数据结构和算法(Data Structure Visualizations):https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
一、MySQL索引底层的实现
索引是帮助MySQL高效获取数据的排好序的数据结构;

上图中有一张表,表名为 t ,表中有7条数据;使用 select * from t where t.clo2 = 89 查询;
1、若表中没有创建索引,则会全表扫描,一条一条的遍历查询,需要遍历 6 次,查询一行数据至少和磁盘做一次I/O操作(I/O是很耗性能的),至少要做 6 次 I/O 操作;
2、表中建立了索引:
(1)若索引底层是二叉树(左边的子元素小于父元素,右边的子元素大于父元素)存储的,则如下图所示:
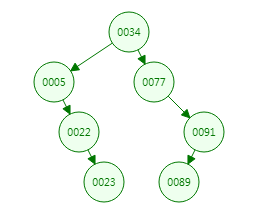
这样查询 4 次就找到数据了;
当然,在极端情况下,若按照大小顺序插入二叉树,则会形成单边增长的二叉树,这样使用索引的时候和全表扫描是一样的了;
(2)若索引底层是红黑树存储的,则如下图所示:
红黑树:当单边的节点大于3时候,就会自动调整,这样可以解决二叉树的弊端;红黑树也叫平衡二叉树;
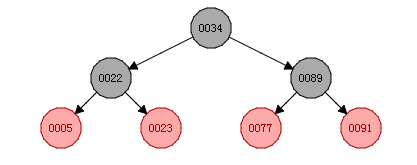
当然,红黑树也有弊端的,当数据量特别大的时候,红黑树的高度特别大;假如有500W条数据,则红黑树高度为 23,若我们要查找的刚好是红黑树的叶子节点,则需要查找 23 次才可以,即要发生 23 次的磁盘 I/O 操作,性能就太差了;
(3)若索引底层是 B-Tree 存储的
(叶子节点具有相同的深度,叶节点的指针为空;所有索引元素不重复;一个节点可以存储多个元素,节点中的数据索引从左到右递增排列)
若 Max. Degree = 4,则如下图所示:

这样只查询 2 次就找到了;
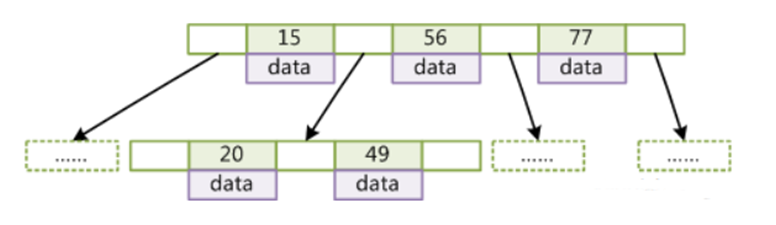
当然 B-Tree 也是有弊端的;以下是 B-Tree 的存储,数字为key,data为对应的数据;
若一个节点我们申请的空间为16KB,若data中的数据过大,则一个节点能放的数据量越小,这样就会造成树的高度比较大了(比红黑树高度小点);
(4)MySQL的索引底层使用的 B+Tree 存储的(数据存储在叶子节点)
B+Tree:
非叶子节点不存储data,只存储索引(冗余),可以放更多索引;
叶子节点包含所有索引字段,即所有的data元素存储在叶子节点上;
叶子节点使用指针连接,提高区间访问的性能;
从左到右一次递增;
B+Tree 相对于 B-Tree的优化点:
优化点1: B-Tree的所有节点都存储了 data 元素, B+Tree的非叶子节点不存储 data元素,则 B+Tree 的一个非叶子节点可以存储更多的索引;
优化点2: B+Tree在叶子节点之间增加了指针连接;对 select * from t where col2 > 20 的范围查找有很好的支持;
MySQL 对 B+Tree 做了优化,叶子节点使用的是双向指针;
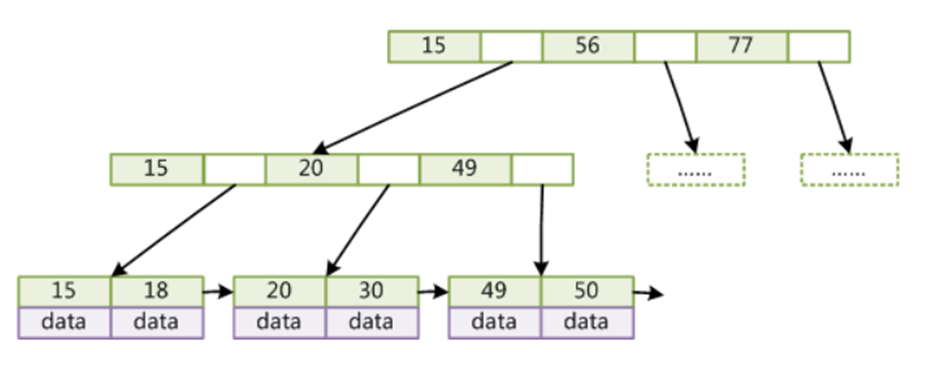

以上图中查找 49 的数据:
I. 先将根节点的数据(15, 56, 77) 做一次磁盘 I/O 操作取出加载到内存中,然后再在内存中做比对,找到对应的指针,查找到其对应的节点;
II. 将指针指向节点的数据(15, 20, 49) 做一次磁盘 I/O 操作取出加载到内存中,然后再在内存中做比对,找到对应的指针,接着去叶子节点获取数据;
<1> 查看MySQL文件页大小(一个节点的大小):
SHOW GLOBAL STATUS like 'Innodb_page_size';
<2> MySQL页文件默认为16KB,树的高度为3,能够存储多少数据?
我们先看非叶子节点,假设主键ID为 bigint 类型,那么长度为8B,指针大小在Innodb源码中6B,一共14B,那么一页(即一个节点)可以存储 16KB/14B=1170 个索引元素和 1170个指针;根节点有1170个索引和1170个指针,树高度为2的节点就有1170个,那么叶子节点的数量为 1170x1170;每个叶子节点可以存储16KB,若每条数据比较大为1KB,那么每个叶子节点可以存储16条数据;那么,高度为3的 B+Tree 的叶子节点可以存储的数据量为 1170x1170x16=2000W;
在实际的MySQL中表的索引存储可以选择 Hash 或 BTree
(5)若索引使用的 Hash 存储的,存储的时候先做一次hash运算,根据 hash 的值就可以快速的定位数据的磁盘指针,这样就不管表里面有多少数据,我们的查询效率都非常的快;
在实际中为什么使用 B-Tree 或 B+Tree 来存储索引的方式更多,而不太使用 hash 呢?
原因1:若使用 select * from t where clo2 > 6,这种查找范围的SQL,那Hash就不能搞定了,就不会走索引了;而且对排序hash也没有办法;
原因2:hash会产生 hash 碰撞,MySQL的底层对hash做了处理,很少会发生hash碰撞的;
二、MySQL的存储引擎的实现
同一个数据库中,不同的表可以设置不同的存储引擎;
MySQL的数据存储在 data 目录下, data 目录下的 文件夹是以 数据库为单位的,数据库文件夹下面存放的表数据; data / {数据库名} /表文件

1、MyISAM存储引擎索引实现
MyISAM存储引擎的索引文件和数据文件是分离的(非聚集);
MyISAM 存储引擎的一个表有3个文件: *.frm 文件存储的表的结构; *.MYD 文件存储表的数据; *.MYI 文件存储表中的索引数据;
MYISAM 存储引擎的索引的叶子节点的data中存储的是索引所在行的磁盘指针; ---- 非聚集索引
MYISAM 存储引擎的主键索引 和 非主键索引的存储是差不多的,InnoDB 存储引擎的 主键索引 和 非主键索引存储是不一样的;

2、InnoDB 存储引擎-索引实现
InnoDB存储引擎索引文件和数据文件是合一的(聚集);
InnoDB 存储引擎的1个表有2个文件: *.frm 文件存储表的结构; *.ibd 文件存储的是索引和数据;
InnoDB表的数据文件本身就是按 B+Tree 组织的一个索引结构文件;聚集索引叶子节点包含了完整的数据记录;
(1)InnoDB的主键索引
InnoDB 存储引擎的索引的叶子节点的data中存储的是索引对应的所有数据;----聚集

问题1:为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
a. 因为 MySQL对于 InnoDB 表设计的就是按照 B+Tree 组织存储数据的,若没有主键就没有办法去存储数据了;但是在平常我们建表的时候没有指定主键也是可以建成功的,这是因为 MySQL 会生成一个 rowid 作为数据的唯一标识;
b. 若使用的 UUID 作为主键,在查找的时候需要去比较大小,字符串UUID比较的效率肯定低于数据的比较;在进行比较的时候会把数据拿到内存空间中做比较,UUID为字符串占用的内存空间就会较多;
c. 若是递增的,则插入的数据直接向后排,这个节点满了,直接新增一个节点就好了;若不是递增的,有个节点存储满了(5, 9),但是新插入了一个数据(7)在这个节数据的中间,则需要将这个节点先分裂,再平衡去满足 B+Tree 的结构;
(2)InnoDB 的非主键索引
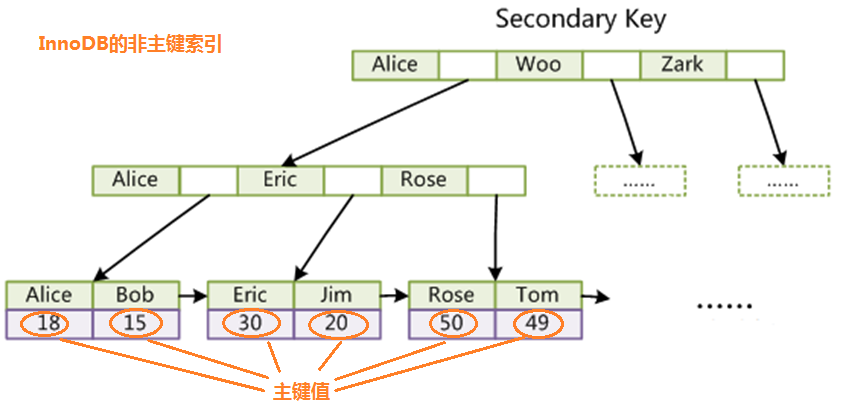
在使用非主键索引查找的时候,先从非主键索引的树中查询到对应的主键值,然后使用主键值去到主键索引的树中去查找;
对于非主键单值索引,若索引字段的值为 null,则它的数据不会放到非叶子节点上,是放在叶子节点的链表的最前面的;(强烈不建议字段设置为null)
问题2:为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
因为在插入数据之前先要维护一下索引,然后再将数据插入进去;若 主键索引 和 非主键索引 的叶子节点都存储具体的数据,则一个 insert 语句插入成功的判断就是 向主键索引中插入成功 且 向非主键索引中也插入成功,这样就造成了事务的问题,事务是很耗性能的;当然,主键索引和非主键索引的叶子节点都存储具体数据,会造成数据的同样的数据存储了几份,就造成了空间的浪费;
联合索引的底层存储结构

以上的联合索引从左到右由字段 a,b,c 组成;
联合索引在存数据或比较的时候,先比较联合索引最前面的字段,若最前面的字段值一样,则再比较第二个字段的值;
联合索引的索引字段中有一个值为null,则将其放在叶子节点的最前面;可以认为null值是最小的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号