elasticsearch 基础
搜索引擎是一个检索服务,主要分全文检索和垂直检索。ElasticSearch是分布式的索引库。mysql对外提供检索服务,http或者transport协议对外提供搜索。Restful的json。
一、es的名词定义
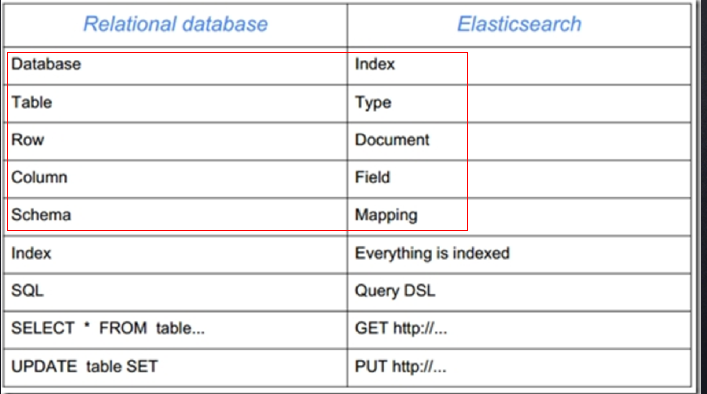
类型(type):es6.x只有一个type,之前可以建很多,es7.x就没有这个type了。
二、分布式索引介绍
1、number_of_shards:分片数量,类似于数据库里面分库分表,一经定义不可更改。主要响应写操作。
为什么分片数量不能更改呢?
分片可以理解是将id进行取余操作,以此来确定数据存放到哪个分片上,如果分片数量更改了,就需要重新计算重建索引了。
分布式索引一定要注意分片数量不能更改,所以在创建的时候一定要预先估算好数据大小,一般在8CPU16G的机器上一个分片不要超过300g。索引会根据分片的配置来均匀的响应用户请求。
2、number_of_replicas:副本数,用于备份分片的,和分片里面的数据保持一致,主要响应读操作,副本越多读取就越快。
4、ES:写请求不管发到哪台机器都会先转发到master机器,由他来确定当前这个doc应该要存储在哪个shards,用的hash取模的方式。
读的时候 不一定要到master,因为每个node里面我们都存了节点信息。
(1)索引写操作在集群上的操作
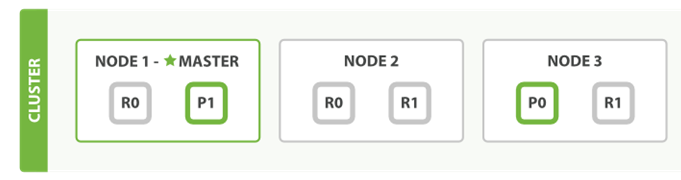
假设我们集群如上面所示:这上面每个节点都可以接收请求,那么新建的一个流程如下所示:
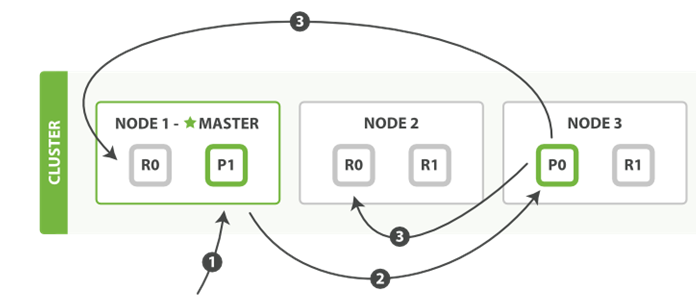
以下是在主副分片和任何副本分片上面 成功新建,索引和删除文档所需要的步骤顺序:
<1> 客户端向 Node1 发送新建、索引或者删除请求。
<2> 节点使用文档的 _id 确定文档属于分片 0。请求会被转发到 Node3 因为分片 0 的主分片目前被分配在 Node3 上。
<3> Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
现在的es版本是可用的shard写入过半,就会发送成功消息给master;如果主分片设置为1副本的时候,那默认的就是主分片写入成功了就会返回成功。
(2)索引读操作在集群上的操作
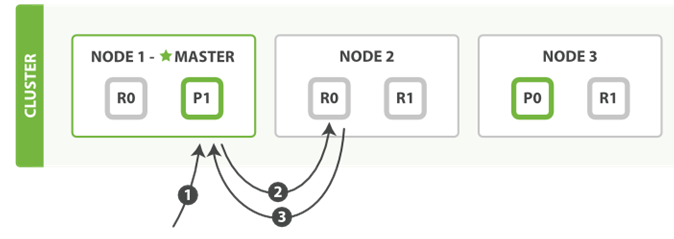
以下是从主分片或者副本分片检索文档的步骤顺序:
<1> 客户端向Node1发送获取请求。
<2> 节点使用文档的_id来确定文档属于分片0,分片0的数据在三个节点上都有。 在这种情况下,它会根据负载均衡策略将请求转发到其中一个,比如Node2 。
<3> Node2将文档返回给Node1然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。
三、ES的基础语法
ES基础数据类型:
Text:字符串类型,可以被分析;
Keyword:不能被分析,只可以精确匹配的字符串类型
Date:日期类型,通常配合format使用 比如{“type”:”date”,”format”:”yyyy-MM-dd”}
Long,integer,short…
Boolean
Array:数组类型
Object:一般是json
Ip:ip地址
geo_point:地理位置 {
“lat”:
“lon”:
}
1、创建索引,默认建立5个分片,1个副本;例如:建立一个名为test的索引;
PUT /test
{}
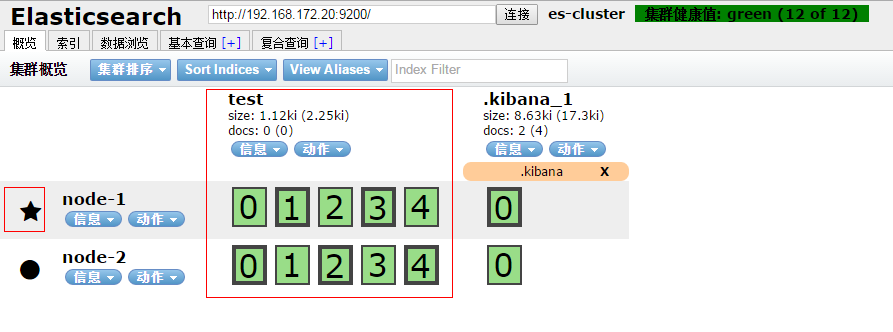
上图可以看到 node-1 和 node2 节点都是有5个分片(0,1,2,3,4),粗线的那个是主分片,细线的是分片的副本;
node-1上的主分片:1,3;node-2的主分片:0,2,4;
五角星的那个节点为 master,即 node-1 为 master 节点。
2、分片数不能调整,副本数可以调整;原来的副本数为1,现在调整为2
PUT /test/_settings
{
"number_of_replicas": 2
}

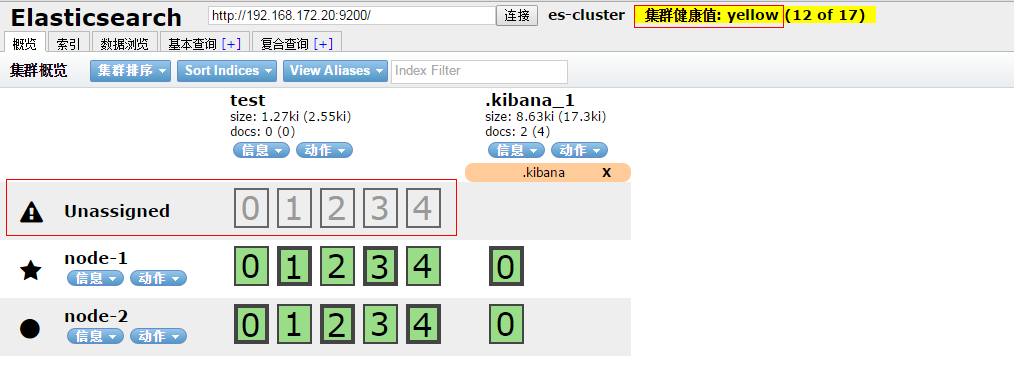
从上图看到:集群的状态变黄,有一个未分配;
因为副本数为2,所以需要再增加一个节点;master一个节点,2个副本两个节点,所以需要有3个节点;
3、创建索引:2个分片,1个副本
PUT /test1
{
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 1
}
4、创建索引的同时指定id (未指定mapping)
PUT /test3/_doc/1
{
"name": "赵云",
"age": 30
}
可以使用 GET /test/_search 查看指定索引中的数据;
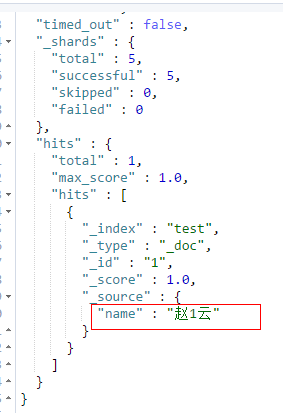
5、指定 id 全量修改索引;(age字段的数据会没有了)
PUT /test/_doc/1
{
"name": "赵1云"
}
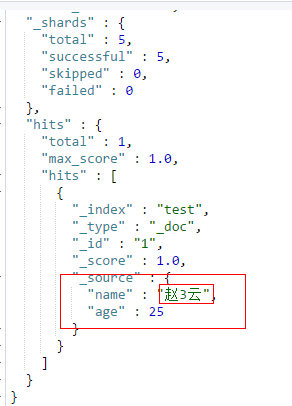
6、指定id部分字断修改
先使用上面的语句将age字段设为25,然后执行下面
POST /test/_doc/1/_update
{
"doc" : {
"name": "赵3云"
}
}
7、指定 _create 防止重复创建,如果已经存在则失败,以下语句执行第二次会报错
POST /test/_doc/2/_create
{
"name":"赵云",
"age":1
}
8、使用搜索全部
GET /test/_search
9、获取指定id
GET /test/_doc/1
10、不指定id建立索引,es会默认给你生成一个;最好自己指定ID
POST /test/_doc/
{
"name": "赵云222",
"age": 30
}
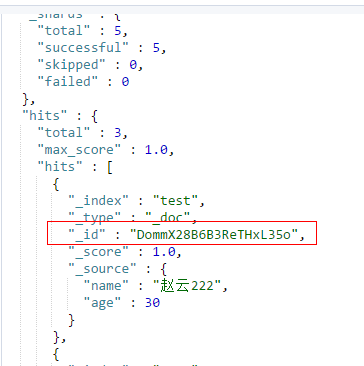
11、删除文档:指定id
delete /test/_doc/1
12、删除索引
DELETE /test
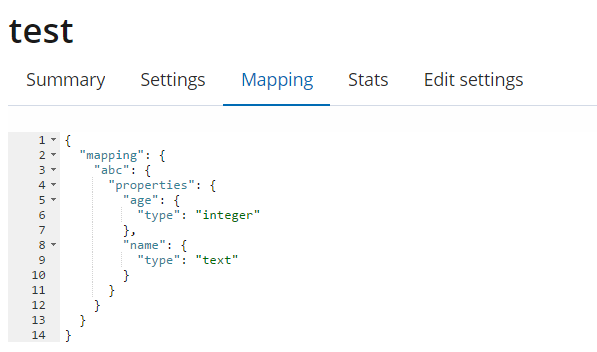
13、结构化创建索引
PUT /test
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"abc":{
"properties": {
"name":{"type": "text"},
"age":{"type": "integer"}
}
}
}
}
注意:上面的 "abc"为 type 的名字,即是关系数据库的表名;
四、ES的基础查询
1、简单查询
(1)主键查询
GET /test/_doc/1
(2)查询所有
GET /test/_search
{
"query":{
"match_all": {}
}
}
(3)分页查询
GET /test/_search
{"from":0,
"size":1
}
注意:ES的分页有个致命的问题,不能查询太多的分页,因为分页是在内存中完成的;最好不要超过1W条。
2、复杂查询
(1)带条件查询
GET /test/_search
{
"query":{
"match": {"name":"赵云1"}
}
}
(2)带排序查询
GET /test/_search
{
"query":{
"match": {"name":"赵云1"}
},
"sort":[
{"age":{"order":"desc"}}
]
}
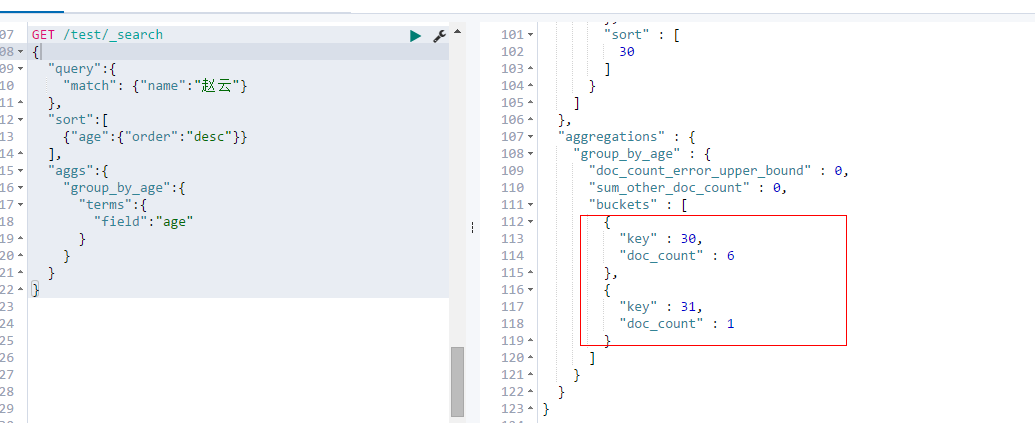
(3)聚合查询;
查询name为赵云相关的集合,接着进行排序,接着进行数据统计age的次数;
GET /test/_search
{
"query":{
"match": {"name":"赵云"}
},
"sort":[
{"age":{"order":"desc"}}
],
"aggs":{
"group_by_age":{
"terms":{
"field":"age"
}
}
}
}
五、ES的分词
ES在存数据的时候会分词建索引存储,在查询的时候查询条件先分词,再去查询;
既有英文又有中文的 直接选ik分词器;
1、英文分词
english分词器:会提取词干和去掉停用词。假设name不采用英文分词。
建立索引:
PUT /test
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc":{
"properties": {
"name":{"type": "text"},
"enname":{"type":"text","analyzer":"english"},
"age":{"type": "integer"}
}
}
}
}
enname 字段使用 英文分词器;
查看英文分词器的分词结果:
GET /test/_analyze
{
"field": "enname",
"text": "my name is zhaoyun and i like eating apples and running."
}
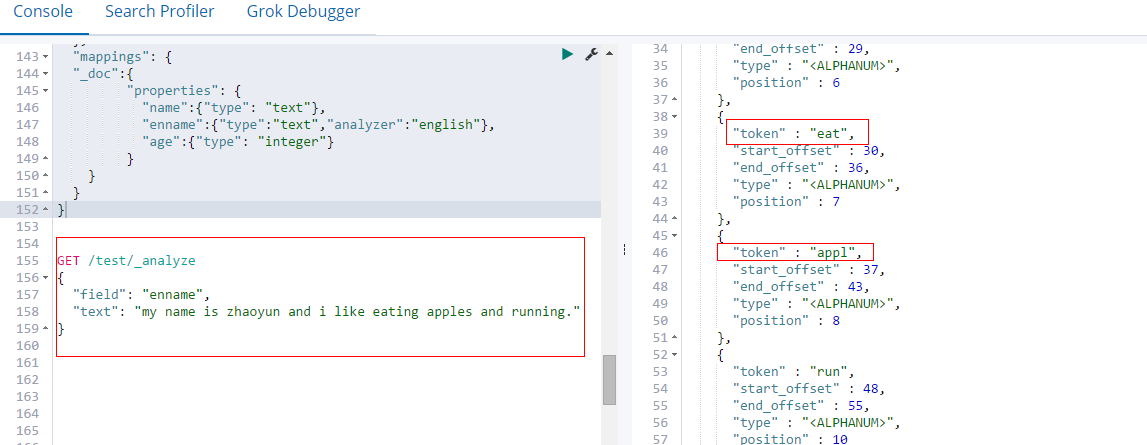
可以看到eating、 running 和 apples 被提取成了词干,提取算法其实就是一个映射。而and 和 is被当作停用词去掉了。
2、中文分词:
(1)默认分词器为stander,这是按照一个个字分分开。优点就是搜的多。
弊端:把每个字都分开,分开的词是要建倒排索引的,这样的话建立索引的时候就比较慢,而且比较占空间;在搜索的时候也会搜出很多不相干的东西,比如在搜张三的时候会把姓张的都搜索出来;
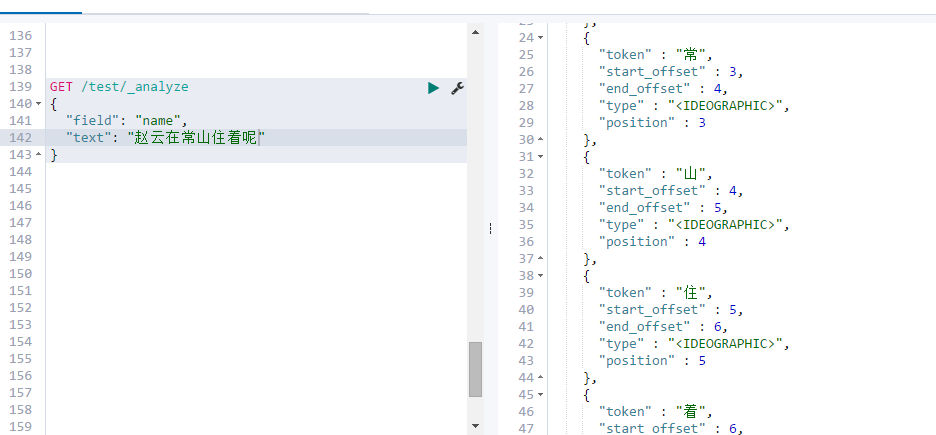
(2)IK分词器:他会有两种模式一种 smart,一种 max_word。建索引的时候 用 ik_max_word,搜索的时候用smart。
<1> 删除索引之后重新新建索引: name的分词器使用 ik_max_word;
PUT /test
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc":{
"properties": {
"name":{"type": "text", "analyzer": "ik_max_word"},
"enname":{"type":"text","analyzer":"english"},
"age":{"type": "integer"}
}
}
}
}
使用分词器进行分词
GET /test/_analyze
{
"field": "name",
"text": "武汉市长江大桥"
}
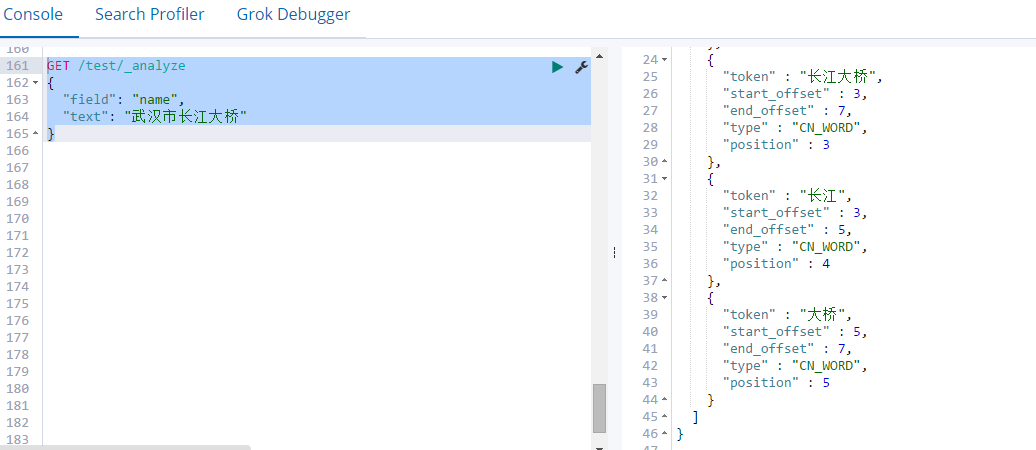
问题:分词的结果中没有 ”江大桥“,我们需要有这个特性的词,怎么办呢?
若我们有特性的词,词库中不存在,那我们可以自己添加;
在 {ES安装目录}/config/analysis-ik/main.dic 文件中增加,然后重启ES;
<2> 删除索引后重建索引, sname 字段的分词使用 ik_smart
PUT /test
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc":{
"properties": {
"name":{"type": "text", "analyzer": "ik_max_word"},
"sname":{"type": "text", "analyzer": "ik_smart"},
"enname":{"type":"text","analyzer":"english"},
"age":{"type": "integer"}
}
}
}
}
使用分词器进行分词
GET /test/_analyze
{
"field": "sname",
"text": "武汉市长江大桥"
}
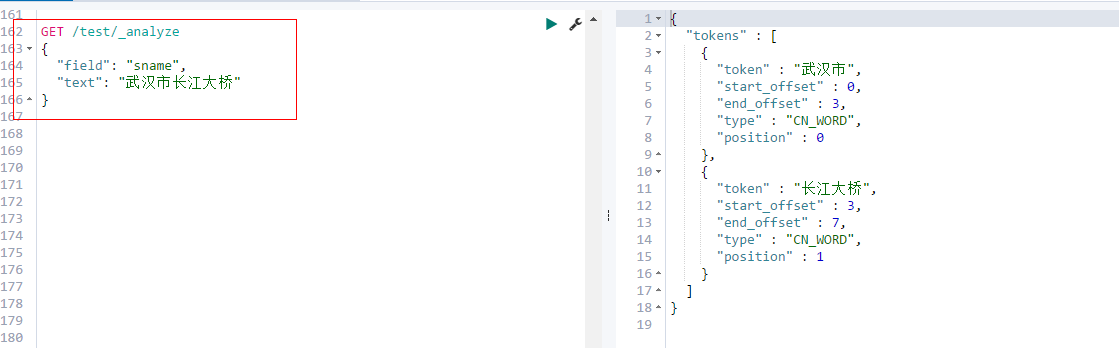
可以看到结果只有两个 "武汉市" 和 "长江大桥"。ik_smart分词使用的贪心算法;
我们在建索引的时候使用 ik_max_word 分词,搜索的时候使用 ik_smart。因为建索引的时候要分的词多,ik_smart的分词包含在了 ik_max_word中,所以查询时候使用 ik_smart ,对于查询也是一种优化。
PUT /test
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc":{
"properties": {
"name":{"type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart"},
"sname":{"type": "text", "analyzer": "ik_smart"},
"enname":{"type":"text","analyzer":"english"},
"age":{"type": "integer"}
}
}
}
}
问题:我们使用 ”江大桥“ 查询的时候没有查询到数据,但是ES中有”武汉市长江大桥“的数据,这个怎么解决?
方法一:
托底:在建了ik的字段,再建一个一样的 stander 的字段。如果ik搜不到 就可以搜这一个 stander 分词的,这样保证会有结果。但是慎用,因为占空间,有些特殊的系统可以使用。
方法二:
砍词:江大桥 我可以砍掉一个词,我砍掉江 就出来了。砍词的策略可以自定义;粗暴的是每次查询去砍掉一个字,然后去查询,直到可以搜索到为止。
方法三:
去词库加词,比如加入江大桥就可以了。具体路径是在es的:{es的安装路径}/config/analysis-ik/main.dic
注意集群的话那就要所有的es都需要加的哦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号