详细见:
https://www.cnblogs.com/liuqingzheng/articles/9833534.html
一、Redis介绍和安装
Redis :软件,存储数据的,速度非常快,redis是一个key-value存储系统(没有表的概念),cs架构的软件
-服务端 客户端(python作为客户端,java,go,图形化界面,命令窗口的命令)
es:存数据的地方
1. 关系型数据库和非关系型数据库
| -关系型:mysql,PostgreSQL,oracle,sqlserver,db2 |
| -PG |
| -去 IOE:国产化 |
| -IBM |
| -Oracle |
| -EMC存储 |
| -非关系型数据库(nosql):redis(缓存),mongodb(json文档数据存储),es(大数据量存储)。。。。 |
| -nosql 指非关系型数据库: no only sql,对关系型数据库的补充 |
2.redis特点:
| -开源软件,存数据,cs架构 |
| -key-value存储 ,5大数据类型 value的类型是5种:字符串,hash(字典),列表,集合,有序集合 |
| -速度快: |
| -1 纯内存存储(核心) |
| -2 使用了IO多路复用的网络模型 |
| -3 数据操作是单线程,避免了线程间切换,而且没有锁,也不会数据错乱 |
| -支持持久化 |
| -纯内存,可以存到硬盘上,防止数据丢失 |
| -redis又被称之为 缓存数据库 |
3.安装redis
| # redis 是用c语言编写的,需要在不同平台编译成可执行文件,才能在这个平台上运行 |
| -redis 使用了io多路复用种的epoll模型,win不支持epoll |
| -redis官方,不支持win版本 |
| -微软官方,就把redis改动,编译成可执行,能运行在win上,滞后 3.x版本 |
| -第三方:5.x版本 |
| |
| # redis 官方网:https://redis.io/download/ |
| # redis中文网:http://redis.cn |
| # win:3.x:https://github.com/microsoftarchive/redis/releases |
| # win:5.x:https://github.com/tporadowski/redis/releases/ |
| |
| |
| # 安装:一路下一步 |
| -安装完成后,在安装路径下有 |
| -redis-cli.exe # mysql |
| -redis-server.exe # mysqld |
| -redis.windows-service.conf # my.ini |
| -并且会自动做成服务 |
| -服务的命令:redis-server.exe redis.windows-service.conf |
| |
| |
| |
| |
| # 启动redis服务端 |
| -1 命令行中 redis-server 就可以启动服务 |
| -2 命令行中,启动服务,并指定配置文件 |
| redis-server 配置文件路径 |
| -3 使用服务启动 |
| |
| # 客户端链接 |
| -1 命令行客户端: |
| -redis-cli # 默认连本地的6379端口 |
| -redis-cli -p 6379 -h 127.0.0.1 |
| -2 图形化客户端链接 |
| -1 最新版的Navicate支持链接redis了(收费的) |
| -2 Redis Desktop Manager(https://resp.app/) 收费的 用的多 qt写图形化界面 |
| -qt是个平台,做GUI[图形化界面]开发 |
| -用c写,用python写 pyqt5 |
| |
| -3 python的模块 |
| -pip install redis |
二、redis普通链接和连接池 二、redis普通链接和连接池
2.1普通链接
| from redis import Redis |
| |
| |
| conn = Redis(host="127.0.0.1", |
| port=6379, |
| db=0,decode_responses=True) |
| res = conn.get('name') |
| print(res) |
| conn.close() |
2.2连接池链接
| |
| |
| |
| import redis |
| POOL = redis.ConnectionPool(max_connections=1000,host='127.0.0.1',port=6379) |
| |
| |
| |
| import redis |
| from pool import POOL |
| conn = redis.Redis(connection_pool=POOL) |
| res = conn.get('name') |
| print(res) |
| conn.close() |
三、操作之String操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
1.set(name, value, ex=None, px=None, nx=False, xx=False)
| 在Redis中设置值,默认,不存在则创建,存在则修改 |
| 参数: |
| ex,过期时间(秒) |
| px,过期时间(毫秒) |
| nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果 |
| xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值 |
2.setnx(name, value)
| |
| 设置值,只有name不存在时,执行设置操作(添加),如果存在,不会修改 |
| setex(name, value, time) |
| |
| |
| |
| |
| psetex(name, time_ms, value) |
| |
| |
| |
| |
3.mset(args,kwargs)
| 批量设置值 |
| 如: |
| mset(k1='v1', k2='v2') |
| 或 |
| mget({'k1': 'v1', 'k2': 'v2'}) |
4.get(name)
| 获取值 |
| mget(keys, *args) |
| |
| 批量获取 |
| 如: |
| mget('k1', 'k2') |
| 或 |
| r.mget(['k3', 'k4']) |
5.getset(name, value)
| 设置新值并获取原来的值 |
| getrange(key, start, end) |
| |
| 复制代码 |
| |
| |
| |
| |
| |
| |
| 复制代码 |
6.setrange(name, offset, value)
7.setbit(name, offset, value)
| |
| |
| |
| |
| |
| |
| |
| |
| 那么字符串foo的二进制表示为:01100110 01101111 01101111 |
| 所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1, |
| 那么最终二进制则变成 01100111 01101111 01101111,即:"goo" |
getbit(name, offset)
bitcount(key, start=None, end=None)
bitop(operation, dest, *keys)
| |
| |
| |
| |
| |
| |
| |
| |
| bitop("AND", 'new_name', 'n1', 'n2', 'n3') |
| |
8.strlen(name)
9.incr(self, name, amount=1)
10.incrbyfloat(self, name, amount=1.0)
| |
| |
| |
| |
| |
| decr(self, name, amount=1) |
| |
| |
| |
| |
| |
| |
11.append(key, value)
| |
| |
| # 在redis name对应的值后面追加内容 |
| |
| # 参数: |
| key, redis的name |
| value, 要追加的字符串 |
| |
四、操作之Hash操作
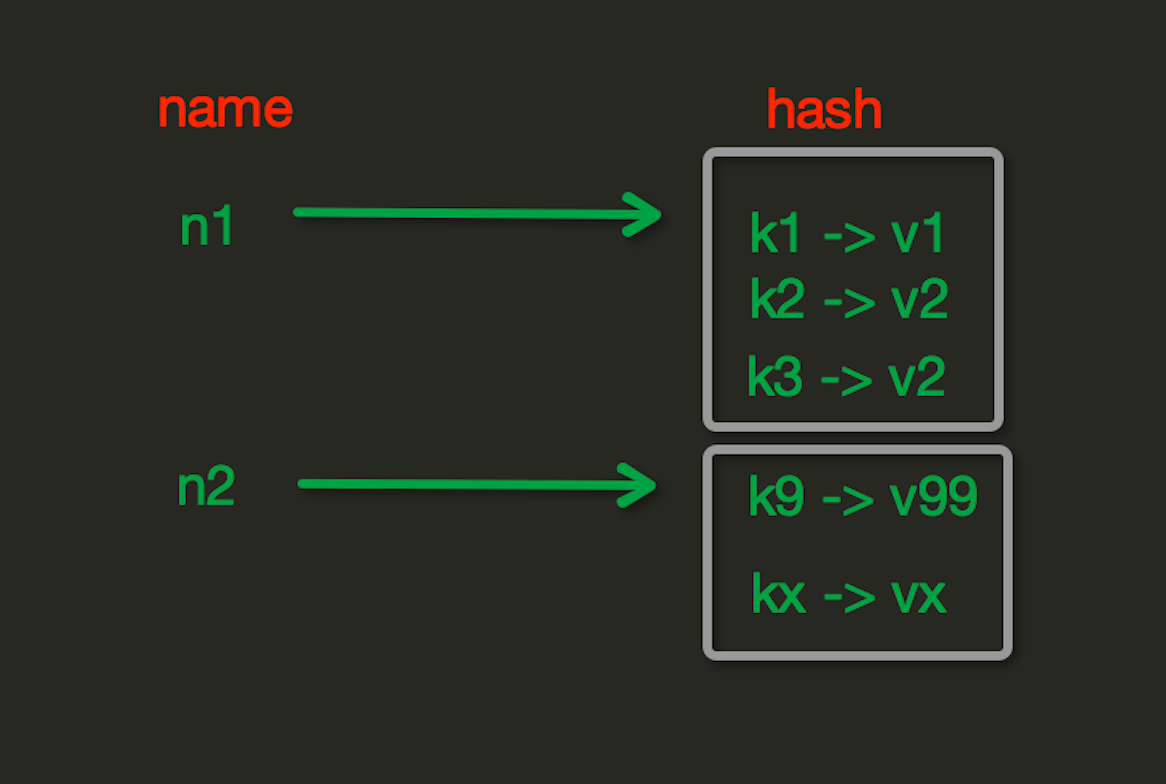
Hash操作,redis中Hash在内存中的存储格式如下图:
hset(name, key, value)
hmset(name, mapping)
| # 在name对应的hash中批量设置键值对 |
| |
| # 参数: |
| # name,redis的name |
| # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} |
| |
| # 如: |
| # r.hmset('xx', {'k1':'v1', 'k2': 'v2'}) |
hget(name,key)
| # 在name对应的hash中获取根据key获取value |
hmget(name, keys, *args)
| |
| # 在name对应的hash中获取多个key的值 |
| |
| # 参数: |
| # name,reids对应的name |
| # keys,要获取key集合,如:['k1', 'k2', 'k3'] |
| # *args,要获取的key,如:k1,k2,k3 |
| |
| # 如: |
| # r.mget('xx', ['k1', 'k2']) |
| # 或 |
| # print r.hmget('xx', 'k1', 'k2') |
hgetall(name)
| |
| print(re.hgetall('xxx').get(b'name')) |
hlen(name)
hkeys(name)
hvals(name)
| # 获取name对应的hash中所有的value的值 |
hexists(name, key)
| # 检查name对应的hash是否存在当前传入的key |
hdel(name,*keys)
| |
| print(re.hdel('xxx','sex','name')) |
hincrby(name, key, amount=1)
hincrbyfloat(name, key, amount=1.0)
hscan(name, cursor=0, match=None, count=None)
| |
| # 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 |
| |
| # 参数: |
| # name,redis的name |
| # cursor,游标(基于游标分批取获取数据) |
| # match,匹配指定key,默认None 表示所有的key |
| # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 |
| |
| # 如: |
| # 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None) |
| # 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None) |
| # ... |
| # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕 |
hscan_iter(name, match=None, count=None)
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| ```python |
| ''' |
| |
| delete(*names) |
| exists(name) |
| keys(pattern='*') |
| expire(name ,time) |
| rename(src, dst) |
| move(name, db)) |
| randomkey() |
| type(name) |
| |
| ''' |
| |
| import redis |
| |
| conn=redis.Redis() |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| res=conn.type('name1') |
| print(res) |
| conn.close() |
五、操作之List操作
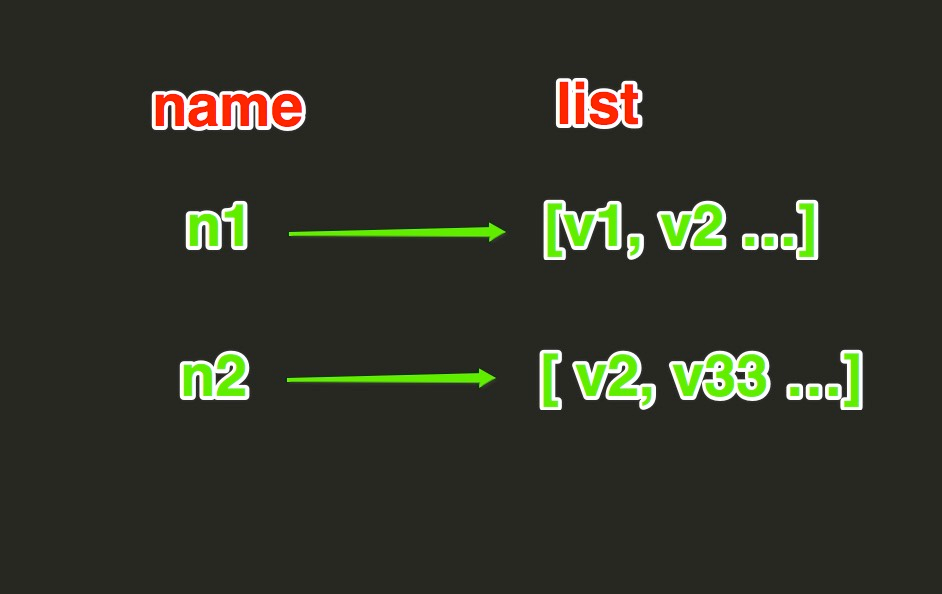
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
lpush(name,values)
lpushx(name,value)
llen(name)
linsert(name, where, refvalue, value))
r.lset(name, index, value)
r.lrem(name, value, num)
lpop(name)
lindex(name, index)
lrange(name, start, end)
| # 在name对应的列表分片获取数据 |
| # 参数: |
| # name,redis的name |
| # start,索引的起始位置 |
| # end,索引结束位置 print(re.lrange('aa',0,re.llen('aa'))) |
ltrim(name, start, end)
rpoplpush(src, dst)
blpop(keys, timeout)
| |
| |
| |
| |
| |
| |
| |
| |
| 爬虫实现简单分布式:多个url放到列表里,往里不停放URL,程序循环取值,但是只能一台机器运行取值,可以把url放到redis中,多台机器从redis中取值,爬取数据,实现简单分布式 |
brpoplpush(src, dst, timeout=0)
| |
| |
| |
| |
| |
| |
| 复制代码 |
| 自定义增量迭代 |
| |
| |
| |
| |
| |
| |
| import redis |
| conn=redis.Redis(host='127.0.0.1',port=6379) |
| |
| |
| def scan_list(name,count=2): |
| index=0 |
| while True: |
| data_list=conn.lrange(name,index,count+index-1) |
| if not data_list: |
| return |
| index+=count |
| for item in data_list: |
| yield item |
| print(conn.lrange('test',0,100)) |
| for item in scan_list('test',5): |
| print('---') |
| print(item) |
六 redis管道
| |
| -原子性:要么都成功,要么都失败 |
| -一致性:数据前后要一致 |
| -隔离性:多个事务之间相互不影响 |
| -持久性:事务一旦完成,数据永久改变 |
| |
| |
| |
| -redis要支持事务,要完成事务的几大特性,需要使用管道来支持 |
| -单实例redis是支持管道的 |
| -集群模式下,不支持管道,就不支持事务 |
| |
| |
| import redis |
| conn = redis.Redis() |
| pipline = conn.pipeline(transaction=True) |
| pipline.decrby('a1', 10) |
| raise Exception('出错了') |
| pipline.incrby('a2', 10) |
| |
| pipline.execute() |
| conn.close() |
| |
七、django中使用redis
| |
| -方式一:自定义的通用方案(跟框架无关) |
| -写一个py文件:redis_pool.py |
| import redis |
| POOL=redis.ConnectionPool(max_connections=10) |
| -在用的位置,导入直接使用 |
| conn = redis.Redis(connection_pool=POOL) |
| conn.incrby('a1') |
| -django中有个模块,django-redis,方便我们快速集成redis |
| -1 下载:pip install django-redis |
| -2 配置文件配置: |
| CACHES = { |
| "default": { |
| "BACKEND": "django_redis.cache.RedisCache", |
| "LOCATION": "redis://127.0.0.1:6379", |
| "OPTIONS": { |
| "CLIENT_CLASS": "django_redis.client.DefaultClient", |
| "CONNECTION_POOL_KWARGS": {"max_connections": 100} |
| |
| } |
| } |
| } |
| |
| -3 在使用的地方,导入直接使用 |
| from django_redis import get_redis_connection |
| class MyResponseView(APIView): |
| def get(self, request): |
| conn = get_redis_connection() |
| conn.incrby('a1') |
| conn.set('name','彭于晏') |
| return APIResponse() |
| |
八、django缓存
| |
| |
| |
| |
| |
| from django.core.cache import cache |
| cache.set('key','value',5) |
| res=cache.get('key') |
| |
| |
| |
| CACHES = { |
| "default": { |
| "BACKEND": "django_redis.cache.RedisCache", |
| "LOCATION": "redis://127.0.0.1:6379", |
| "OPTIONS": { |
| "CLIENT_CLASS": "django_redis.client.DefaultClient", |
| "CONNECTION_POOL_KWARGS": {"max_connections": 100} |
| |
| } |
| } |
| } |
| |
| |
| l = [1, 'lqz', [1, 3, 4, 5, 6], '彭于晏'] |
| cache.set('ll1', l) |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| -公司正常报税,工资中扣 |
| -6月份开始工作,按1w工资报税, 退税 |
补充
| |
| -json序列化---》得到字符串 |
| json不能序列化对象(自定义的类的对象) |
| -数据结构:数据的组织形式跟下面不一样 |
| 能序列化: 数字,字符串,布尔,列表,字典 时间对象 |
| -pickle序列化 |
| -python独有的,二进制形式 |
| -python可以序列化所有对象---》二进制形式 |
| -二进制---》返序列化回来---》对象:属性,有方法 |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步