Kafka 架构
Kafka基础架构

-
Kafka架构中涉及到 Kafka集群(多个Broker)、 生产者(生产消息) 、 消费者(消费消息) 、 zookeeper(注册消息)
-
Kafka集群
- Kafka集群由多个broker组成,每个broker都有唯一的id。
- Kafka内部维护Topics,每个topic可以有多个分区partition,每个partition是一个有序的队列。
- 为了提高可靠性,每个分区可以有多个副本replication,每个副本有各自的角色 'leader/follower',所有的读写都是由leader负责。
说明:
- 每个topic在逻辑上为一个队列,但在物理上被划分为了多个分区,每个消息队列的分区会分布在多个集群上,但集群的各个节点吞吐能力可能不同,此时可以根据不同节点消费的不同分区数据去处理各自区内的吞吐,从而提高吞吐量。
- 每个topic的多个分区可以存在到一个broker。
- 每个Topic的一个分区的多个副本必须在不同的broker。
- 每个Partition 是一个有序的队列。
- Replia 副本: Kafka 提供了副本机制,每个topic的每个分区都有若干个副本,一个leader和若干个follower,用来保证集群某个节点故障时,该节点上的partition数据不丢失。
-
生产者-Producer
- 生产者的主要作用就是面向Topic生产数据,将生产的数据发送给Broker中的Topic。
-
消费者-Consumer
- 消费者主要是以消费者组的名义面向topic进行消息的消费。
说明:
- 每个消费者组中的一个消费者可以同时消费一个topic中的多个分区的数据,但每个topic的一个分区只能被一个消费者组中的一个消费者消费。
- 消费者在消费数据的过程中需要实时记录offset(消费的位置), 记录的方式为: 'group + topic + partition',而offiset在kafka中有一个topic用于专门维护offset,该topic比较特殊,有50个分区和1个副本。
- 消费者组本质上是一个消费者,当一个消费者组中的一个消费者对应一个分区,单个消费者组正好消费完一个topic时效率最高。
-
Zookeeper
-
Kafka中topic之间的协调依赖于zookeeper运行,Zookeeper主要的作用就是让kafka去注册消息。
例如:每个broker启动后会在zookeeper中注册,并 "选举controller" ,实际上就是抢,谁抢到谁是爹,先起的服务器有优势。在低版本0.9之前,消费者维护的offset存储在zk中。在0.9版本之后,消费者维护的offset存储在kafka本地. 注:这与SparkStreaming消费kafka数据的API版本对应。
-
消费者消费数据的两种模式
- 消息队列推送的方式:
- 该模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。推送的方式只能按照消费者消费速率最小的为准,由于消息队列不清楚每个消费者的消费水平,不方便推送。
- 消费者主动拉取的方式:
- 通过消费者自己主动来拉取,但消费者并不知道消息队列是否有消息,所以以长轮询的方式不停的拉取,但是若消息队列中始终没有消息,则会不停的去拉取,效率会很低,所以维护了一个时长参数timeout,如果当前没有数据可供消费,Consumer 会等待一段时间之后再返回,这段时长即为timeout。
Kafka工作流程及文件存储
-
Kafka中消息是以topic进行分类的,生产和消费面向的都是topic,以及用来记录消费者消费信息的位置的offset也是以topic形式。
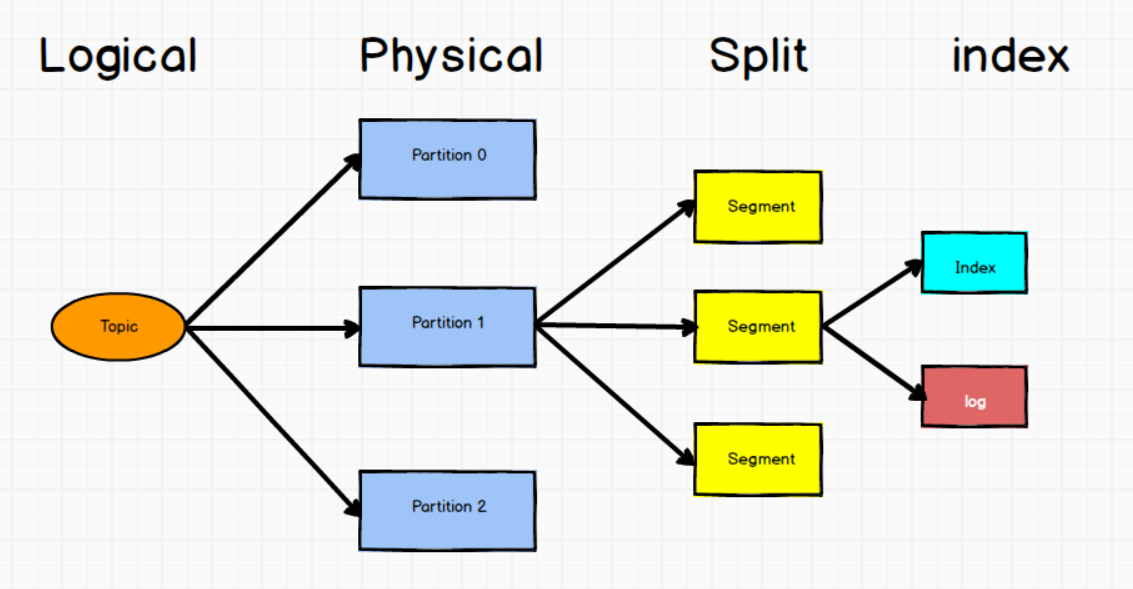
而topic是逻辑上的概念,实际上是以partition存储的,每个partition对应一个log文件,用来存储生产者生产的数据,生产者生产的数据会被不断的的追加到该文件末尾,并且每条数据有自己的offset,用来记录消费者消费到了那条消息,以便出错时恢复到上次消费的位置继续消费消息。但是由于不断的向log文件中追加消息,会导致该文件过大造成效率变低,所以Kafka采用了分片加索引的机制,将每个分区分为多个segment,每个segment默认1个G, 由index和log文件组成, log 文件用来存储消息信息,index 用来存储 offset 以及消息在文件中的物理偏移量。
-
segment:文件命名规则为topic名称+分区序号
-
log、index:文件以当前segment的第一条消息的offset命名,这样将文件划分为不同的区间可以快速定位到某个消息所在的文件。
说明:
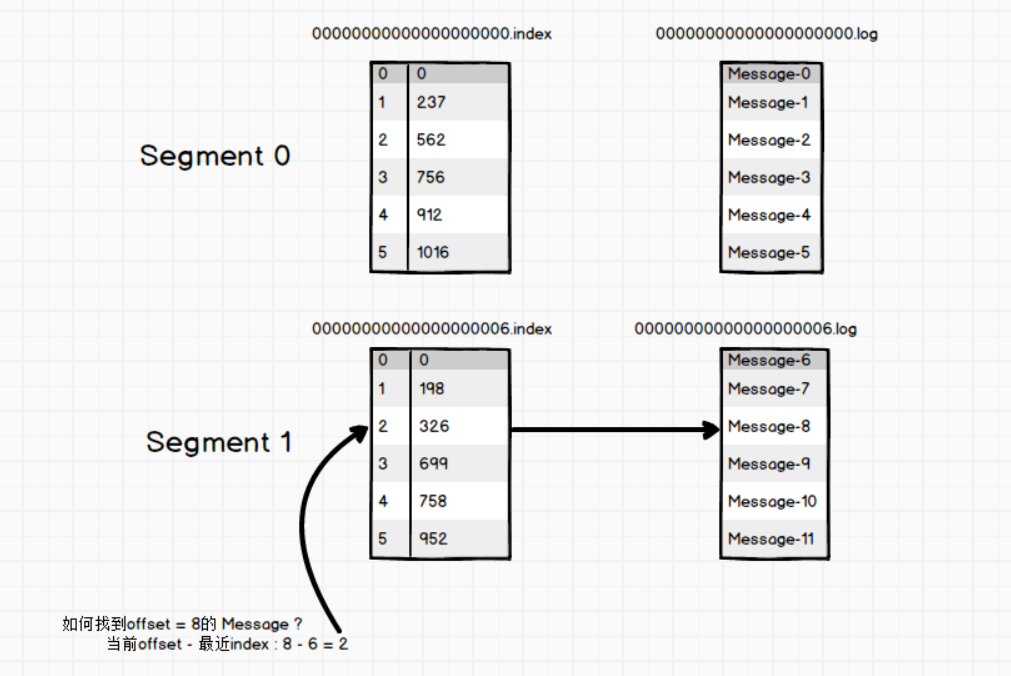
为了避免offset过长导致所占文件空间很大的情况下,每个index的offset都是从0开始的,然后用offset-文件名序号即可。而消息的索引并不是每条消息都有索引,实际上采用的是松散索引,定位了一个范围,每次消费的时候会多查一小部分。
