

hadoop第一课:虚拟机搭建和安装hadoop及启动
(一) 需要用到的软件
virtualbox redhat64(centos7) hadoop-2.7.3.jar jdk8 xshell ftp(我用的是FlashFXP)
所需要的软件,最好到官网上去下载,也可以到百度云盘下载:http://pan.baidu.com/s/1nvkDLbV
(二)安装配置虚拟机
将virualbox安装好后,需要新建一个linux版redhat64的虚拟机,我取名叫master;
特别需要注意的地方:
将虚拟机的网络设置为host-only,我因为忘了设置成host-only,导致新建的虚拟机和宿主机怎么都ping不通,浪费了我一些时间。
选中虚拟机-->设置-->网络,设置如下:

虚拟机网络设置
a) 在设置虚拟机网络前,先设置宿主机的VirtualBox Host-Only Network,
打开网络共享中心-->更改适配器设置,然后设置IP和子网掩码
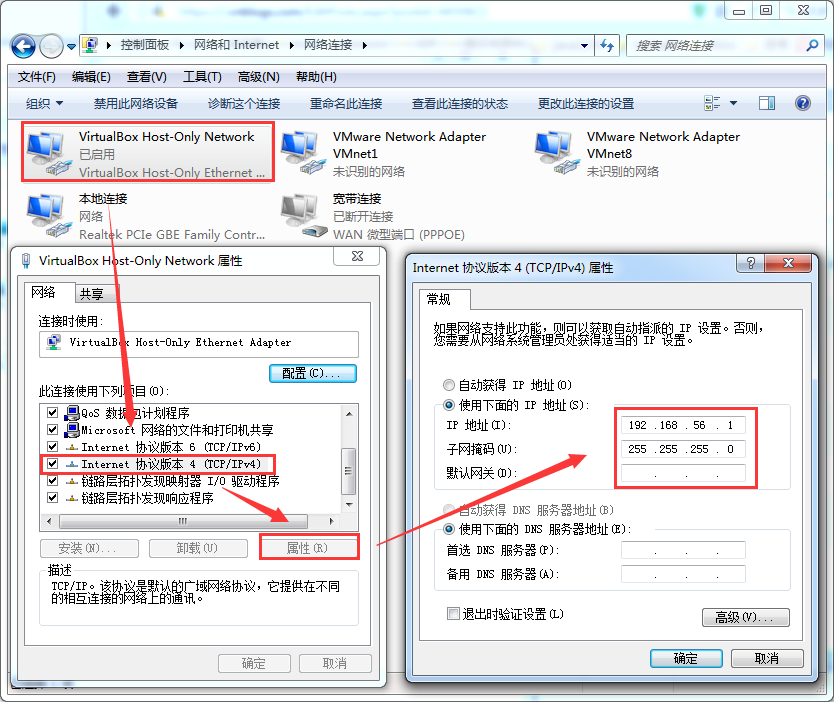
b) 设置虚拟机GATEWAY为192.168.56.1
[root@master ~]# vi /etc/sysconfig/network
#编辑内容如下 NETWORKING=yes GATEWAY=192.168.56.1
c) 设置虚拟机IP和子网掩码

[root@master ~]# vim /etc/sysconfig/network-sripts/ifcfg-enp0s3 #编辑内容如下 TYPE=Ethernet IPADDR=192.168.56.100 NETMASK=255.255.255.0
d) 修改master主机名
主机名千万不能有下划线【重点】
[root@master ~]# hostnamectl set-hostname master
e) 重启master虚拟机网络
[root@master ~]# service network restart
f) 在虚拟机上ping宿主机,在宿主机上ping虚拟机master
[root@master ~]# ping 192.168.56.1 PING 192.168.56.1 (192.168.56.1) 56(84) bytes of data. 64 bytes from 192.168.56.1: icmp_seq=1 ttl=128 time=0.191 ms 64 bytes from 192.168.56.1: icmp_seq=2 ttl=128 time=0.203 ms
C:\Users\Administrator>ping 192.168.56.100 正在 Ping 192.168.56.100 具有 32 字节的数据: 来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64 来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64 来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
互相ping,测试成功,若不成功,注意防火墙的影响,关闭windows或虚拟机防火墙。
systemctl stop firewalld.service
systemctl disable firewalld.service
(3)安装jdk
将已下载好的jdk-8u91-linux-x64.rpm和hadoop-2.7.3.tar.gz,
通过FlashFXP工具(也可以是其他的ftp工具)上传上去,
用xshell连接master虚拟机。
使用rpm进行安装jdk:

默认安装在 /usr/java下面,执行java看到如下输入,即表示java安装成功:

(4)安装hadoop
tar -xvf hadoop-2.7.3.tar.gz
并将解压后的文件hadoop-2.7.3修改成hadoop,执行mv hadoop-2.7.3 hadoop
(5) 配置hadoop的JAVA_HOME
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/default
(6) 配置hadoop的环境变量
vim /etc/profile
在profile文件尾部添加内容如下:
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin
要想使profile文件生效,还要执行指令
[root@master ~]# source /etc/profile
(7)修改master的/usr/local/hadoop/etc/hadoop/core-site.xml,指明namenode的信息
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
这里需要指明一下,core-site.xml里面的配置需要复制到slave虚拟机上,由于采用的是步骤(9)虚拟机复制,这个信息也已经复制过去了。
(8) 测试hadoop命令是否可以直接执行
任意目录下敲 hadoop,打印如下,表示hadoop的环境变量配置成功

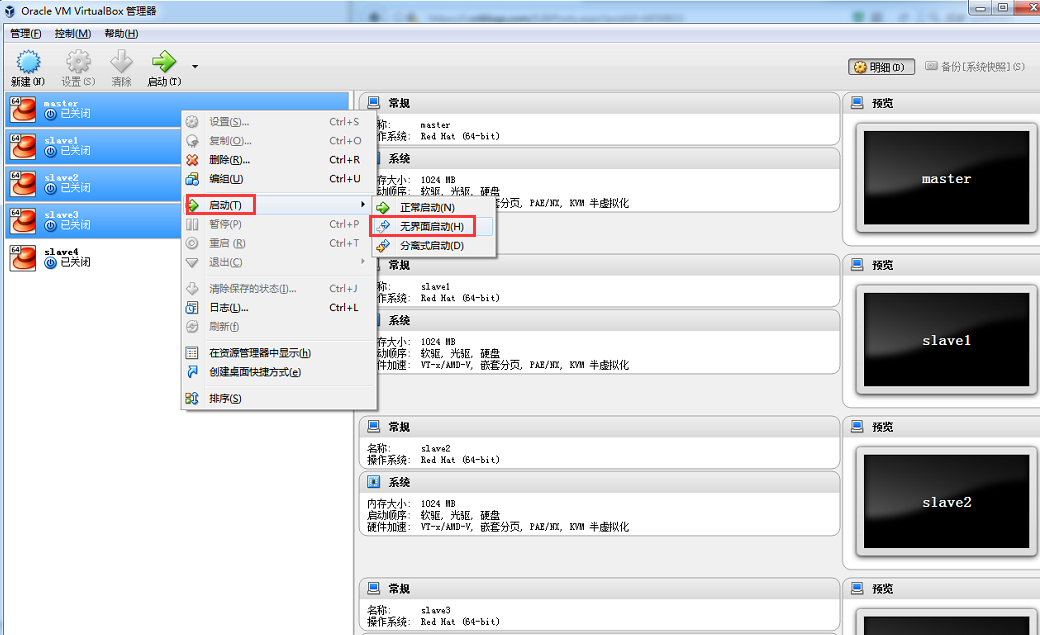
(9) 复制3台虚拟机
关闭master,选中master-->右键-->复制,分别复制出取名为slave1,slave2,slave3的3台虚拟机。

使用无界面启动方式启动4台虚拟机
然后,使用以上步骤(2)中的虚拟机网络配置(b)(c)(d)(e)(f)操作slave1,slave2,slave3,
slave1 设置为IP:192.168.56.101,hostname:slave1
slave1 设置为IP:192.168.56.102,hostname:slave2
slave1 设置为IP:192.168.56.103,hostname:slave3
使用xshell依次登陆上maser,slave1,slave2,slave3四台虚拟机。
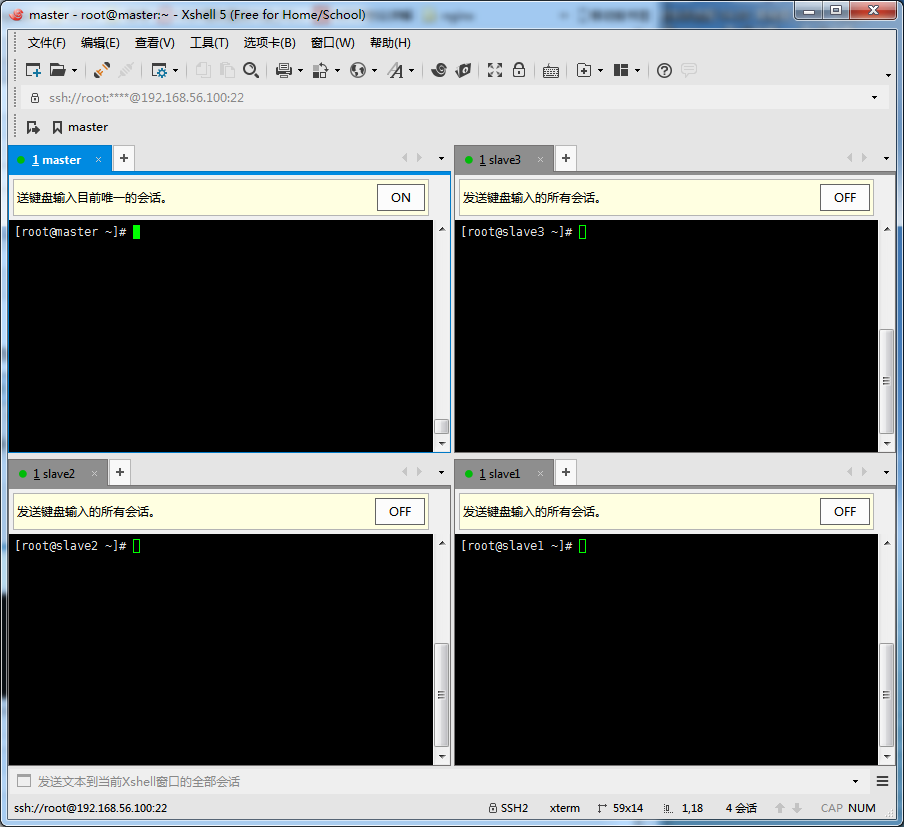
要想达到以上截图中的效果,操作:工具-->发送键输入到所有会话;选项卡-->排列-->瓷砖排序。
(10)搭建集群
在hadoop中,
跑在master机器上的组件/模块/进程有:
namenode,secondarynamenode,resource manager(job tracker),history sever,
跑在slave机器上的有:
datanode,node manager(task tracker)

a) 修改4台机器的/etc/hosts,让他们通过名字认识对方,测试一下互相用名字可以ping通。
192.168.56.100 master 192.168.56.101 slave1 192.168.56.102 slave2 192.168.56.103 slave3
b) 修改master下的/usr/local/hadoop/etc/hadoop/slaves
slave1 slave2 slave3
这样,master就可以知道slave1,2,3对应的IP了。
c) 启动namenode和datanode
master上需要格式化namenode,执行指令:
hadoop namenode -format
启动master上的namenode,在master上执行:
hadoop-daemon.sh start namenode
启动slave上的datanode,在每个slave上执行:
hadoop-daemon.sh start datanode
使用jps查看namenode和datanode的启动情况。

至此,一个master,三个slave的hadoop集群搭建完成并启动成功。

