

MyBatis系列四 映射器(下)
五、参数
虽然在MyBatis中参数大部分是像上面所描述的那样简单,但是我们还是有必要讨论 一下参数的使用。我们可以通过制定参数的类型去让对应的typeHandler处理它们,如果你 不记得typeHandler的用法,请复习下第3章。通过指定对应的JdbcType、JavaType我们可以明确使用哪个typeHandler去处理参数,或者制定一些特殊的东西,但是这里要强调的一 点是:定义参数属性的时候,MyBatis不允许换行!
1、参数配置
正如你们所看到的,我们可以传入一个简单的参数,比如int、double等,也可以传入 JavaBean,这些我们都讨论过。有时候我们需要处理一些特殊的情况,我们可以指定特定 的类型,以确定使用哪个typeHandler处理它们,以便我们进行特殊的处理。
#{age,javaType=int,jdbcType=NUMERIC}
当然我们还可以指定用哪个typeHandler去处理参数。
# {age, javaType=int, jdbcType=NUMERIC, typeHand1e:r=MyTypeHand1er}
此外,我们还可以对一些数值型的参数设置其保存的精度。
# {price,javaType=doeble、jdbcTypc=NUMERUC, numenicScale=2 }
可见MyBatis映射器可以通过EL的功能帮助完成我们所需要的多种功能,使用还是很方便的。
2、存储过程支持
对于存储过程而言,存在3种参数,输入参数(IN)、输出参数(OUT)、输入输出参 数(INOUT)。MyBatis的参数规则为其提供了良好的支持。我们通过制定mode属性来确 定其是哪一种参数,它的选项有3种:IN、OUT、INOUT。当参数设置为OUT,或者为INOUT 的时候,正如你所希望的一样,MyBatis会将存储过程返回的结果设置到你制定的参数中。 当你返回的是一个游标(也就是我们制定JdbcType=CURSOR)的时候,你还需要去设置 resultMap以便MyBatis将存储过程的参数映射到对应的类型,这时MyBatis就会通过你所 设置的resuptMap自动为你设置映射结果。
#{role, mode=OUT,jdbcType=CURSOR,javaType=ResultSet,resu1tMap=:roleResultMap}
这里的javaType是可选的,即使你不指定它,MyBatis也会自动检测它。
MyBatis还支持一些高级特性,比如说结构体,但是当注册参数的时候,你就需要去 指定语句类型的名称(jdbcTypeName),比方说下面的用法。
#{role,mode=OUT, jdbcType=STRUCT, jdbcTypeName=MY_TYPE, resultMap=droleResultMap}
在大部分的情况下MyBatis都会去推断你返回数据的类型,所以大部分情况下你都无 需去配置参数类型和结果类型。要我们设置的往往只是可能返回为空的字段类型而已。因 为null值,MyBatis无法判断其类型。
#{roleNo}, #{roleName}, #{note, jdbcType=VARCHAR}
对于备注而言,可能是返回为空的,用jdbcType=VARCHAR明确告知MyBatis,让它 被 StringTypeHandler 处理即可。
这里我们暂时不给出调度过程和方法,我们会在第9章实用场景中对调度存储过程进 行探讨,届时可以关注它们的使用。
3、特殊字符串替换和处理(#和$ )
在MyBatis中,我们常常传递字符串,我们设置的参数#(name)在大部分的情况下 MyBatis会用创建预编译的语句,然后MyBatis为它设值,而有时候我们需要的是传递SQL 语句的本身,而不是SQL所需要的参数。例如,在一些动态表格(有时候经常遇到根据不 同的条件产生不同的动态列)中,我们要传递SQL的列名,根据某些列进行排序,或者传 递列名给SQL都是比较常见的场景,当然MyBatis也对这样的场景进行了支持,这些是 Hibernate难以做到的。
例如,在程序中传递变量columns= " coll, col2, col3... ”给SQL,让其组装成为SQL 语句。我们当然不想被MyBatis像处理普通参数一样把它设为"coll, col2, col3...",那么 我们就可以写成如下语句。
select ${columns} from
这样MyBatis就不会帮我们转译columns,而变为直出,而不是作为SQL的参数进行 设置了。只是这样是对SQL而言是不安全的,MyBatis给了你灵活性的同时,也需要你自 己去控制参数以保证SQL运转的正确性和安全性。
六、sql兀素
sql元素的意义,在于我们可以定义一串SQL语句的组成部分,其他的语句可以通过引 用来使用它。例如,你有一条SQL需要select几十个字段映射到JavaBean中去,我的第二 条SQL也是这几十个字段映射到JavaBean中去,显然这些字段写两遍不太合适。那么我们 就用sql元素来完成,例如,插入角色,查询角色列表就可以这样定义,如代码清单4.15所示。

这里我们用sql元素定义了 role columns,它可以很方便地使用include元素的refid属 性进行引用,从而达到重用的功能。上面只是一个简单的例子,在真实环境中我们也可以 制定参数来使用它们,如代码清单4.16所示。

这样就可以给MyBatis加入参数,我们还可以这样给refid一个参数值,由程序制定引 入SQL,如代码清单4-17所示。

这样就可以实现一处定义多处引用,大大减少了工作量。
七、resultMap结果映射集
resultMap是MyBatis里面最复杂的元素。它的作用是定义映射规则、级联的更新、定 制类型转化器等。不过不用担心,路还是需要一步步走的,让我们先从最简单的功能开始 了解它。resultMap定义的主要是一个结果集的映射关系。MyBatis现有的版本只支持 resultMap查询,不支持更新或者保存,更不必说级联的更新、删除和修改了。
1、resultMap元素的构成
resultMap元素里面还有以下元素,如代码清单4-18所示。
代码清单4-18: resultMap元素里的元素
<resultMap>
<constructor >
<idArg/>
<arg/>
</constructor>
<id/>
<result/>
<association/>
<collection/>
<discriminator>
<case/>
</discriminator></resultMap>
其中constructor元素用于配置构造方法。一个POJO可能不存在没有参数的构造方法, 这个时候我们就可以使用constructor进行配置。假设角色类RoleBean不存在没有参数的构 造方法,它的构造方法声明为public RoleBean(Integer id, String roleName),那么我们需要配 置这个结果集,如代码清单4-19所示。

这样MyBatis就知道需要用这个构造方法来构造POJO 了。id元素是表示哪个列是主键,允许多个主键,多个主键则称为联合主键。result是配置POJO到SQL列名的映射关系。这里的result和id两个元素都有如表4-5所示的属性。
表4-5 result元素和id元素的属性
|
元素名称 |
说 明 |
备 注 |
|
property |
映射到列结果的字段或属性。如果POJO的 属性匹配的是存在的,和给定SQL列名 (column元素)相同的,那么MyBatis就会映 射到POJO上 |
可以使用导航式的字段,比如访问一个学 生对象(Student)需要访问学生证(selfcard) 的发证日期(issueDate),那么我们可以写成 selfcard.issueDate |
|
column |
这里对应的是SQL的列 |
, .・ |
|
javaType |
配置Java的类型 |
可以是特定的类完全限定名或者MyBatis 上下文的别名 |
|
jdbcType |
配置数据库类型 |
这是一个JDBC的类型,MyBatis己经为 我们做了限定,基本支持所有常用的数据库 类型 |
|
typeHandler |
类型处理器 |
允许你用特定的处理器来覆盖MyBatis默 认的处理器。这就要制定jdbcType和 javaType相互转化的规则 |
此外还有association> collection和discriminator这些元素,我们将在级联那里详细讨 论它们的运用方法。
2、使用map存储结果集
一般而言,任何的select语句都可以使用map存储,如代码清单4-20所示。

使用map原则上是可以匹配所有结果集的,但是使用map接口就意味着可读性的下降, 所以这不是一种推荐的方式。更多的时候我们使用的是POJO的方式。
3、使用POJO存储结果集
使用map方式就意味着可读性的丢失。POJO是我们最常用的方式,也是我们推荐的 方式。一方面我们可以使用自动映射,正如select语句里论述的一样。我们还可以使用select 语句的属性resultMap配置映射集合,只是使用前需要配置类似的resultMap,如代码清单4-21所示。

resultMap元素的属性id代表这个resultMap的标识,type代表着你需要映射的POJO。 我们可以使用MyBatis定义好的类的别名,也可以使用自定义的类的全限定名。
映射关系中,id元素表示这个对象的主键,property代表着POJO的属性名称,column 表示数据库SQL的列名,于是POJO就和数据库SQL的结果一一对应起来了。接着我们 在映射文件中的select元素里面做如代码清单4-22所示的配置,便可以使用了。

我们可以发现SQL语句的列名和roleResultMap的column是一一对应的。使用XML 配置的结果集,我们还可以配置typeHandler、javaType、jdbcType,但是这条语句配置了 resultMap 就不能再配置 resultType 了。
4、级联
在数据库中包含着一对多、一对一的关系,比方说一个角色可以分配给多个用户,也 可以只分配给一个用户。有时候我们希望角色信息和用户信息一起显示出来,这个是很常 见的场景,所以会经常遇见这样的SQL,如代码清单4-23所示。

这里的查询是把角色和用户的信息都查询出来,我们希望的是在角色的信息中多一个 属性,即List<UserBean> userList这样取出Role的同时也可以访问到它下面的用户了。我 们把这样的情况叫作级联。
在级联中存在3种对应关系。其一,一对多的关系,如角色与用户的关系。举个通俗 的例子,一家软件公司存在许多软件工程师,公司和软件工程师就是一对多的关系。其二, 一对一的关系。例如,每个软件工程师都有一个编号(ID),这是它在软件公司的标识,它 与工程师是一对一的关系。其三,多对多的关系。例如,有些公司一个角色可以对应多个 用户,但是一个用户也可以兼任多个角色。通俗而言,一个人可以既是总经理,同时也是 技术总监,而技术总监这个职位可以对应多个人,这就是多对多的关系。
在实际中,多对多的关系应用不多,因为它比较复杂,会增加理解和关联的复杂度。 推荐的方法是,用一对多的关系把它分解为双向关系,以降低关系的复杂度,简化程序。 有时候我们也需要鉴别关系,比如我们去体检,男女有别,男性和女性的体检项目并不完 全一样,如果让男性去检查妇科项目,就会闹出笑话来。
所以在MyBatis中级联分为这么3种:association、collection和discriminator,下面分 别介绍下。
- association,代表一对一关系,比如中国公民和身份证是一对一的关系。
- collection,代表一对多关系,比如班级和学生是一对多的关系,一个班级可以有多
个学生。 - discriminator,是鉴别器,它可以根据实际选择釆用哪个类作为实例,允许你根据特 定的条件去关联不同的结果集。比如,人有男人和女人。你可以实例化一个人的对
象,但是要根据情况用男人类或者用女人类去实例化。
为了方便讲解,我们来建这样一系列数据库表,它们的模型关系,如图4.2所示,我们将以这个例子来讲解MyBatis的resultMap的级联。
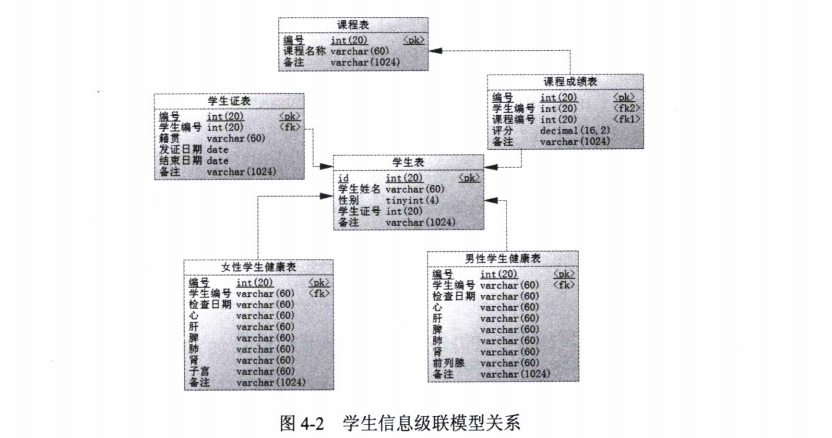
学生信息级联模型关系是一个多种类型关联关系,包含了上述的3种情况,其中学生 表是我们关注的中心,学生证表和它是一对一的关联关系;而学生表和课程成绩表是一对 多的关系,一个学生可能有多门课程;课程表和课程成绩表也是一对多的关系;学生有男 有女,而健康项目也有所不一,所以女性学生和男性学生的健康表也会有所不同,这些是 根据学生的性别来决定的,而鉴别学生性别的就是鉴别器。
(1)association —对一级联
实际操作中,首先我们需要确定对象的关系。仍然以 学生信息级联为例,在学校里 面学生(Student)和学生证(Selfcard)是一对一的关系,因此,我们建立一个StudentBean 和StudentSelfcardBean的POJO对象。那么在Student的POJO我们就应该有一个类型为 StudentSelfcardBean 的属性 studentSelfcard,这样便形成了级联。
这时候我们需要建立Student的映射器StudentMapper和StudentSelfcard的映射器 StudentSelfcardMapper。而在 StudentSelfcardMapper 里面我们提供了一个 findStudentSelfcardByStudentld的方法,如代码清单4-24所示。

有了以上代码,我们将可以在StudentMapper里面使用StudentSelfcardMapper进行级联, 如代码清单4.25所示。


请看上面加粗的代码,这是通过一次关联来处理问题。其中select元素由指定的SQL 去查询,而column则是指定传递给select语句的参数。这里是StudentBean对象的id。当 取出Student的时候,MyBatis就会知道用下面的SQL取出我们需要的级联信息。
com.learn.chapter4.mapper.StudentSelfcardMapper.findstudentSelfcardByStudentld
其中参数是Student的id值,通过column配置,如果是多个参数,则使用逗号分隔。 让我们测试一下代码,如代码清单4.26所示。
代码清单4-26:测试association级联
SqlSession sqlSession = null; try ( sqlSession = SqlSessionFactoryUtil.openSqlSession(); StudentMapper stuMapper = sqlSession.getMapper(StudentMapper.class);
StudentBean stu = stuMapper.getStudent(1); ) finally ( if (sqlSession != null) (
sqlSession.close (); } }
接下来运行这个程序打印日志。

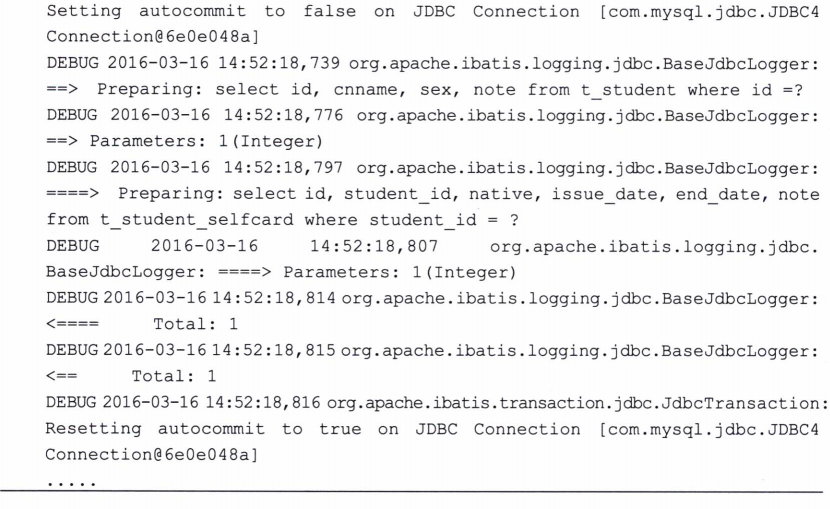
我们看到了整个执行的过程,它先查询出Student的信息,然后根据其id查询出学生 证的信息,而参数是StudentBean对象的id值。这样当我们查找到了 Student的时候,便能 把其学生证的信息也同时取到,这便是一对一的级联。
(2)collection —对多级联
这是一个一对多的级联,一个学生可能有多门课程,在学生确定的前提下每一门课程 都会有自己的分数,所以每一个学生的课程成绩只能对应一门课程。所以这里有两个级联, 一个是学生和课程成绩的级联,这是一对多的关系;一个是课程成绩和课程的级联,这是 一对一的关系。一对一的级联我们使用的是association,而一对多的级联我们使用的是 collection 。
这个时候我们需要建立一个LectureBean的POJO来记录课程,而学生课程表则建立一 个StudentLectureBean来记录成绩,里面有一个类型为LectureBean属性的lecture,用来记 录学生成绩,操作方法如代码清单4-27所示。
代码清单 4-27: LectureBean 和 StudentLectureBean 设计
public class LectureBean {
private Integer id; private String lectureName;
private String note; ...setter and getter.... } #############################################################
public class StudentLectureBean { private int id; private Integer studentld; private LectureBean lecture; private BigDecimal grade; private String note;
...setter and getter....
}
StudentLectureBean包含一个lecture属性用来读取的课程信息,用4.7.4.1节的 association做一对一级联即可。为了能够读入到StudentBean里,我们需要在StudentBean 里面增加一个类型为List<StudentLectureBean>的属性studentLectureList,用来保存学生课 程成绩信息。这个时候我们需要使用collection级联,如代码清单4-28所示。
代码清单4・28:使用collection做一对多级联
###################StudentMapper.xml#####################
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.learn.chapter4.mapper.StudentMapper">
<resultMap id="studentMapn type=ncom.learn.chapter4.po•StudentBean">
<id property="id" column="id" />
<result property="cnname" column="cnname"/>
<result property="sex" column="sex" jdbcType="INTEGER"
javaType="com.learn.chapter4.enums.SexEnum"
typeHandler="com.learn.chapter4.typehandler.SexTypeHandlern/>
<result property="note" column="note"/ >
<association property="studentSeifcard" column ="id" select = "com.learn.chapter4.mapper.StudentSelfcardMapper.findStudentSeifeardByStudentId"/>
<collection property="studentLectureList" column="id" select = "com.learn.chapter4.mapper.StudentLectureMapper.findStudentLectureByStuId"/>
</resultMap>
<select id="getStudent" parameterType="int" resultMap="studentMap">
select id, cnname, sex, note from t_student where id =#{id}
</select>
</mapper>
#####################StudentLectumMapper・xna###########################
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace=ncom.learn.chapter4.mapper.StudentLectureMappern> <resultMap id=nstudentLectureMapH type=ncom.learn•chapter4.po. StudentLectureBeann> <id property=,fidf, column=nidn /> <result property=f, student Id11 column=n s tudent_idn /> <result property=ngraden column=ngraden/> <result property=nnoten column=nnoten/> <association property=nlecturen column =nlecture_idH select=,fcom.learn•chapter4.mapper•LectureMapper.getLecturen/> </resultMap> <select id=n finds tudentLectureByStuId11 parameterType=,,int11 resultMap =nstudentLectureMapn> select id, student_id, lecture_idz grade, note from t_student_lecture where student_id = #{id} </select> </mapper>
###################LectureMapper.xml####################################
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace=ncom.learn.chapter4.mapper.LectureMappern> <select id=ngetLecture1' parameterType=nintn resultType=ncom.learn. chapter4.po.LectureBeann> select id, lecture_name as lectureName, note from t_lecture where id =#{id} </select> </mapper>
我们看到 StudentMapper.xml 用 collection 去关联 StudentLectureBean,其中 column 对 应SQL的列名,这里是用id,属性是Student的studentLectureList,而配置的select为 com.leam.chapter4.mapper.StudentLectureMapper.findStudentLectureByStuId,月么 MyBatis 就 会启用这条语句来加载数据。我们用StudentLectureBean去级联LectureBean信息,它使用了列lecture id作为参数,用对应的select语句进行加载。
我们可以测试一下结果,如代码清单4.29所示。
代码清单4・29:测试一对多级联collection
Logger logger = Logger.getLogger(Chapter4Main.class); SqlSession sqlSession =null; try ( sqlSession = SqlSessionFactoryUtil.openSqlSession (); StudentMapper StudentMapper = sqlSession.getMapper(StudentMapper.class); StudentBean student = StudentMapper.getStudent(1);
logger•info(student.getStudentSelfcard().getNative_());
StudentLectureBean studentLecture = student.getStudentLectureList().get(O); LectureBean lecture = studentLecture.getLecture(); logger•info(student.getCnname() + n\tn + lecture.getLectureName() + n\tn + studentLecture•getGrade()); } finally ( if (sqlSession != null) ( sqlSession.close();
}
}
这样我们就可以看到代码运行的日志了:


我们打出了学生课程成绩信息,代码运行成功了。我们成功地从学生成绩表里取出了 对应的学生成绩,而通过学生成绩表里面的课程id,获得了课程的信息。
(3)discriminator 鉴别器级联
鉴别器级联是在特定的条件下去使用不同的POJOo比如本例中要了解学生的健康情 况,如果是男生总不能去了解他的女性生理指标,这样会闹出笑话来的,同样去了解女生 的男性生理指标也是个笑话。这个时候我们就需要用鉴别器了。
我们可以根据学生信息中的性别属性进行判断去关联男性的健康指标或者是女性的健 康指标,然后进行关联即可,在MyBatis中我们釆用的是鉴别器discriminator,由它来处理 这些需要鉴别的场景,它相当于Java语言中的switch语句。让我们看看它是如何实现的。 首先,我们需要新建两个健康情况的POJO,即StudentHealthMaleBean和StudentHealthFemaleBean,分别存储男性和女性的基础信息,因此我们有了两个StudtentBean的子类:MaleStudentBean和FemeleStudentBean,让我们先看看它们的设计,如代码清单4.30所示。

然后,鉴别是男学生还是女学生。因此,我们找学生信息就要根据StudentBean的属性 sex来确定是使用男学生(MaleStudentBean)还是女学生(FemaleStudentBean)的对象了。 下面让我们看看如何使用discriminator级联来完成这个功能,如代码清单4-31所示。


好了,大段的代码忽略吧,让我们看看加粗的代码。首先我们定义了一个discriminator 元素,它对应的列(column)是sex,对应的java类型(jdbcType)为int,所以才有了下 面这行代码。

接着,我们配置了 case,这里类似switch语句。这样我们就可以在case里面引入 resultMapo当sex=l (男性)时,引入的是maleStudentMap;当sex=2 (女性)时,引入的 是femaleStudentMap,然后我们分别对这两个resultMap进行定义。
这两个resultMap的定义是大同小异,它们都扩展了原有的studentMap,所以有了下面 这行代码。

正如类的继承关系一样,resultMap也可以继承,再加入自己的属性。男学生是 studentHealthMaleList,女学生是studentHealthFemaleList,它们都通过一对多的方式进行 关联。
这样配置的结果就是当Student表中sex=l时,使用MaleStudentBean去匹配结果,然 后使用maleStudentMap中配置的collection去获取对应的男学生的健康指标;同样,当sex=2 时,使用FemaleStudentBean去匹配结果,然后用femaleStudentMap配置的collection去获 取女学生的健康指标。只是无论性别如何,他们都是学生,因为MaleStudentBean和 FemaleStudentBean 都属于 StudentBean。
与男女学生的健康情况相关的Bean和Mapper都很简单,这里限于篇幅就不赘述了, 请读者自己试一试。
让我们测试一下这个级联,代码清单4.26并不需要修改,运行结果如下。
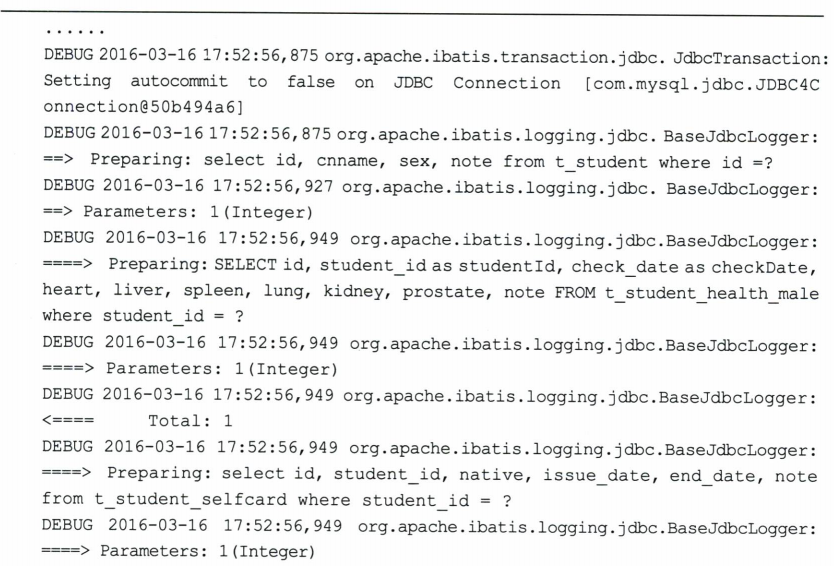
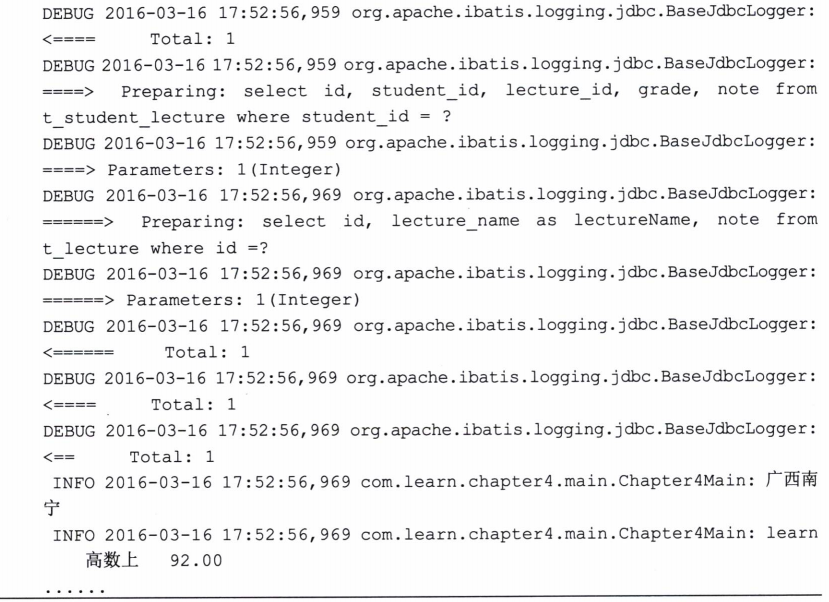
(4)性能分析和N+1问题
级联的优势是能够方便快捷地获取数据。比如学生和学生成绩信息往往是最常用关联 的信息,这个时候级联是完全有必要的。多层关联时,建议超过三层关联时尽量少用级联, 因为不仅用处不大,而且会造成复杂度的增加,不利于他人的理解和维护。同时级联时也 存在一些劣势。有时候我们并不需要获取所有的数据。例如,我只对学生课程和成绩感兴 趣,我就不用取出学生证和健康情况表了。因为取出学生证和健康情况表不但没有意义, 而且会多执行几条SQL,导致性能下降。我们可以使用代码去取代它。
级联还有更严重的问题,假设有表关联到Student表里面,那么可以想象,我们还要增 加级联关系到这个结果集里,那么级联关系将会异常复杂。如果我们釆取类似默认的场景 那么有一个关联我们就要多执行一次SQL,正如我们上面的例子一样,每次取一个Student 对象,那么它所有的信息都会被取出来,这样会造成SQL执行过多导致性能下降,这就是 N+1的问题,为了解决这个问题我们应该考虑釆用延迟加载的功能。
(5)延迟加载
为了处理N+1的问题,MyBatis引入了延迟加载的功能,延迟加载功能的意义在于, 一开始并不取出级联数据,只有当使用它了才发送SQL去取回数据。正如我们的例子,我 开始取出学生的情况,但是当前并未取出学生成绩和学生证信息。此时我对学生成绩感兴 趣,于是我访问学生成绩,这个时候MyBatis才会去发送SQL去取出学生成绩的信息。这 是一个按需取数据的样例。这才是符合我们需要的场景。
在 MyBatis 的配置中有两个全局的参数 lazyLoadingEnabled 和 aggressiveLazy Loadingo lazyLoadingEnabled的含义是是否开启延迟加载功能。aggressiveLazyLoading的含义是对任 意延迟属性的调用会使带有延迟加载属性的对象完整加载;反之,每种属性将按需加载。lazyLoadingEnabled是好理解的,而aggressiveLazyLoading则不是那么好理解了,别担心, 它们很有趣,我们将在下面讨论它们,这样读者便能理解它们的机制了。下面我们将以代 码清单4.32作为例子进行延迟加载的测试工作。

此时让我们配置它们:settings元素里面的lazyLoadingEnabled值开启延迟加载,使得 关联属性都按需加载,而不自动加载。要知道在默认的情况下它是即时加载的,一旦关联多,那将造成不少性能问题啊!为了改变它,我们可以把MyBatis文件的内容配置为延迟 加载,如代码清单4.33所示。

此时再运行一下代码清单4-28,我们便可以看到下面的结果了。

我们从日志中可以知道,当访问学生信息的时候,我们已经把其健康的情况也查找出来了;当我们访问其课程信息的时候,系统同时也把其学生证信息查找出来了。为什么是这样的一个结果呢?那是因为在默认的情况下MyBatis是按层级延迟加载的,让我们看看 这个延迟加载的层级,如图4.3所示。
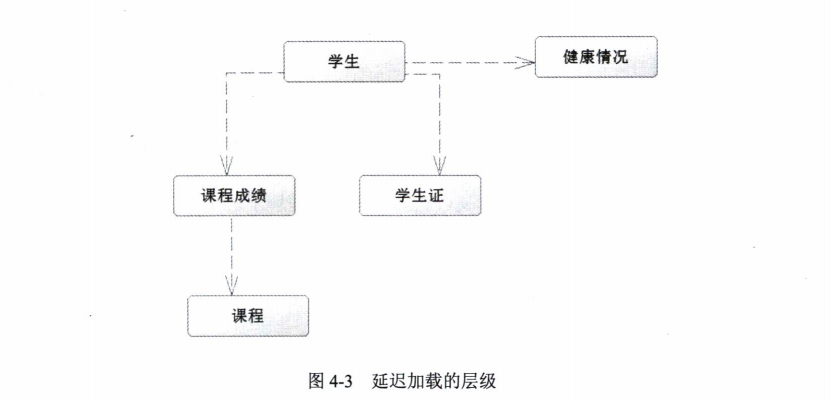
当我们加载学生信息的时候,它会根据鉴别器去找到健康的情况。而当我们访问课程 成绩的时候,由于学生证和课程成绩是一个层级,它也会去访问学生证的信息。然而这并 不是我们需要的,因为我们并不希望在访问学生成绩的时候去加载学生证的信息。那么这 个时候aggressiveLazyLoading就可以用起来了,当它为true的时候,MyBatis的内容按层 级加载,否则就按我们调用的要求加载。所以这个时候我们修改一下MyBatis配置文件中 的代码,在settings元素内加入下面这行代码。

在默认的情况下aggressiveLazyLoading的默认值为true,也就是使用层级加载的策略, 我们这里把它修改为了 falseo我们重新测试代码清单4.32得到日志如下。


我们发现这个时候它就完全按照我们的需要去延迟加载数据了,这就是我们想要的。 那么aggressiveLazyLoading参数的含义,读者应该能够理解了。
上面的是全局的设置,但是还是不太灵活的,为什么呢?因为我们不能指定到哪些属 性可以立即加载,哪些属性可以延迟加载。当一个功能的两个对象经常需要一起用时,我 们釆用即时加载更好,因为即时加载可以多条SQL 一次性发送,性能高。例如,学生和学 生课程成绩。当遇到类似于健康和学生证的情况时,则用延迟加载好些,因为健康表和学 生证表可能不需要经常访问。这样我们就要修改MyBatis全局默认的延迟加载功能。不过 不必担心,MyBatis可以很容易地解决这些问题,因为它也有局部延迟加载的功能。我们 可以在association和collection元素上加入属性值fetchType就可以了,它有两个取值范围, 即eager和lazy。它的默认值取决于你在配置文件settings的配置。假如我们没有配置它, 那么它们就是eagero 一旦你配置了它们,那么全局的变量就会被它们所覆盖,这样我们就 可以灵活地指定哪些东西可以立即加载,哪些东西可以延迟加载,很灵活。例如,我们希 望学生成绩是即时加载而学生证是延迟加载,如代码清单4-34所示。

在测试这段代码的时候我们把aggressiveLazyLoading设置为false,然后运行代码,这 时我们就可以发现再取出Student对象时,课程成绩是一并取出的,而学生证不会马上取出。 这样学生证信息就是延迟加载,而学生成绩是即时加载。同样我们也可以使健康情况延迟 加载,如代码清单4.35所示。


我们把课程成绩和课程表的级联修改为lazy,那么当我们获取StudentBean对象的时候只有学生信息表和成绩表的信息被我们获取,这是我们最常用的功能,其他功能都被延迟加载了,这便是我们需要的功能。让我们看看运行的日志。

我们看到仅仅有两条SQL被执行,一条是查询StudentBean的基本信息,另外一条是查询成绩的。我们访问延迟加载对象时,它才会发送SQL到数据库把数据加载回来。也许读者对延迟加载感兴趣,延迟加载的实现原理是通过动态代理来实现的。在默认情况下,MyBatis在3.3或者以上版本时,是釆用JAVASSIST的动态代理,低版本用的是CGLIBo当然你可以使用配置修改。有兴趣的读者可以参考第6章关于动态代理的内容,它会生成一个动态代理对象,里面保存着相关的SQL和参数,一旦我们使用这个代理对象 的方法,它会进入到动态代理对象的代理方法里,方法里面会通过发送SQL和参数,就可 以把对应的结果从数据库里查找回来,这便是其实现原理。
(6)另一种级联
MyBatis还提供了另外一种级联方式,这种方式更为简单和直接,也没有N+1的问题。 首先,让我们用一条SQL査询出所有的学生信息,如代码清单4.36所示。

这条SQL的含义就是尽量通过左连接(LEFT JOIN)找到其他学生的信息。于是它返回的结果就包含了所有的学生信息。MyBatis允许我们通过配置来完成这些级联信息。正 如在这里配置的一样,我们将通过studentMap2定义的映射规则,来完成这个功能,因此 有必要讨论一下它,让我们先看看studentMap2的映射集,如代码清单4.37所示。


请注意加粗代码,让我们说明一下。
- 第一个association定义的javaType属性告诉了 MyBatis,将使用哪个类去映射这些 字段。第二个associationcolumn定义的是lecture id,说明用SQL中的字段lecture id 去关联结果。
- ofType属性定义的是collection里面的泛型是什么Java类型,MyBatis会拿你定义
- 的java类和结果集做映射。
- discriminator则是根据sex的结果来判断使用哪个类做映射。它决定了使用男生健康 表,还是女生健康表。
这里我们看到了一条SQL就能完成映射,但是这条SQL有些复杂。其次我们是否需 要在一次查询就导出那么多的数据,这会不会造成资源浪费,同时也给维护带来一定的困 难,这些问题都需要读者在实际工作中去考量。
八、缓存 cache
缓存是互联网系统常常用到的,其特点是将数据保存在内存中。目前流行的缓存服务 器有MongoDB、Redis、Ehcache等。缓存是在计算机内存上保存的数据,在读取的时候无 需再从磁盘读入,因此具备快速读取和使用的特点,如果缓存命中率高,那么可以极大地 提高系统的性能。如果缓存命中率很低,那么缓存就不存在使用的意义了,所以使用缓存 的关键在于存储内容访问的命中率。
1、系统缓存(一级缓存和二级缓存)
MyBatis对缓存提供支持,但是在没有配置的默认的情况下,它只开启一级缓存(一 级缓存只是相对于同一个SqlSession而言)。
所以在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用同一个 Mapper•的方法,往往只执行一次SQL,因为使用SqlSession第一次查询后,MyBatis会将 其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没超时的情况下, SqlSession都只会取出当前缓存的数据,而不会再次发送sql到数据库。
但是如果你使用的是不同的SqlSesion对象,因为不同的SqlSession都是相互隔离的,所以用相同的Mapper>参数和方法,它还是会再次发送SQL到数据库去执行,返 回结果。
让我们看看这样的例子,如代码清单4.38所示。


这里我们一共创建了两个SqlSession对象,第一个执行了两次查询,第二个执行了一 次查询,让我们看看其运行的结果。
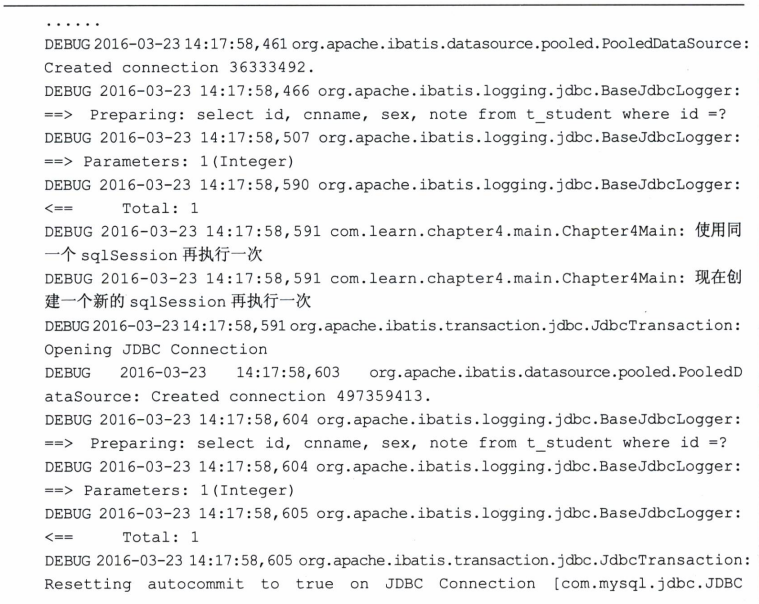
我们发现第一个SqlSession实际只发生过一次查询,而第二次查询就从缓存中取出了,也就是SqlSession层面的一级缓存,它在各个SqlSession是相互隔离的。为了克服这个问 题,我们往往需要配置二级缓存,使得缓存在SqlSessionFactory层面上能够提供给各个SqlSession对象共享。而SqlSessionFactory层面上的二级缓存是不开启的,二级缓存的开启需要进行配置, 实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的,也就是要求实现 Serializable接口,配置的方法很简单,只需要在映射XML文件配置就可以开启缓存了。

这样的一个语句里面,很多设置是默认的,如果我们只是这样配置,那么就意味着:
- 映射语句文件中的所有select语句将会被缓存。
- 映射语句文件中的所有insert、update和delete语句会刷新缓存。
- 缓存会使用默认的Least Recently Used (LRU,最近最少使用的)算法来收回。
- 根据时间表,比如No Flush Interval, (CNFL没有刷新间隔),缓存不会以任何时 间顺序来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用。
- 缓存会被视为是read/write (可读/可写)的缓存,意味着对象检索不是共享的,而 且可以安全地被调用者修改,不干扰其他调用者或线程所做的潜在修改。
添加了这个配置后,我们还必须做一件重要的事情,否则就会出现异常。这就是MyBatis 要返回的POJO对象要实现Serializable接口,否则它就会抛出异常。做了这些修改后,我 们再次测试代码清单4-38,得到如下日志。

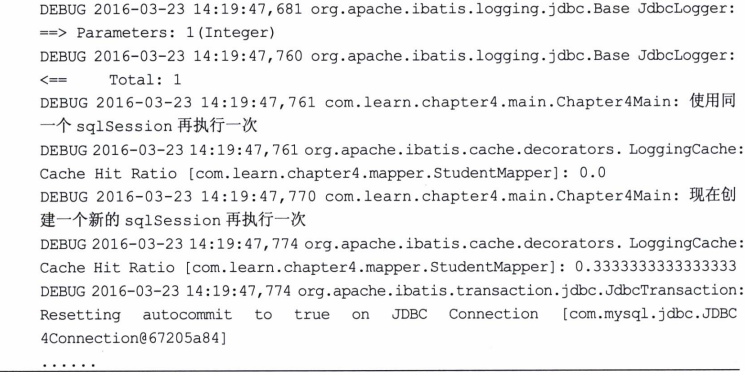
显然我们从头到尾只执行了一次SQL,都是从二级缓存中得到我们需要的数据,这就 说明二级缓存是在SqlSessionFactory层面所共享的。
当然我们也可以修改它们,代码清单4-39是使用其属性来修改的。

这里我们讨论一下它们的属性。
- eviction:代表的是缓存回收策略,目前MyBatis提供以下策略。
- LRU,最近最少使用的,移除最长时间不用的对象。
- FIFO,先进先出,按对象进入缓存的顺序来移除它们。
- SOFT,软引用,移除基于垃圾回收器状态和软引用规则的对象。
- WEAK,弱引用,更积极地移除基于垃圾收集器状态和弱引用规则的对象。这里 采用的是LRU,移除最长时间不用的对象。
- flushinterval:刷新间隔时间,单位为毫秒,这里配置的是100秒刷新,如果你不配 置它,那么当SQL被执行的时候才会去刷新缓存。
- size:引用数目,一个正整数,代表缓存最多可以存储多少个对象,不宜设置过大。 设置过大会导致内存溢出。这里配置的是1024个对象。
- readonly:只读,意味着缓存数据只能读取而不能修改,这样设置的好处是我们可 以快速读取缓存,缺点是我们没有办法修改缓存,它的默认值为false,不允许我们 修改。
2、自定义缓存
系统缓存是MyBatis应用机器上的本地缓存,但是在大型服务器上,会使用各类不同 的缓存服务器,这个时候我们可以定制缓存,比如现在十分流行的Redis缓存。我们需 要实现MyBatis为我们提供的接口 org.apache.ibatis.cache.Cache,缓存接口简介如代码清 单4-40所示。

因为每种缓存都有其不同的特点,上面的接口都需要我们去实现,假设我们已经有一 个实现类com.leam.chapter4.MyCache,那么我们需要如代码4.41所示的配置。

我们完成上述设置就能使用自定义的缓存了。而在缓存中你往往需要定制一些常用的 属性,MyBatis也对其做了支持,如代码清单4-42所示。

如果我们在MyCache这个类增加setHost (String host)方法,那么它在初始化的时候 就会被调用,这样你可以对自定义设置一些外部参数。我们在映射器上可以配置insert、delete> select> update元素,对应增、删、查、改这些内容。我们也可以配置SQL层面上的缓存规则,来决定它们是否需要使用或者刷新缓存,我们往往是根据两个属性:useCache和flushCache来完成的,其中useCache表小是否需要使用缓存,而flushCache表示插入后是否需要刷新缓存。请看一个例子,如代码清单4.43所示。


