Linear least squares, Lasso,ridge regression有何区别?
转自:杨军 https://www.zhihu.com/question/38121173/answer/85813729
线性回归问题是很经典的机器学习问题了。
适用的方法也蛮多,有标准的Ordinary Least Squares,还有带了L2正则的Ridge Regression以及L1正则的Lasso Regression。
这些不同的回归模型的差异和设计动机是什么?
在本帖的一个高票回答[1]里,把这个问题讨论得其实已经相当清楚了。
我在这里的回答更多是一个知识性的总结,在Scott Young的《如何高效学习》[6]里提到高效学习的几个环节: 获取、理解、拓展、纠错、应用、测试。
在我来看,用自己的语言对来整理对一个问题的认识,就是理解和扩展的一种形式,而发在这里也算是一种应用、测试兼顾纠错的形式了。
首先来看什么是回归问题,直白来说,就是给定
其中映射函数
未知,但是我们手上有一堆数据样本
,形式如下:
我们期望从数据样本里推断出映射函数
,满足
即期望推断出的映射函数在数据样本上与真实目标的期望差异尽可能最小化。
通常来说,数据样本中每个样本的出现频率都可以认为是1,而我们要推断的映射函数可以认为是
一个线性函数
其中
就是我们要推断的关键参数了。
这样的问题就是线性回归(Linear Regression)问题。
Ordinary Linear Square的求解方法很直白,结合上面的描述,我们可以将
具像化为求解函数
的最小值以及对应的关键参数。
对于这个目标函数,我们可以通过求导计算[2],直接得出解析解如下 :
当然,这是一个典型的Convex优化问题,也可以通过迭代求优的算法来进行求解,比如Gradient Descent或者Newton法[2]。
看起来不错,那么为什么我们还要在OLS的基础上提供了Ridge Regression(L2正则)和Lasso Regression(L1正则)呢?
如果说得笼统一些的话,是为了避免over-fit,如果再深入一些,则可以这样来理解:
不引入正则项的OLS的解很可能会不stable,具体来说,两次不同的采样所采集到的训练数据,用于训练同一个线性回归模型,训练数据的些微差异,最终学出的模型差异可能是巨大的。在[3]里有一个例子:

还是在[3]里,提供了一个定量的证明:

结果的证明细节,有兴趣的同学可以自己去查阅,这里直接把关键点引用如下:
一个有名的病态矩阵是Hilbert矩阵[4],其形如下:
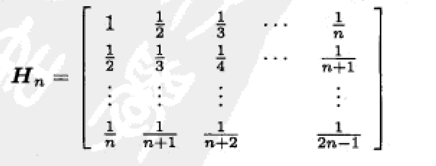
再回到我们关于OLS的讨论,我们不难看出,随着训练样本采样次数的增加,采样到病态阵的概率会增多,这样一来学出的模型的稳定性就比较
差。想象一下,今天训练出来的模型跟明天训练出的模型,存在明显的模型权值差异,这看起来并不是一件非常好的事情。
那么病态阵的根本原因是什么呢?条件数的描述还是相对有些抽象,所以这里又引入了奇异阵的概念。
什么是奇异阵呢?
形式化来说,不存在逆矩阵的方阵(因为OLS的闭式解里,需要求逆的矩阵是
一定是一个方阵,所以这里仅讨论方阵这一特殊形态)就是奇异阵,即
那么再具体一些,什么样的方阵会不存在逆呢?
非满秩、矩阵的特征值之和为0、矩阵的行列式为0。
满足这三个条件中的任意一个条件,即可推出方阵为奇异阵,不可求逆,实际上这三个条件是可以互相推导出来的。
而我们又知道,一个方阵的逆矩阵可以通过其伴随矩阵和行列式求出来[7]
从这里,其实可以看的出来,对于近似奇异阵,其行列式非常接近于0,所以
会是一个非常大的数,这其实反映出来就是在计算A的逆矩阵时,伴随矩阵上的些微变化,会被很大程度上放大,就会导致多次采样出来的训练数据,学出的模型差异很大,这是除了上面提到的条件数以外的另一种比较形象的解释了。
如果类比普通代数的话,奇异阵就好比是0,0不存在倒数,越接近0的数,其倒数越大,同样,奇异阵不存在逆矩阵,而接近奇异阵的逆矩阵的波动也会比较大。
所以跟奇异阵有多像(数学语言里称为near singularity),决定了我们的线性回归模型有多么不稳定。
既然知道了奇异阵的性质并且了解到是奇异阵使得从训练数据中学出来的线性回归模型不那么稳定,那么我们是不是可以人为地通过引入一些transformation让
长得跟奇异阵不那么像呢?
我们知道
于是一个直观的思路是在方阵的对角线元素上施加如下的线性变换
其中
是单位阵。
有了上面的变换以后,对角线的元素为全零的概率就可以有效降低,也就达到了减少
near singularity的程度,进而减少线性回归模型不稳定性的目的了。
那么这个变换跟Ridge或是Lasso有什么关系呢?
实际上,
(7.6)
正是对下面的
这个优化问题为
计算闭式解得到的结果(在[2]里OLS的闭式解的推导过程里加入二范数正则项,蛮自然地就会得到7.6里的结果,[8]里也有类似的推论)。
而(7.7)正是Ridge Regression的标准写法。
进一步,Lasso Regression的写法是
这实际上也是在原始矩阵上施加了一些变换,期望离奇异阵远一些,另外1范数的引入,使得模型训练的过程本身包含了model selection的功能,在上面的回复里都举出了很多的例子,在一本像样些的ML/DM的教材里也大抵都有着比形象的示例图,在这里我就不再重复了。
一个略微想提一下的是,对于2范数,本质上其实是对误差的高斯先验,而1范数则对应于误差的Laplace先验,这算是另一个理解正则化的视角了。
只不过1范数的引入导致优化目标不再处处连续不能直接求取闭式解,而不得不resort到迭代求优的方法上了,而因为其非处处连续的特点,
即便是在迭代求优的过程中,也变得有些特殊了,这个我们可以在以后讨论OWLQN和LBFGS算法的时后再详细引出来。
转自 党元初


 浙公网安备 33010602011771号
浙公网安备 33010602011771号