Snort规则
一、Snort简介
如果病毒一样,大多数入侵行为都具有某种特征,Snort的规则就是用这些特征的有关信息构建的。入侵者会刘勇已知的系统弱点数据库吗,如果入侵者试图利用这些弱点来实施攻击,也可以作为一些特征。这些特征可能出现在包的头部,也可能出现在载荷中。Snort的检测系统是基于规则的,而规则是基于特征的。Snort规则可以用来检测数据包的不同部分。Snort 1.x可以分析第3等和第4层的信息,但是不能分析应用层协议。Snort 2.x增加了对应用层头部的支持。所有的数据包根据类型的不同按顺序与规则比对。
规则可以用来产生告警信息、记录日志,或者使包通过(pass):对Snort来说,也就是悄悄丢弃(drop),通过在这里的意义与防火墙或路由器上的意义是不同的。在防火墙和路由器中,通过和丢弃是两个相反的概念。规则文件通常放置在snort.conf文件中,你可以用其他规则文件,然后用主配置文件引用它们(#include 的方式,在snort 2.x主要是用过主文件引用)。
二、规则示例
2.1 第一个不可用规则
这里有一个非常不好用的规则,事实上,也许是最差的规则,但是它可以很好地检测snort是否正常工作,并可以产生告警:
alert ip any any -> any any (msg: "IP Packet detected";)
这个规则使每当捕获一个IP包都产生告警信息,下面简要解释一下该条规则所用的语句:
- "alert"表示如果包与条件匹配,就产生一个告警信息。条件由下面的语句定义
- "ip"表示规则奖杯用在所有的IP包上
- 第一个"any"是对IP包源地址部分的条件定义,表示来自任何一个IP地址的IP包都符合条件,任何IP包都符合本条件
- 第二个"any"用来定义源端口号,表示匹配任何(0 ~ 65535)端口号,本条规则匹配IP报文,所以端口号其实无任何意义,因为端口号只针对传输层协议(TCP、UDP)生效
- 第三个"any"是对IP包目的地址部分的条件地址,any表示这条规则匹配所有的目的地址
- 第四个"any"用来定义目的端口条件,在此条规则中同样不生效
- 最后一部分是规则的选项,并包含一条将被记录的告警信息
2.2 规则的结构
所有的规则都可以分为两个逻辑组成部分:规则头部和规则选项
| 规则头部 | 规则选项 |
|---|
规则的头部包含规则所做的动作的信息,也可以包含于包所对比的一些条件。选项部分通常包含一个告警信息以及包的哪个部分被用来产生这个信息。一条规则可以用来探测一个或多个类型的入侵活动,一个好的规则可以用来探测多种入侵特征。
| 动作 | 协议 | 地址 | 端口 | 方向 | 地址 | 端口 |
|---|
动作部分表示,当规则与包比对并不符合条件时,会采取什么类型的动作。通常的动作时产生告警或记录日志或向其他规则发出请求。
协议部分用来在一个特定协议的包上应用规则。这是规则所涉及 的第一个条件,一些可以用到的协议如:IP,ICMP,UDP,TCP等
地址部分定义源或目的地址。地址可以是一个主机,一些主机的地址或者网络地址。你也可以用这些部分将某些地址从网络中排除。注意,在规则中有两个地址段,依赖于方向决定地址是源或者是目的,例如,方向段的值是"->"那么左边的地址就是源地址,右边的地址就是目的地址。
如果协议是TCP、UDP,端口部分用来确定规则所对应的包的源及目的端口。如果是网络层协议,如IP或ICMP,端口号就没有意义了。
方向部分用来确定哪一边的地址和端口是源,哪一边是目的在。
示例:
alert icmp any any -> any any (msg: "Ping with TTL=100"; ttl:100;)
括号之前的部分叫做规则头部,括号中的部分叫做规则选项。头部一次包括下面部分:
- 规则的动作:在这个规则中,动作是alert(告警),就是如果符合下面的条件,就会产生告警。记住如果产生告警,默认的情况下是会记录日志的。
- 协议:在这个规则中,协议时ICMP,也就是说这条规则仅仅对ICMP包有效,如果一个包的协议不是ICMP,Snort探测引擎就不会理会这个包已节省CPU事件。协议部分在你对某种协议的包应用snort规则的时候是非常重要的。
- 方向。这在个示例中,方向用->表示从左向右的方向,表示在这个符号的左面部分是源,右面是目的,也表示规则引用在从源到目的的包上。如果是<-,那么久相反。注意,也可以用<>来表示规则将应用在所有方向上。
- 目的地址和端口,在这个示例中。它们都是"any",表示规则并不关心它们的目的地址。在这个规则中,由于any的作用,方向段并没有实际的作用,因为它将被应用在所有方向的ICMP包上。
在括号中的选项部分表示:如果包符合TTL=100的条件就产生一条包含文字:"Ping with TTL=100"的告警。TTL是IP包头部字段。
三、规则详解
3.1 规则头部
3.1.1 规则动作
动作是snort规则中的第一个部分,它表示规则的条件符合的时候,将会有什么样的动作产生。Snort有5个预定义动作,你也可以定义自己的动作,需要注意的是,Snort 1.x 和 2.x对规则的应用是不同的,在1.x中,只要包符合第一个条件,它就会做出动作,然后就不再管它,尽管它可能符合多个条件;在2.x中,只有包和所有的相应规则对比后,才根据最严重的情况发出告警。
3.1.1.1 pass
这个动作高速Snort不理会这个包,这个动作在你不想检查特定的包的时候可以加快Snort的操作速度。例如:如果你在网络中有一台包含一些弱点的主机,用来检测网络安全漏洞,可能希望不理会对这台机器的攻击,pass规则这时就可以用到了。
3.1.1.2 log
log动作用来记录包,记录包有不同的方式,例如:可以记录到文件或者数据库。根据命令行参数和配置文件,包可以被记录为不同的详细程度。你可以用"snort -?"命令来查看你所用的Snort版本的命令行参数。
3.1.1.3 alert
alert动作用来在一个包符合规则条件时发送告警信息。告警的发送有多种方式,例如可以发送到文件或者控制台。log动作与alert动作不同在于:alert动作是发送告警然后记录包,log动作仅仅记录包。
3.1.1.4 dynamic
dynamic规则动作由其他activate动作的规则调用,在正常情况下,他们不会被用来检测包。一个动态规则仅能被一个"activate"动作激活。
3.1.1.5 自定义动作
除了以上动作外,你也可以定义自己的动作,以用于不同的目的,例如:
- 向syslog发送消息。Syslog是系统日志守护进程,它在/var/log中创建日志文件,这些文件的位置可以通过修改/etc/syslog.conf来改变。你可以在unix系统中用命令"man syslog"或者"man syslog.conf"来获取更多的信息。Syslog相当于Windows中的事件查看器。
- 向如HP OpenView等网管系统发送SNMP trap
- 在一个包上引用多个动作。如你前面所看到的,一个规则仅仅规定了一个动作,自定义动作可以用来产生多个动作。例如:你可以在发送SNMP trap的同时记录Syslog
- 将数据记录到XML文件中
- 将信息记录到数据库中,Snort可以将数据记录到MySQL,Postgress SQL,Oracle和Microsoft SQL server中
这些新的动作类型在配置文件snort.conf中定义。一个新动作用下面的通用结构来定义:
ruletyoe action_name
{
action definition
}
关键字ruletype后面跟随动作的名称,连个大括号中是实际的动作定义,类似于c语言中的函数。例如:我们定义一个叫做smb_db_alert的动作,用来向workstation.list中的主机发送SMB告警,同时在MySQL中的"snort"数据库记录,如下所示:
ruletype smb_db_alert
{
type alert
output alert_smb: workstation.list
output database: log,mysql,user=root password=root dbname=snort hsot=localhost
}
3.1.2 协议
协议是Snort规则中的第二部分,这一部分将显示哪种类型的包将与规则比对。到目前为止,Snort可以支持以下协议:
- IP
- ICMP
- TCP
- UDP
如果协议是IP,Snort检测包中的数据链路层头部来确定包的类型,如果协议类型是其他任何一种,Snort检测IP头部来确定协议类型。
3.1.3 协议
在Snort规则中,有两个地址部分,用来检测包的来源和目的地址。地址可以是一个主机地址或者网络地址。你可以用关键字any来制定所有的地址。地址后面用斜线来附加一个数字,表示掩码的位数。比如:192.168.2.0/24 代表一个C类网络192.168.2.0,其子网掩码是255.255.255.0。
你也可以在Snort规则额胡总制定一个地址的列表,比如:你在网络中包含连个C类地址:192.168.2.0和192.168.8.0,你想对除了这两个网络之外的其他地址应用规则,你可以用下面的规则,其中连个地址用逗号分隔:
alert icmp ![192.168.2.0/24,192.168.8.0/24] any -> any any (msg: "Ping with TTL=1--"; ttl:100;)
注意:方括号与否定器一起用的,如果没有否定符号,你可以不用方括号。(2.9版本待确认)
3.1.4 端口
端口号用来在进出特定的某个或一些列端口的包上运行规则,例如,你可以用源端口23来对来自Telnet服务器的包应用规则。你可以用关键字any来对包应用规则,而不管它的端口号。端口号仅仅对TCP、UDP协议有意义,如果你选择的协议是ICMP、IP,端口号就不起作用。
3.1.4.1 端口范围
你可以在规则中的端口段设置一些列的端口,而不是一个。用冒号分隔起始和结束。例如下面的规则将对来自1024-2048的所有UDP包告警:
alert udp any 1024:2048 -> any any (msg: "UDP ports";)
3.1.4.2 上限和下限
你可以仅仅用一个起始端口号或结束端口号来表示端口列表,例如::1024表示比1024小,包含1024的所有端口,1000: 表示比1000大,包括1000的所有端口
3.1.4.3 否定符
与地址段相同,你也可以在Snort规则中的端口段中用否定符合来排除一个或多个端口。下面的规则将记录除了53端口外的其他所有UDP通信。
log udp any !53 -> any any(msg:"Log UDP";)
但是你不能用逗号来分隔过个端口,如 53,54 这样的表示是不允许的,但是你可以用 53:54 来表示一个端口范围。(2.9版本待确认)
3.1.4.4 共用端口号
共用端口号是提供给一些公用应用的。在UNIX平台上,你可以查看/etc/services文件,可以看到更多的端口的定义。RFC1700中包含详细列表。目前ICANN负责管理这些端口号,可以在 ICANN.ORG中获取信息。
3.1.4 方向段
在Snort规则中,方向段确定源和目的,下面是方向段的相关规定:
- "->"表示左边的地址和端口是源而右边是目的
- "<-"表示右边第地址和端口是源而左边是目的在
- "<>"表示规则奖杯应用在两个方向上,在你想同时监视服务器和客户端的时候,可以用到这个标示。
以下部分学习自CSDN: https://blog.csdn.net/weixin_44813582/article/details/105918523
3.2 规则选项
Snort规则选项部分在头部后面,在一对圆括号里面,其中可能包含一个选项,也可能包含用分号分割的过个选项,这些选项的关系是逻辑与的关系,只有当选项中的条件都满足的时候,规则动作才会被执行。所有snort规则选项之间用分号隔开,每个规则选项也被用冒号分为选项关键字和选项值。
四类主要的规则选项类:
- 一般 提供信息但在检测过程中不产生任何影响
- 有效负载 在净荷中查找数据,并且能过相互关联(数据包数据部分)
- 非有效负载 查找非净荷中的数据(数据包首部)
- 过后检测选项 这些选项时某条规则被处罚后,所设置的执行的规则
3.2.1 general rule options
3.2.1.1 msg
msg规则选项向日志和警报引擎告知要打印的消息以及数据包转储或警报,他是一个简单的文本字符串,利用\作为转义字符来表示离散的字符,否则这些字符可能会使Snort的规则解析器感到困惑(例如分号; 字符)。
msg:"<message text>";
3.2.1.2 reference
提供包含外部的一些攻击识别系统的引用功能,该插件目前支持几种特定的系统以及唯一URL。输出插件将使用此插件来听有关生成的警报的其他信息的链接。
确保还查看<http://www.snort.org/pub-bin/sigs-search.cgi/>,以获取基于sid索引警报描述的系统。
格式:
reference:<id system>, <id>; [reference:<id system>, <id>;]
示例:
alert tcp any any -> any 21 (msg:"IDS287/ftp-wuftp260-venglin-linux";
flags:AP; content:"|00 00 00 01 02|";
reference:arachnids, IDS287; reference:bugtraq,1387;
reference:cve,CAN-2000-1574;)
3.2.1.3 gid
用于标识当规则被触发时,是snort的哪一部分生成事件,例如gid 1和规则子系统有关,大于100的gid被实际来表示特定的预处理器和解码器。有关正在使用的当前生成器ID,请参见源代码树中的etc/generators。请注意,gid关键字是可选项,如未指定,默认为1,为避免与snort已定义的gid冲突,建议从1000000开始,一般规则编写,不建议使用。gid需要和sid配合使用。文件etc/gen-msg.map包含有关预处理器和解码器gid的更多信息,示例:
alert tcp any any -> any 80 (content:"BOB"; gid:1000001; sid:1; rev:1;)
查看/usr/local/share/doc/snort/generators文件(此文件不是配置文件):
rules_subsystem 1 # Snort Rule Engine
rpc_decode 106 # RPC Preprocessor(预处理器)
stream4 111 # Stream4 preprocessor(预处理器)
ftp 125 # FTP decoder(解码器)
3.2.1.3 sid
识别不同的snort规则(snort规则编号),用于唯一标识一条规则,应与rev关键字配合使用,文件sig-msg.map包含警报消息到Snort规则id的映射。在对警报进行处理后以将ID映射到警报消息时,此信息非常有用。
sid:<snort rule id>;
3.2.1.4 rev
标识snort规则的修订,与sid配合使用(说明规则的版本)
alert tcp any any -> any 80 (content:"BOB"; sid:1000003; rev:2;)
3.2.1.5 classtype
snort根据其默认的规则文件,将攻击进行相应分类,并具有不同的优先级,1-4,1最高,规则分类被定义在classification.config文件中。(优先级1(高)是最严重的,优先级4(非常低)是最不严重的。)
classtype: <class name>;
classifacation.config文件,该文件的每一行都遵循下面的语法:
config classification: name,description,priority
name表示类别名称,在snort规则中用classtype关键字来指定
description是对类别的简单描述
priority是这个类别的默认优先级,用数字表示,并可以在snort选项中用关键字priority改变。
示例:
config classification: DoS,Denial of Service Attack,2
| 类型 | 描述 | 优先 |
|---|---|---|
| attempted-admin | 尝试获取管理员特权 | 高 |
| attempted | 尝试获取用户特权 | 高 |
| inappropriate-content | 检测到不适当内容 | 高 |
| policy-violation | 潜在的违反公司隐私的行为 | 高 |
| shellcode-detect | 检测到可执行代码 | 高 |
| successful-admin | 管理员特权获取成功 | 高 |
| successful-user | 用户特权获取成功 | 高 |
| trojan-activity | 检测到网络木马 | 高 |
| unsuccessful-user | 用户权限获取失败 | 高 |
| web-application-attack | Web应用攻击 | 高 |
| attemptd-dos | 试图拒绝服务 | 中 |
| attempted-recon | 企图泄漏 | 中 |
| bad-unknown | 潜在的不良流量 | 中 |
| default-login-attempt | 尝试使用默认的用户名和密码登录 | 中 |
| denial-of-service | 尝试拒绝服务攻击 | 中 |
| misc-attack | 杂项攻击 | 中 |
| non-standard-protocol | 检测非标准协议或事件 | 中 |
| rpc-portmap-decode | 解码RPC查询 | 中 |
| successful-dos | 拒绝服务 | 中 |
| successful-recon-largescale | 大规模信息泄漏 | 中 |
| successful-recon-limited | 信息泄漏 | 中 |
| suspicious-filename-detect | 检测到可疑文件名 | 中 |
| suspicious-login | 检测到使用可疑用户名的尝试登录 | 中 |
| system-call-detect | 检测到系统调用 | 中 |
| unusual-client-port-connection | 客户端正在使用异常端口 | 中 |
| web-application-activity | 访问潜在的易受攻击的Web应用程序 | 中 |
| icmp-event | 常规ICMP事件 | 低 |
| misc-activity | 杂项活动 | 低 |
| network-scan | 检测网络扫描 | 低 |
| not-suspicious | 不可以流量 | 低 |
| protocol-command-decode | 通用协议命令解码 | 低 |
| string-detect | 检测到可疑字符串 | 低 |
| unknown | 未知流量 | 低 |
| tcp-connection | 检测到TCP连接 | 非常低 |
3.2.1.6 priority
配置规则优先级(可以覆盖规则类型classtype预置的优先级)
priority:<priority interger>;
3.2.1.7 metadata
表明规则的一些其他信息,例如是否在规则共享库中共享,及其gid和sid,以及基于什么目标的服务标识,采用键值对形式,键值之间空格分开,多个键值对,逗号隔开,次关键字只有在Host Attribute Table已经提供才有意义。
metdata:key1 value1;
metdata:key1 value1,key2 value2;
| 键 | 描述 | 值格式 |
|---|---|---|
| engine | 指共享库规则 | "shared" |
| sodi | 共享库规则生成器和SID | gid/sid |
| service | 基于目标的服务标识符 | "http" |
alert tcp any any -> any 80 (msg:"Shared Library Rule Example";
metadata:engine shared; metadata:soid 3|12345;)
alert tcp any any -> any 80 (msg:"Shared Library Rule Example";
metadata:engin shared, soid 3|12345;)
alert tcp any any -> any 80 (msg:"Shared Library Rule Example";
metadata:service http;)
3.2.2 payload detection rule options
3.2.2.1 content
查找匹配净荷中的内容,并触发响应,选项数据可以包含混合文本和二进制数据,二进制数据放在两个管道符号"||"之间,表示为字节码,需要通过十六进制的方式进行表示,若果规则前面有!,则将在不包含此内容的数据包上触发警报。当编写规则以警告不符合特定模式的数据包时,这很有用,格式:
content:[!]"<content string>";
alert tcp any any -> any 139 (content:"|5c 00|p|00|I|00|P|00|E|00 5c|";)
alcet tcp any any -> any 80 (content:!"GET";)
此外,content还有很多修饰符:
Nocase content字符串大小写不敏感,即忽略大小写
rawbytes 直接匹配原始数据包,忽视预处理器解码。如果未设置该关键字,大部分预处理器会使用解码规范化数据做content匹配
Depth 匹配的深度
Offset 开始匹配的偏移量
Distance 两次content之间匹配的间距,与offset类似,不过,distance设置的是从上一个匹配结束开始的距离,而offset是从开始计算
Within 两次content匹配之间至多的间距(字节)
http_cookie 匹配cookie
http_raw_cookie 匹配未经normalize的cookie
http_header 匹配header
http_raw_header 匹配未经normalize的header
http_method 匹配method
http_uri 匹配uri
http_raw_url 匹配日志未经nomalize的url中
http_stat_code 匹配状态码中匹配
http_stat_msg 匹配状态信息
http_encode 匹配HTTP报文中url,首部,cookie字段使用的特定的编码方式,格式(!和or不能结合使用)
http_encode格式:
http_encode;[uri|header|cookie], [!][<utf8|double_encode|non_ascii|uencode|bare_byte|ascii|iis_encode>]
http_encode示例:
alert tcp any any -> any any (msg:"UTF8/UEncode Encoding present"; http_encode:uri,utf8|uencode;)
alert tcp any any -> any any (msg:"No UTF8"; http_encode:uri,!utf8);
注意:http开头的修饰符需要配合前面介绍过的预处理器http_inspect一起使用
3.2.2.2 protected_content
提供content的大部分功能,不同的是输入的查询内容形式上不同,上传查询内容的安全哈希摘要进行查询,隐藏查询内容更具保护性,如在配置文件中未指定默认的哈希算法,则在规则中要指定(md5,sha25,sha512),还需要指定length关键字,标识原始数据长度,格式。
protected_content:[!]"<content hash>", length:orig_len[, hash:md5|sha256|sha512]
示例:
alert tcp any any <> any 80 (msg:"MD5 Alert"; protected_content:"293C9EA246FF9985DC6F62A650F78986"; hash:md5; offset:0; length:4;)
- hash 如上例,配合protecte_content,指定使用的哈希算法
- length 配合protect_content关键字使用,已受保护的形式标识规则摘要的内容的原始数据长度,范围 0 - 65535
3.2.2.4 nocase
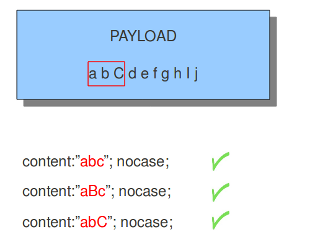
使用nocase关键字,规则编写者可以指定Snort应该查找特定的模式,而忽略大小写。nocase修改规则中的上一个content关键字,格式:
nocase;
示例:
alert tcp any any -> any 21 (msg:"FTP ROOT"; content:"USER root"; nocase;)
图解:
content:"abc"; cocase;
3.2.2.5 rawbytes
rawbytes关键字允许规则查看原始数据包数据,而忽略预处理器进行的任何解码。这充当了上一个content选项的修饰符。
HTTP Inspect具有一组使用原始数据的关键字,例如:
http_raw_cookie、http_raw_header、http_raw_uri等,它们与原始HTTP请求和响应的特定部分匹配。
如果未显式指定rawbytes,则默认情况下,大多数其他预处理都会使用解码/规范化的数据进行内容匹配。因此,应中rawbytes以检查数据包中的任意原始数据,格式;
rawbytes;
示例:
此示例告诉内容模式匹配查看原始流量,而不是Telnet解码器提供的解码流量。
alert tcp any any -> any 21 (msg:"Telnet NOP"; content:"|FF F1|"; rawbytes;)
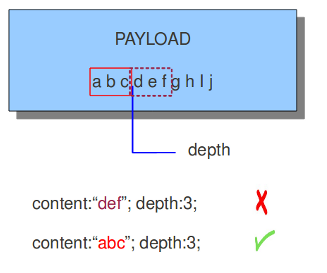
3.2.2.6 depth
depth关键字允许规则编写者指定Snort应该在包中搜索指定模式的距离。depth修改了规则中先前的"content"关键字。
深度为5会使Snort仅在payload的前5个字节内查找指定的模式。
由于depth关键字是以前的content关键字的修饰符,因此在指定depth之前,规则中必须由内容。
此关键字允许值大于或等于要搜索的模式长度,最小允许值为1,此关键字的最大允许值为65535。
该值也可以设置为引用同一规则中由byte_extract关键字提取的变量的字符串值。
格式:
depth:[<number><var_name>];
图解:
content:"abc"; depth:3;
3.2.2.7 offset
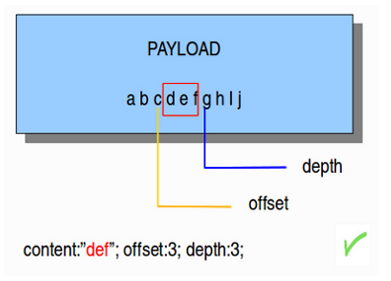
offset关键字允许规则编写器指定从何处开始搜索数据包中的模式。offset修改规则中的上一个"content"关键字。
偏移量5会告诉Snort咋payload的前5个字节之后开始寻找指定的模式。
由于offset关键字是以前的content关键字的修饰符,因此指定offset之前,规则中必须有内容。
辞官集资允许输入-65535到65535之间的值。
该值也可以设置为引用同一规则中由byte_extract关键字提取出来的变量的字符串值。
格式:
offset:[<number>|<var_number>];
图解:
content:"def"; offset:3;

综合示例:
alert tcp any any -> any 80 (content:"def"; offset:3; depth:3;)
3.2.2.8 distance
distance关键字使规则编写者可以指定Snort在开始搜索相对于先前模式匹配末尾的指定模式之间应忽略的包数。
可以认为这与offset完全一样,只是它与最后一个模式匹配的末尾有关,而不是与数据包的开头有关。
此关键字允许输入-65535到65535之间的值。
该值也可以设置为引用同一规则中由byte_extract关键字提取的变量的字符串值。
格式:
distance:[<byte_count>|<var_name>];
示例:
以下规则映射到/ ABC.{1,}DEF /的正则表达式。
alert tcp any any -> any any (content:"ABC"; content:"DEF"; distance:1;)
图解:
content:"abc"; content:"def"; distance:0;
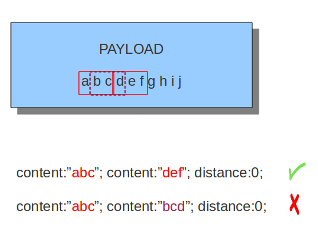
不仅如此,有时不同的distance值结果可能相同,比如下面这个例子,无论是在"abc"之后偏移0还是4或是中间的任意一个整数,都能匹配到后面的"def",因为distance并没有对后面的匹配长度做任何限制:
content:"abc"; content:"def"; distance:0;
content:"abc"; content:"def"; distance:4;
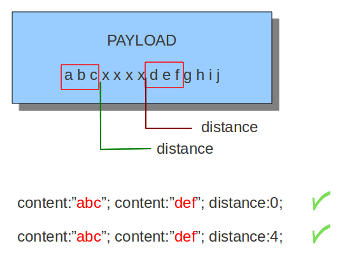
除此之外,distance由于是相对于上一次的匹配结果的位置偏移,所以它的值可以是负数:
content:"abc"; content:"bcd"; distance:-2;

3.2.2.9 within
within也是一个修饰content的关键字,他表示从上一个content匹配位置之后的指定字节内对当前的content进行匹配,within的值不能为0,最大值为65535。
该值也可以设置为引用同一规则中由byte_extract关键字提取的变量的字符串值。
格式:
within: [<byte_count>|<var_name>];
例子:
在匹配到"ABC"结尾后的十个字节内搜索匹配"EFG"
alert tcp any any -> any any (content:"ABC"; content:"EFG"; within:10;)
图解:
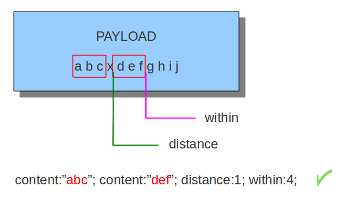
content:"abc"; content:"def"; within:3;

同样,within也可以和distance一起使用。
content:"abc"; content:"def"; distance:1; within:4;
3.2.2.10 http_client_body
http_client_body关键字是一个内容修饰符,用于将搜索限制为HTTP客户端请求的正文。
由于此关键字是先前content关键字的修饰符,因此在指定"http_client_body"之前,规则中必须有内容。使用此选项检查的数据量取决于HttpInspect的post_depthconfig选项。当post_depth设置为-1时,与此关键字匹配的模式将不起作用。
格式:
http_client_body;
示例:
此规则将对模式"EFG"的搜索限制为HTTP客户端请求的原始正文。
alert tcp any any -> any 80 (content:"ABC"; content:"EFG"; http_client_body;)
注意:不允许将 http_client_body 修饰符与 rawbytes 修饰符用于同一内容;
3.2.2.11 fast_pattern
snort对只有一个content关键字的规则使用多模匹配,而对于过个content的规则就对最长对最法则的一个进行多模匹配,而fast_pattern则可以改变这个状况,如果在较简单的content字段后加上fast_pattern关键字则会优先匹配这个content,有时这种方法可以有效提升效率。
此规则使内容"IJKLMNO"采取快速模式匹配,即使它比气啊年的模式"ABCDEFGH"段。
alert tcp any any -> any 80 (content:"ABCDEFGH"; content:"IJKLMNO"; fast_pattern;)
不仅如此,fast_pattern还支持部分content多模匹配,比如下面这个例子,表示从content的第一字节'开始之后'的五字节进行多模匹配,即匹配"JKLMN",但仍用content规则选项检测为"IJKLMNO":
alert tcp any any -> any 80 (content:"ABCDEFGH"; content:"IJKLMNO"; fast_pattern:1,5;);
only关键字,表示不会将该content加入到规则构建树中,此条规则中,将内容"IJLKMNO"采用快速模式匹配,并且内容应仅应用于快速模式匹配,并不作为content规则选项检测。
alert tcp any any -> any 80 (content:"ABCDEFGH"; content:"IJKLMNO"; nocase; fast_pattern:only;)
3.2.2.12 uricontent
相当于http_uri修改的content关键字,在标准化的请求url中查找
3.2.2.13 urilen
指定要匹配的url的长度,包括最大长度,最小长度,或者长度范围,使用norm|raw表示使用的是原始缓冲区还是规范化的url缓冲区,格式:
urilen:min<>max[,<uribuf>];
urilen:[<|>]<number>[,<uribuf>];
<uribuf> : "norm" | "raw"
3.2.2.14 isdataat
判断指定位置是否有数据,可选相对于之前的content匹配结束,格式
isdataat: [!]<int>[, relative|rawbytes];
3.2.2.15 pcre
pcre关键字允许使用兼容perl的正则表达式编写规则,正则的细节查阅snort_manual
格式:
pcre:[!]"(/<regex>/|m<delim><regex><delim>)[ismxAEGRUBPHMCOIDKY]
示例:
alert tcp any any -> any 80 (content:“/foo.php?id="; pcre:"/\/foo.php?id=[0-9]{1,10}/iU";)
3.2.2.16 pkt_data
对于原始的传输载荷设置检测指针,任何相对或是绝对的content匹配和其他净载荷检测规则选项,如果设置pkt_data,将应用用于原始的TCP/UDP载荷或者标准化的缓存(如果是telent,规范化的smtp)
3.2.2.17 file_data
将检测的指针指向下一缓冲区:1、如果是HTTP流量,a.HTTP响应正文(不分开/预缩/规范化),b.解分块的HTTP响应正文,c.解压缩的HTTP响应正文,d.规范化HTTP响应正文。2、如果是SMTP/POP/IMAP流量时, 将缓冲区设置到a.SMTP/POP/IMAP数据正文(关闭解码时包括Email首部和MIME)b.base64解码的MIME附件。c.非编码的MIME附件,d.可引用,可打印解码的MIME附件,e.Unix到Unix的解码附件。3、如果不是由1和2设置,将被设置到净荷。
3.2.2.18 base64_decode
用于base64解码数据,对于http首部,次选项特别有用, 例如Http权限首部,格式:
base64_decode [:[bytes <bytes_to_deocde>][, ][offset <offset>[, relative]];
其中可选bytes后面设置要解码的字节数,offset后面设置相对起始点或者相对于doe_ptr的偏移量,relative,设定检测相对doe_ptr。
示例:
alert tcp any any -> any any (msg: "Authorization NTLM"; \
content:"Authorization:"; http_header; \
base64_decode:bytes 12, offset 6, relative; base64_data; \
content:"NTLMSS;"within:8;)
3.2.2.19 base64_data
用于将指针置于base64解码缓冲区的开头,base64_decode需要将base64_data选项前指定
3.2.2.20 byte_test
该选项检测一段二进制字节是否为特定值,能够测试二进制自定或者转换代表字节串为等效二进制而检测,格式:
byte_test: <bytes to convert>, [!]<operator>, <value>, <offset> \
[, relative][, <endian>][, string, <number type>][, dce] \
[, bitmask <bitmask_value>];
bytes = 1 - 10, 检测的字节数
operator = '<' | '=' | '>' | '<=' | '>=' | '&' | '^',与设定值的关系
value = 0 - 4294967295,设定值
offset = -65535 to 65535 偏移量
relative 相对上一个
endian 小端存储,little,大端存储,big
number type 进制,hex 十六进制,dec 十进制,oct 八进制
bitmask_value = 1 to 4 byte hexadecimal value,字节掩码
3.2.2.21 bytes_jump
该关键字用于跳过指定的字节长度,以在特定位置执行检测,格式
byte_jump: <bytes_to_convert>, <offset> [, relative][, multiplier <mult_value>] \
[, <endian>][, string, <number_type>][, align][, from_beginning][, from_end] \
[, post_offset <adjustment value>][, dce][, bitmask <bitmask_value>];
bytes = 1 - 10,同上
offset = -65535 to 65535
mult_value = 0 - 65535,将计算字节乘上value,并跳过该值的字节数
post_offset = -65535 to 65535,在其他跳跃之后再次向前或者向后进行跳跃value字节
from_beginning/from_end,从数据包载荷的开始而不是当前位置跳跃/从尾部开始进行跳跃
bitmask_value = 1 to 4 bytes hesadecimal value
3.2.2.22 byte_extract
该规则从数据包载荷中截取一定数量的字节,存为变量,以供后面选项使用,每个规则最多只能创建两个byte_extract变量。它们可以在同一规则中重复使用任何次数。格式:
byte_extract: <bytes_to_extract>, <offset>, <name> [, relative] \
[, multiplier <multiplier value>][, <endian>][, string][, hex][, doc][, oct]
[, align <align value>][, dce][, bitmask <bitmask>];
- bytes_to_extract = 1 - 10
- name 保存的变量名
- value = 0 - 4294967295
- offset = -65535 to 65535
- bitmask_value = 1 to 4 byte hexadecimal value
示例:
- 在偏移量0处从字节读取字符串的偏移量
- 在偏移量1处从紫儿姐读取字符串的深度
- 使用这些值将模式匹配约束到较小的区域
alert tcp any any -> any any (byte_extract:1, 0, str_offset; \
byte_extract:1, 1, str_depth; \
content:"bad stuff"; offset:str_offset; depth:str_depth; \
msg:"Bad Stuff detected within field";)
alert tcp any any -> any any (content:"|04 63 34 35|"; offset:4; depth:4; \
byte_extract:2, 0, vat_match, relative, bitmask 0x03ff; \
byte_test:2, =, var_match, 2, relative; \
msg:"Byte test value matches bitmask applied on bytes extracted";)
3.2.2.23 byte_math
对提取和指定值或现有变量执行数学运算,将结果存在新的结果变量中,宫格后面选项使用,格式:
byte_math:bytes <bytes_to_extract>, offset <offset_value>, oper <operator>,
ravalue <r_value>, result <result_variable> [, relative]
[, endian <endian>][, string <number type>][, dce]
[, bitmask <bitmask value>];
- bytes_to_extract = 1 - 10
- operator = '+' | '-' | '*' | '/' | '<<' | '>>'
- r_value = 0 - 4294967295 | byte extract variable
- offset_value = -65535 to 65535
- bitmask_value = 1 to 4 byte hexadecimal value
- result_variable = Result Variable name
3.2.2.24 ftpbounce
检测FTP bounce attacks,格式:ftpbounce;
3.2.2.25 asn1
ASN.1检测插件解码数据包或者数据包的一部分,查找恶意代码,多个asn1选项之间是or的关系,命中其中一个,整个选项命中,格式:
asn1:[bitstring_overflow][, double_overflow][, oversize_length <value>][, absolute_offset <value>|relative_offset <value>];
3.2.2.26 cvs
CVS检测插件有助于检测:Bugtraq-10384,CVE-2004-0396:"变形条目修改和未改变标志插入",格式:
cvs:<option>; option:invalid-entry,查找无效的条目字符串
3.2.3 non-payload detection rule options
3.2.3.1 fragoffset
比较IP首部的片偏移值是否满足和设定的值是否满足关系,格式:
fragoffset:[!|<|>]<number>;
3.2.3.2 ttl
检测IP首部的8位生存时间字段,格式:
ttl:[<, >, =, <=, >=]<number>
ttl:[<number>]-[<number>];
3.2.3.3 tos
检测IP首部的TOS字段(8位TOS包括3位现已被忽略的优先权子字段,1位必须置零的未用位,另外4为分别表示:最小时延、最大吞吐量、最高可靠性和最小费用,4为均为0代表一般服务),格式:
tos:[!]<number>;
3.2.3.4 id
检测IP首部的id字段(16位标识),格式:
id:<number>;
3.2.3.5 ipopts
用来查找IP首部的选项字段,是否设置了一些特定的IP选项,需要注意的是每个规则只能设置一个ipopts关键字
- rr Record route(记录路由)
- eol End of list(列表结尾)
- nop No op(无操作)
- ts Time Stamp(时间戳)
- sec IP security(IP安全选项)
- esec IP Extended Security
- lsrr Loose source routing(松散源路由)
- ssrr Strict source routing(严格源路由)
- satid Stream identifier(流标示符)
- any Any IP options are set
格式:
ipopts:<rr|eol|nop|ts|sec|esec|lsrr|lsrre|ssrr|satid|any>;
3.2.3.6 fragbits
检测IP首部的3位和分片有关的标志位,M-更多分片(除最后一篇均置1),D-不分片,R-保留位,snort提供了一些修改匹配条件的修饰符:"+"代表匹配设定值及其他任意值,"*"代表匹配任意设定值(or),"~"非。格式:
fragbits:[+*!]<[MDR]>;
示例:
fragbits:MD+;
3.2.3.7 dsize
用来检测数据包载荷大小,可用于检查可能导致缓冲区溢出的异常大小的数据包。格式:
dsize:min<>max
dsize:[<|>]<number>;
3.2.3.8 flags
检查是否存在特定的TCP标志位,可以添加的修饰符同样有"+""*""!",可以检查以下位:
- F FIN
- S SYN
- R RST
- P PSH
- A ACK
- U URG
- C CWR
- E ECE
- 0 No TCP Flags Set
格式:
flags:[!|*|+]<FSRPAUCE0>[, <FSRPAUCE>];
3.2.3.9 flow
flow关键字与session tracking结合使用,它允许规则值应用于特定方向的数据流,允许规则只应用与客户端或者服务端,选项值有:
- to_client 服务器响应从A到B时触发
- to_server 客户端请求从A到B时触发
- from_client 客户端请求从A到B时触发
- from_server 服务器响应从A到B时触发
- established 只触发已经建立的TCP连接
- stateless 不管流处理器的状态都触发
- no_stream 不在重组的流数据包上触发(对dsize和stream5有用)
- only_stream 只在重组的流数据上触发
- no_frag 不在重组的片数据包触发
- only_frag 只在重组的片数据包触发
格式:
flow:[(established|not_established|stateless)]
[,(to_client|to_server|from_client|from_server)]
[,(no_stream|only_stream)]
[,(no_frag|only_frag)];
3.2.3.10 seq
检测TCP首部的32位序号字段
格式:
seq:<number>;
3.2.3.11 ack
检测TCP首部的32位确认序号字段
格式:
ack:<number>;
3.2.3.12 window
检测TCP首部的16位窗口大小字段(接收端期望接收的字节大小)
3.2.3.13 itype
检测ICMP首部的8位类型字段
格式:
itype:min<>max
itype:[<|>]<number>;
3.2.3.14 icode
检测ICMP首部的8位代码字段,不同的类型和字段代表,代表不同的ICMP类型的报文,格式:
icode:min<>max;
icode:[<|>]<number>;
3.2.3.15 id
检测ICMP首部的id(标识符字段,并不是所有ICMP报文都有),格式:
icmp_id:<number>;
3.2.3.16 seq
检测ICMP首部的序列号字段(部分ICMP报文有),格式:
icmp_seq:<number>;
3.2.3.17 rpc
用于检查SUNRPC CALL请求中的PRC应用程序,版本号,程序编号,通配符"*"对版本和程序标号都有效,格式:
rpc:<application number>, [<version number>|*], [<procedure number>|*];
3.2.3.18 ip_proto
检查IP的协议头,格式:
ip_proto:[!|>|<] <name or number>;
3.2.3.19 sameip
检查源IP和目的IP是否一致,示例:
alert ip any any -> any any (sameip;)
3.2.3.20 stream_reassemble
对TCP流重组进行设置,允许规则在匹配流量时,启用或者禁用流重组,格式:
stream_reassemble:<enable|disable>, <server|client|both>[, noalert][, fastpath]
其中noalert,设定不报警,fastpath参数使snort忽略连接的其他部分
3.2.3.21 stream_size
匹配指定长度的TCP流,格式:
stream_size:<server|client|both|either>, <operator>, <number>;
3.2.4 post-detection rule options
3.2.4.1 logto
将触发规则的数据包记录到指定的输出日志文件,snort处于二进制日志记录模式时,次选项不起作用,格式:
logto:"filename";
3.2.4.2 session
用于从TCP会话中提取用户数据,在很多情况下,查看用户在telnet,ftp或者web会话找那个嵌入什么是很有用的,有三个可选关键字(printable、binary、all)printable关键字只打印能够被用户正常看到和打印的数据,bindary关键字打印二进制数据,all关键字以等效的十六进制打印不可打印字符,格式:
session:[printable|bindary|all];
示例:
记录telnet保重所有可打印字符串。
log tcp any any <> any 23 (session:printable;)
给定端口12345上的FTP数据会话,本示例以为禁止形式记录有效负载字节。
log tcp any any <> any 12345 (metadata:service ftp-data; session:binary;)
警告:
使用sesion管家在你可能会大大降低Snort的速度,因此不应该在高负载情况下使用它。session关键字最适合处理二进制(pcap)日志文件
关键字"bindary"不会记录任何应用层以下的协议头,当记录重新组装的包时,流重新组装将导致重复数。
3.2.4.3 resp
启动结束违规会话的主动响应,该响应可以消除干扰会话,可在被动和内联模式使用,在向目标主机发送多种响应数据包时,这些选项组合使用,多个参数之间使用逗号分隔。该插件合法的参数如下:
- rst_snd 向发送方发送TCP-RST数据包
- rst_rcv 向接受方发送TCP-RST数据包
- rst_all 向收发双方发送TCP_RST数据包
- icmp_net 向发送方发送ICMP_NET_UNREACH
- icmp_host 向发送方发送ICMP_HOST_UNREACH
- icmp_port 向发送方发送ICMP_PORT_UNREACH
- icmp_all 向发送方发送上述所有的ICMP数据包
3.2.4.4 react
支持主动响应,其中包括向客户端发送网页或其他内容,然后关闭连接。用于被动和内联模式,react和resp都有可能使snort陷入死循环,要注意使用。
这个选项包括如下的基本修饰词:
- block 关闭连接并且发送一个通知
- warm 发送明显的警告信息
基本修饰词可以和如下的附加修饰词组合使用,大量的附加修饰词由逗号隔开,react关键字将被放在选项的最后一项:
- msg 把msg选项的内容包含进阻塞通知信息中
- proxy 使用代理端口发送通知信息
示例:
alert tcp any any <> 192.168.1.0/24 80 (content:"bad.html"; msg:"Not for Children!"; react:block,msg;)
3.2.4.5 tag
tag关键字允许规则记录多个触发规则的数据包,一旦一个规则被触发,涉及源和/或目标主机的额外流量将被标记。记录标记的流量,以允许分析响应代码和攻击后流量。带标记的警报将被发送到与原始警报相同的输出插件,但是正确处理这些特殊警报是输出插件的责任,格式:
tag:host, <count>, <metric>, <direction>;
tag:session[, <count>, <metric>][, exclusive];
- host 记录从激活标记的主机来的数据包
- session 记录触发这条规则的会话的数据包
- count 记录数量,和metric单位配合
- metric
- packets 为主机/会话标记<count>数据包
- seconds 为主机/会话标记<count>秒
- bytes 为主机/会话标记<count>字节
- direction
- src 标记包,其中包含生成初始事件的包的源IP地址,仅host类型时可用
- dst 标记包,包含产生初始事件的包的目的IP地址,仅host类型可用
- exclusive 仅在第一个匹配会话中标记数据包,session类型可用,具有此选项的session类型tag不需要计数和单位参数,而用于获取完整会话
注意:
1、后续的警报和事件过滤器都不会阻止标记包被记录。随后的标记警报将导致限制重置。
alert tcp any any <> 10.1.1.1 any
(flowbits:isnotset,tagged;content:"foorbar";nocase;
flowbits:set,tagged;tag:host,600,seconds,src;)
2、如果在使用"数据包"以外的度量的规则中有标记选项,那么将使用tagged_packet_limit来限制已标记的数据包的数量,而不管是否达到了秒或字节计数。默认的tagged_packet_limit值为256,可以通过使用snort.conf文件中的config选线修改tagged_packet_limit配置选项。您可以禁用则包限制为特定规则通过添加一个"包"度量你的标签选项,其计数设置为0(可以在全球范围通过数字tagged_packet_limit在snort.conf中选择0)。这样做将确保数据包标记的全额秒或字节,不会得切换为tagged_packet_limit。(注意,tagged_packet_limit的引入是为了避免在高带宽传感器上对具有高"秒"或"字节"计数的标记规则使用DOS的情况。)
alert tcp 10.1.1.4 any -> 10.1.1.1 any
(content:"TAGMYPACKETS";tag:host,0,packets,600,seconds,src;)
示例:
该示例记录任何telnet会话的前10秒或"tagged_packet_limit"(无论哪个先出现)
alert tcp any any -> any 23 (flags:S,CE; tag:session,10,seconds;)
需要tag:host至少需要一个计数和度量,但是没有任何度量的tag:session可以用来获得完整的会话,如下所示:
pass tcp any any -> 192.168.1.1 80 (flags:S;tag:session,exclusive;)
3.2.4.6 replace
replace在内联模式下可用,可以用提供的字符串和之前匹配的字符换进行替换,新字符串和要替换的内容必须具有相同的长度,一个规则可以有多个替换,每个内容对应一个,格式:
replace:"<string>";
3.2.4.7 detection_filter
detection_filter定义了一个速率,在规则生成事件之前,源主机或目标主机必须超过这个速率。detection_filter的格式如下:
detection_filter:track <by_src|by_dst>,count <c>, seconds <s>;
- track 跟踪方向,by_src 源防线,by_dst 目的方向
- count 超过检测筛选器限制之前允许的最大规则匹配数(以秒为单位),C必须是非零的。
- seconds 累计计数的时间周期,该值必须是非零的。
Snort在评估所有其他规则选项(与过滤器在规则源中的位置无关)之后,将detection_filter作为检测阶段的最后一步进行评估,每个规则最多运行一个detection_filter。
示例:
在一个60秒的采样周期内,在第一次30次失败的登录尝试之后,该规则将在10.1.2.100开始的每一次失败的登录尝试上触发:
drop tcp 10.1.2.100 any > 10.1.1.100 22 (
msg:"SSH Brute Force Attempt";
flow:established,to_server;
content:"SSH"; nocase; offset:0; depteh:4;
detection_filer:track by_src, count 30, seconds 60;
sid:1000001; rev:1;)
因为可以会生成许多事件,所以detection_filter通常会与event_filter一起使用,以减少记录的事件数量。
