
spark-jobserver安装实践 (centos7.4)
spark-jobserver 提供了一个RESTful接口来提交和管理spark的jobs,jars和job contexts。
该工程位于:https://github.com/spark-jobserver/spark-jobserver
特性:
- 针对job 和 contexts的各个方面提供了REST风格的api接口进行管理
- 支持SparkSQL,Hive,Streaming Contexts/jobs 以及定制job contexts!
- 支持压秒级别低延迟的任务通过长期运行的job contexts
- 可以通过结束context来停止运行的作业(job)
- 分割jar上传步骤以提高job的启动
- 异步和同步的job API,其中同步API对低延时作业非常有效
- 支持Standalone Spark和Mesos
- Job和jar信息通过一个可插拔的DAO接口来持久化
- 命名RDD以缓存,并可以通过该名称获取RDD。这样可以提高作业间RDD的共享和重用
- 支持scala 2.10 和 2.11 和2.12

export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$HOME/bin:$HOME/.local/bin:$PATH
使配置文件生效
source /etc/profile 或 . /etc/profile
验证是否成功
java -version

scala安装:
下载源码包:
wget https://downloads.lightbend.com/scala/2.12.6/scala-2.12.6.tgz
创建安装目录:
mkdir /usr/local/scala
解压:
tar -zxf scala-2.12.6.tgz -C /usr/local/scala/
添加环境变量:vim /etc/profile 在最后添加

export SCALA_HOME=/usr/local/scala/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin
使配置生效:
source /etc/profile 或 . /etc/profile
验证是否成功:
scala -version
![]()
spark安装:
下载安装包:wget https://archive.apache.org/dist/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.6.tgz
创建安装目录:
mkdir /usr/local/spark
解压安装包:
tar -xzvf spark-2.3.1-bin-hadoop2.6.tgz -C /usr/local/spark/
设置环境变量:vim /etc/profile 在最后添加
![]()
export SPARK_HOME=/usr/local/spark/spark-2.3.1-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
使配置生效:
source /etc/profile 或 . /etc/profile
修改配置:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
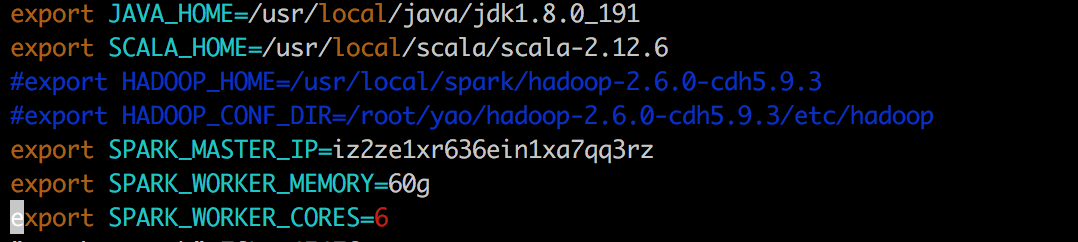
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export SCALA_HOME=/usr/local/scala/scala-2.12.6
#export HADOOP_HOME=/usr/local/spark/hadoop-2.6.0-cdh5.9.3
#export HADOOP_CONF_DIR=/root/yao/hadoop-2.6.0-cdh5.9.3/etc/hadoop
export SPARK_MASTER_IP=iz2ze1xr636ein1xa7qq3rz
export SPARK_WORKER_MEMORY=60g
export SPARK_WORKER_CORES=6
*spark 为单节点
cp slaves.template slaves
启动spark
sh ./sbin/start-all.sh 或者
sh /bin/spark-shell.sh
验证是否成功:
spark-shell
jps查看

浏览器查看
ip:8080
sbt安装:
下载yum源repo:
curl https://bintray.com/sbt/rpm/rpm > /etc/yum.repos.d/bintray-sbt-rpm.repo
安装sbt:
yum install sbt -y
验证安装是否成功:
![]()
spark-jobserver安装:
1)安装mysql 版本不限 当前使用版本为mysql5.6
查看已安装的 Mariadb 数据库版本并卸载:
rpm -qa|grep mariadb|xargs rpm -e --nodeps
下载安装包:
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
安装mysql-community-release-el7-5.noarch.rpm包:
rpm -ivh mysql-community-release-el7-5.noarch.rpm
安装完成之后,会在 /etc/yum.repos.d/ 目录下新增 mysql-community.repo 、mysql-community-source.repo 两个 yum 源文件
安装mysql :
yum install mysql-server
启动msyql:
systemctl start mysqld.service #启动 mysql
systemctl restart mysqld.service #重启 mysql
systemctl stop mysqld.service #停止 mysql
systemctl enable mysqld.service #设置 mysql 开机启动
设置密码:
mysql5.6 安装完成后,它的 root 用户的密码默认是空的,我们需要及时用 mysql 的 root 用户登录(第一次直接回车,不用输入密码),并修改密码。 # mysql -u root
mysql> use mysql;
mysql> update user set password=PASSWORD("这里输入root用户密码") where User='root';
mysql> flush privileges;
创建spark-jobserver数据库
mysql>create database spark_jobserver;
mysql>grant all privileges on *.* to root@'%' identified by '123456';
mysql> flush privileges;
2)安装jobserver
官方文档:https://github.com/spark-jobserver/spark-jobserver
clone jobserver源代码:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/
git clone https://github.com/spark-jobserver/spark-jobserver.git
修改配置:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/job-server/config/cp local.conf.template local.conf
cp local.sh.template local.sh
cp shiro.ini.basic.template shiro.ini
修改local.conf 修改内容如下:
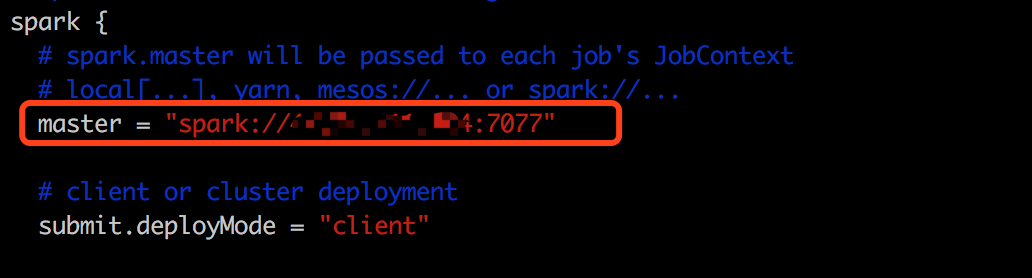
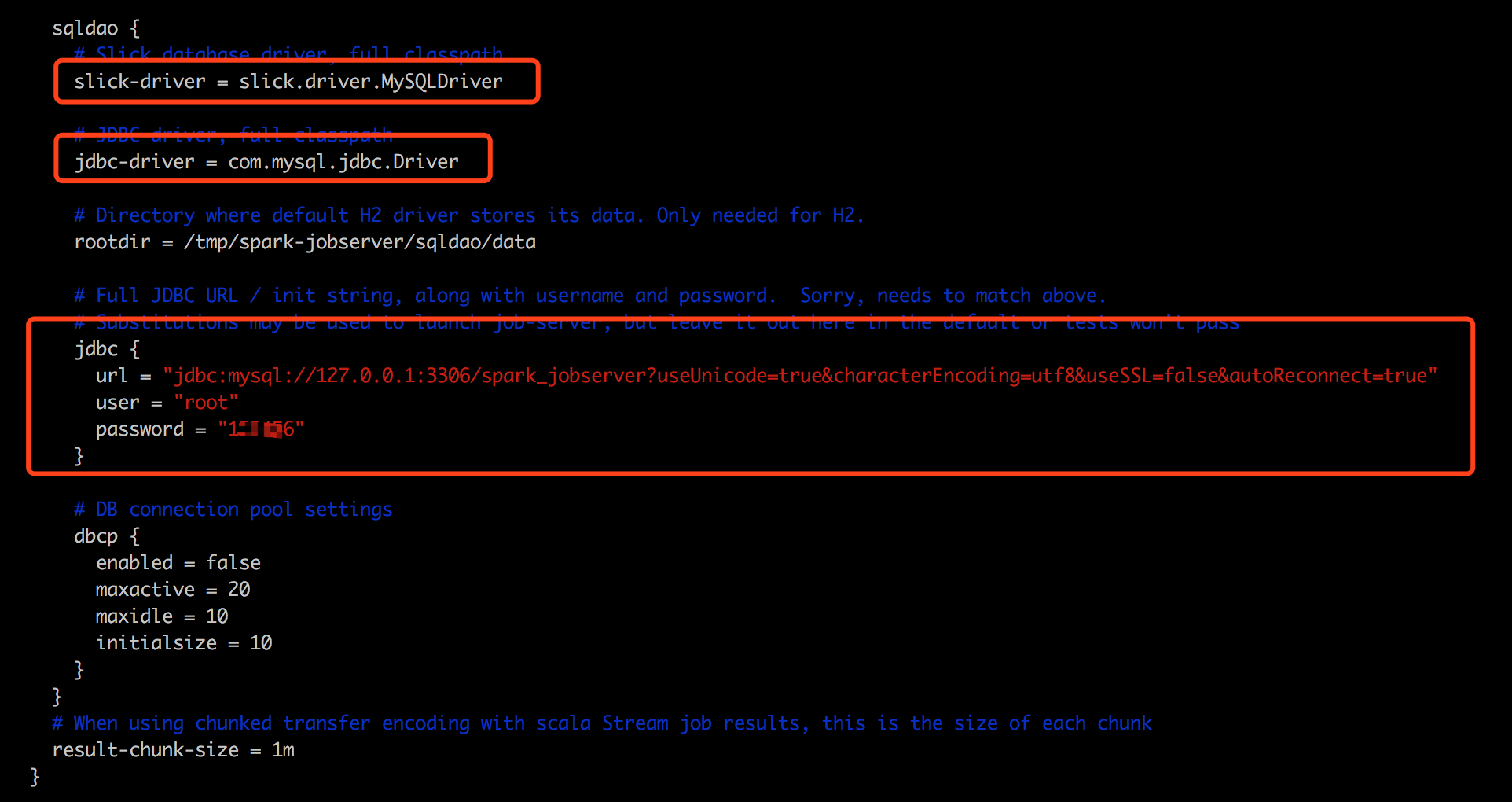

local.sh :修改属性

修改配置文件application.conf:
vim /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/job-server/src/main/resources/application.conf

修改心跳检测超时时间为30s

vim /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/config/local.conf
在结尾添加
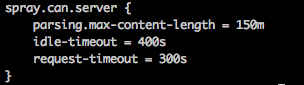
spray.can.server {
parsing.max-content-length = 150m
idle-timeout = 400s
request-timeout = 300s
}
上传jar包大小限制配置,大小自定义
打包配置:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/bin/sh server_deploy.sh local

启动jobserver:
cd ..
sh server_start.sh

验证启动是否成功:

上传jar包时,可能会出现如下问题
1) jar包大小限制问题
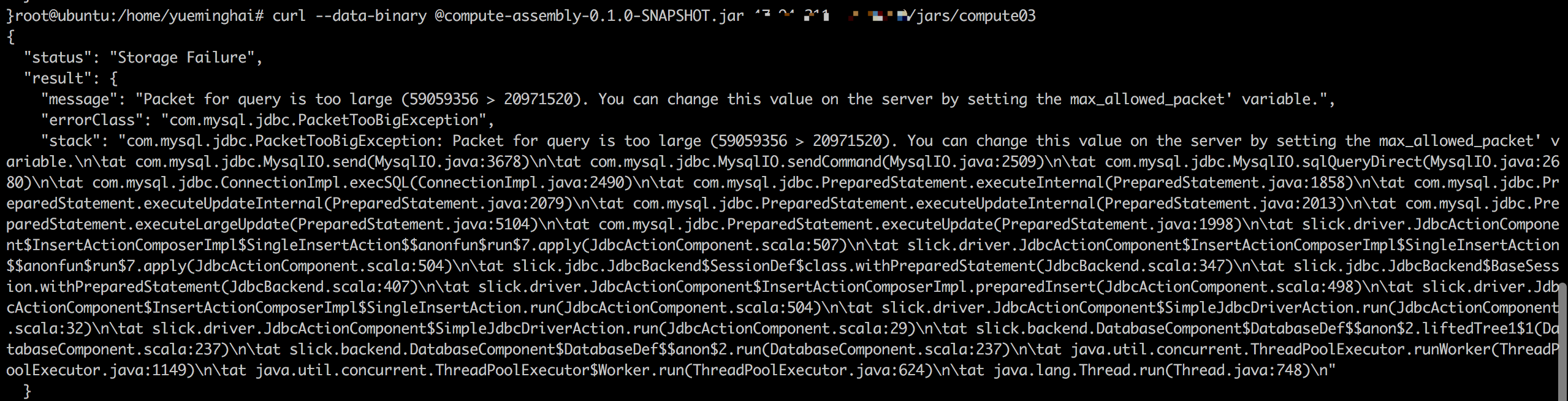
解决方法:vim /etc/my.cnf 添加max_allowed_packet=80M 添加后重启mysql服务
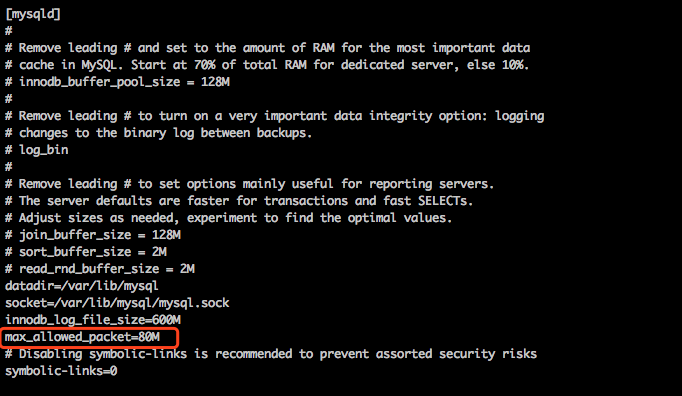
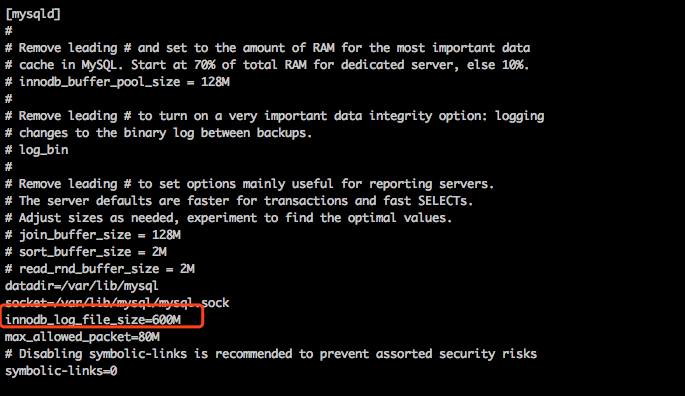
2)innodb_log_file_size大小问题
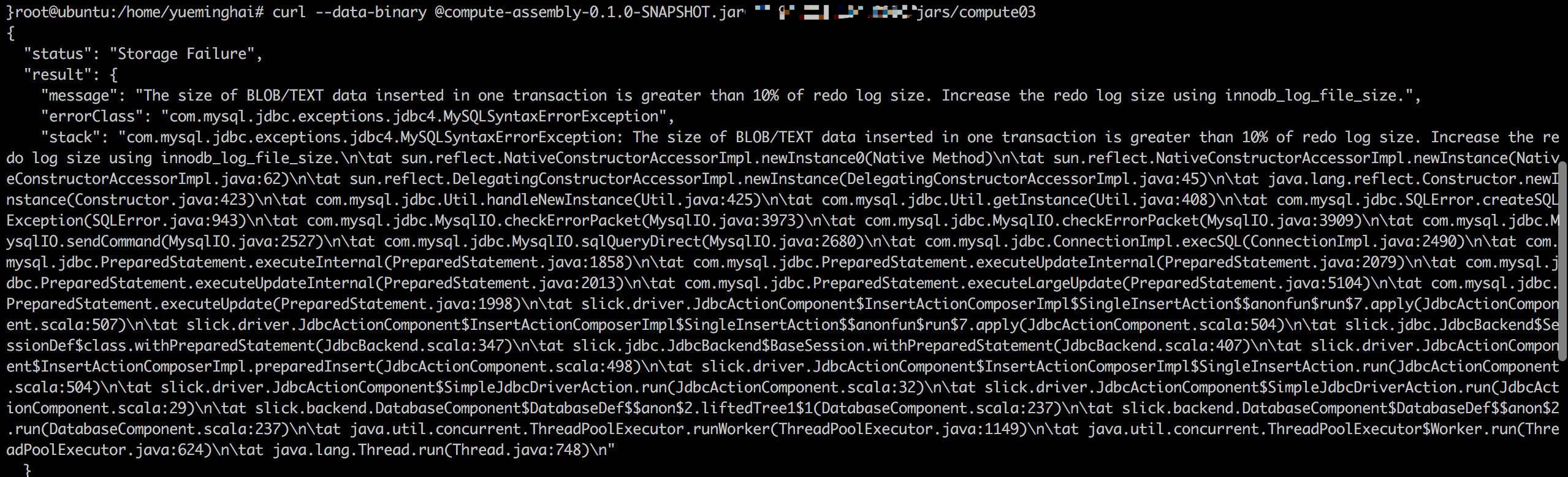
解决方法:vim /etc/my.cnf 添加innodb_log_file_size=600M 添加后重启mysql服务
3)健康检测超时时间问题

解决方法: vim /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/job-server/src/main/resources/application.conf

修改failure-detector.acceptable-heartbeat-pause = 30s
问题解决 :jar包成功上传!

完成~
如有问题欢迎加入qq群讨论 群号:340939208
原文:https://www.cnblogs.com/yueminghai/p/10413171.html
版权声明:本文为博主原创文章,转载请附上博文链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号