

定位页面元素
环境准备
安装fitepath
火狐浏览器-工具-附加组件-搜索firepath进行安装
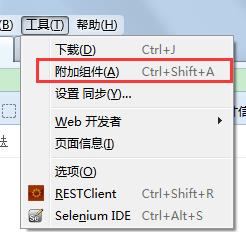


安装firebug插件
火狐浏览器-工具-附加组件-搜索firebug进行安装
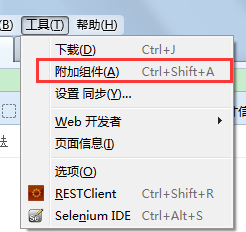

firebug定位
打开firebug点击查看页面元素按钮,再点击想要查看的元素,就可以定位到页面元素内容
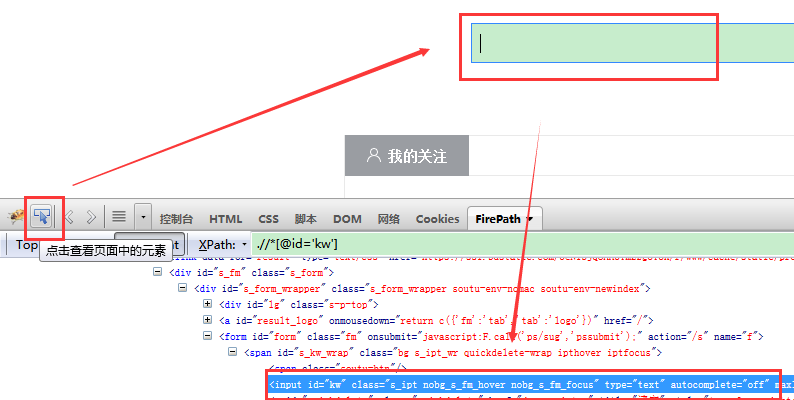
获取单个页面元素
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
使用id定位
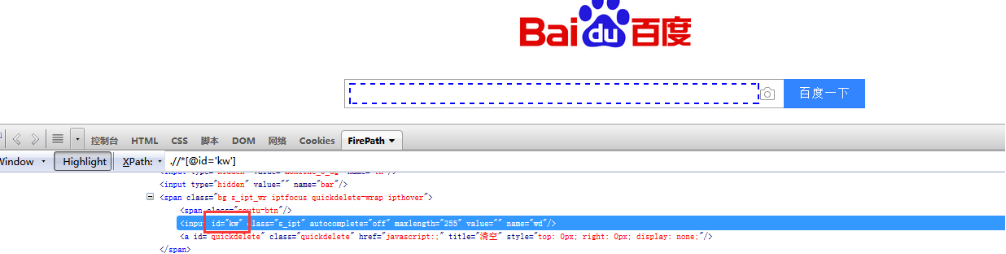
#coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Firefox() #启动火狐浏览器
driver.get("http://www.baidu.com") #打开百度
driver.find_element_by_id('kw').send_keys("ceshi") #通过id定位搜索框然后输入内容
driver.find_element_by_id('su').click() #通过id定位百度一下按钮,并点击该按钮
time.sleep(3)
driver.quit()
使用name定位
如果name属性是唯一的,可以通过那么属性定位
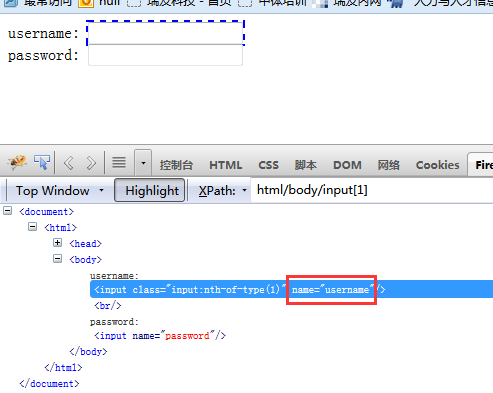
driver.find_element_by_name('username').send_keys("name") #通过name定位输入框
使用class_name定位
class_name 不容易定位到元素
<input id="kw" class="s_ipt" autocomplete="off" maxlength="255" value="" name="wd"/>
driver.find_element_by_class_name('s_ipt').send_keys("ceshi") #通过class_name定位搜索框
使用link_text定位
链接定位

driver.find_element_by_link_text('糯米')
使用partial_link_text定位
模糊链接定位
<a class="mnav" name="tj_trmap" href="http://map.baidu.com">地图</a>
driver.find_element_by_partial_link_text('地')
使用tag_name定位
指标签名称定位,因为相同标签很多,一般不用标签定位,(可以用来定位一组元素,看定位一组元素里面的实例),
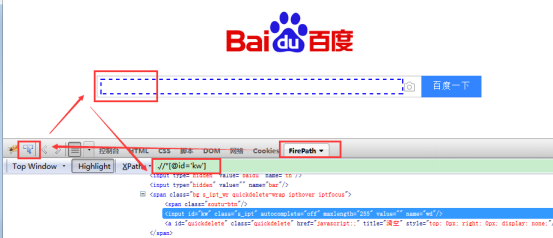
使用xpath定位
通过属性定位
#coding:utf-8
#第一步导入selenium里的webdriver模块
from selenium import webdriver
#第二步 启动浏览器
driver=webdriver.Firefox() #启动火狐浏览器
#第三步 打开url
driver.get("http://www.baidu.com")
driver.find_element_by_xpath("//*[@id='kw']")
通过标签加属性定位
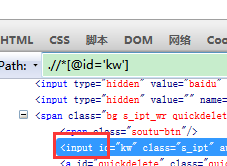
driver.find_element_by_xpath("//input[@id='kw']")
driver.find_element_by_xpath("//input[@name='wd']")
driver.find_element_by_xpath("//*[@id='kw']") #*代表不用指定标签
层级
如果一个元素属性不是很明显,我们可以往上找(父元素)
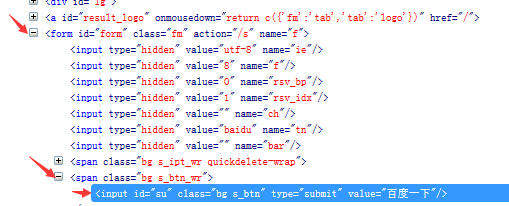
#通过父亲定位input标签
driver.find_element_by_xpath('//span[@class="bg s_btn_wr"]/input')
#通过爷爷定位inpu
driver.find_element_by_xpath('//form[@id="form"]/span[2]/input')
使用css定位
定位百度搜索框

通过class属性定位
用.表示class属性
driver.find_element_by_css_selector(".s_ipt")
通过id属性定位
用#号表示id属性,如:#kw
driver.find_element_by_css_selector("#kw")
通过其它属性定位
driver.find_element_by_css_selector("[autocomplete='off']")
driver.find_element_by_css_selector("[name='wd']")
通过标签定位
driver.find_element_by_css_selector("input#kw") #标签与id属性
driver.find_element_by_css_selector("input.s_ipt")#标签与class属性
driver.find_element_by_css_selector("input[id=’kw’]") #标签与其它属性
使用By定位元素
find_element()方法只用于定位元素。它需要传入两个参数,第一参数是定位的类型,由By提供;第二个参数是定位的具体方式。在使用By之前需要将By类导入
find_element(By.ID,'kw')
find_element(By.NAME,'wd')
find_element(By.NAME,'wd')
find_element(By.CLASS_NAME,'s_ipt')
find_element(By.TAG_NAME,'input')
find_element(By.LINK_TEXT,'新闻')
find_element(By.PARTIAL_LINK_TEXT,'新')
find_element(By.XPATH,"//*[@id='kw']")
find_element(By.CSS_SELECTOR,"#kw")
实例
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By #导入By类
driver=webdriver.Firefox()
driver.get('https://www.baidu.com/')
driver.find_element(By.ID,'kw').send_keys(u'测试') #通过By id定位百度的输入框,然后输入内容
定位一组元素
获取批量页面元素
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
html文件内容:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<form>
<input type="checkbox" name="fruit" value="berry"/>草莓</input>
<br />
<input type="checkbox" name="fruit" value="watermelon" />西瓜</input>
<br />
<input type="checkbox" name="fruit" value="orange"/>橘子</input>
</form>
</body>
</html>
脚本:
1.通过tag_name定位input元素
#coding=utf-8
import time
from selenium import webdriver
driver=webdriver.Firefox()
driver.get(r'C:\Users\yueli\Desktop\a.html')
#选择页面上所有的tag name为input的元素
inputs=driver.find_elements_by_tag_name('input')
#然后从中过滤type为checkbox的元素,单机勾选
for i in inputs:
if i.get_attribute('type')=='checkbox':
i.click()
time.sleep(3)
driver.quit()
备注:get_attribute()方法获取元素的type的属性值
2.通过xpath定位input元素
#coding=utf-8
import time
from selenium import webdriver
driver=webdriver.Firefox()
driver.get(r'C:\Users\yueli\Desktop\a.html')
#通过xpath找到type=checkbox的元素
inputs=driver.find_elements_by_xpath("//input[@type='checkbox']")
for i in inputs:
i.click()
time.sleep(2)
print len(inputs)
#把页面上最后1个checkbox的钩给去掉
driver.find_elements_by_xpath("//input[@type='checkbox']").pop().click()
time.sleep(2)
driver.quit()
3.通过css定位input元素
#coding=utf-8
import time
from selenium import webdriver
driver=webdriver.Firefox()
driver.get(r'C:\Users\yueli\Desktop\a.html')
#通过xpath找到type=checkbox的元素
inputs=driver.find_elements_by_css_selector("input[type=checkbox]")
for i in inputs:
i.click()
time.sleep(2)
print len(inputs)
#把页面上最后1个checkbox的钩给去掉
driver.find_elements_by_css_selector("input[type=checkbox]").pop().click()
time.sleep(2)
driver.quit()
Xpath和css方法 循环式不用加判断方法,因为定位元素是已经做了判断
pop()方法用于获取列表中一个元素,默认为最后一个元素

