机器学习中的几种交叉验证方法(5种)
参考自Kaggle大神approachingalmost的书籍《Approaching (Almost) Any Machine Learning Problem》
交叉验证
在机器学习的有监督训练中,我们通常需要将训练集的一部分划分为验证集,用于评估当前模型的训练效果,避免因多次迭代在训练集上过拟合,影响模型的泛化能力,一般所进行的早停(early stop)也是对验证集的应用。那么如何进行有效的验证,通常会有下面的几个方法:
- K折交叉验证( k-fold cross-validation)
- stratified k-fold cross-validation
- 基于保留集的验证(hold-out based validation)
- 留1交叉验证(leave-one-out cross-validation)
- group k-fold cross-validation
下面对各个交叉验证的方法,从方法介绍、优缺点、与其他方法的比较三个角度进行叙述。
1. K折交叉验证
方法介绍:
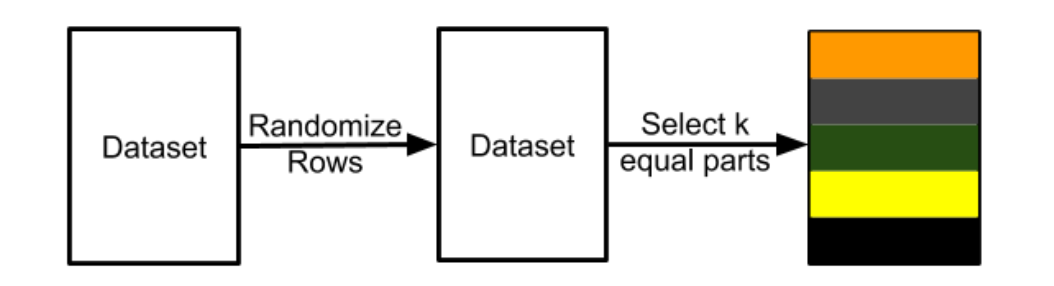
将数据集划分为不相交的样本数量近似相等的k个子集,每次训练选择其中的k-1份作为训练集,剩下的1份作为验证集,重复进行k次实验,取k次验证集的指标的平均值作为最后的模型效果。
优缺点:
- 能够较为准确和全面地评估一个模型在该数据集上的效果。
- 不太适用于小数据集,代价昂贵,需要进行k次实验,耗时上也更长
2. stratified k-fold cross-validation
方法介绍:
和K折交叉验证类似,用于处理类别不平衡数据集的情形,当直接使用K折交叉验证时,有可能会出现某个子集里全是某一个类别的样本,这不符合我们的预期。而对于stratified的K折交叉验证来说,则可以保证,在划分后,每一个子集仍然有和原数据集一样的类别占比情况。
优缺点:
- stratified的方法往往是符合我们对数据集划分的预期的,因此当面对分类问题的时候,通常可以直接选择该方法进行验证
- 类似于K折交叉验证,需要k次实验,成本比较大,而且也不太适合小数据集,因为小数据集的k折划分后可能导致训练数据减少,模型没有充分的训练,直接欠拟合了。
3. 基于保留集的验证
方法介绍:
基于保留集的验证方法,从操作上来看,可能更加符合我们日常的划分方法,每次均是数据集中的同一份作为保留集,也就是验证集来进行实验。
优缺点:
- 保留集验证的好处呢,在于不用像前面K折交叉验证那样,进行多次重复的实验,当数据集足够大的时候,这样的成本也是过于大的,这个时候就可以采用保留集的方法。另一方面,在进行时间序列预测任务的时候,使用基于保留集验证的方式也是合理的,如利用2018年以前的数据预测2019的情况,则前面的16、17、18这些年份的数据就可以用于训练,19年的作为保留集之类的。
- 保留集的方法,个人认为,由于每次使用的是同一个子集(固定随机数后),那可能会由于数据质量等问题,导致刚好这一份子集的验证效果很好,或很差,具有一定的随机性,不是特别能够反映客观问题
4. 留1交叉验证
方法介绍:
正如前面所说的,对于小数据集来说,如果进行k折交叉验证,导致训练的数据过于少的话自然也是不合适的,这个时候就可以采用留1交叉验证,可以认为是一种较为特殊的K折交叉验证的方法,将K折交叉验证中的K的大小设置为数据集中的样本个数,这样每一次就只拿其中一个样本作为验证集,从而能够充分地利用训练集中的数据进行训练。
优缺点:
- 显然,这种方式是没有办法用于大数据集的,那这样的话,训练的时间是相当夸张的,有多少个样本就要训练多少次
- 但这种方式对于小数据集来说是非常合适的
5. group k-fold cross-validation
方法介绍:
当我们的数据集是由多个不同的个体的数据组成的时候,如对于病人的疾病的预测,那自然每个个体都是可能存在一定的特异性的,直观上来说,如果一个个体的数据,一部分用于了训练,另一部分验证,那通常一定是比拿别的个体的数据用于训练,当前个体的数据只用于验证的效果比起来是更好的。所以,为了避免这种情况的发生,更严谨地评估模型的泛化能力,这个时候可以使用groupKFold进行验证,他可以保证一部分个体的全部数据只存在于训练中,而另一部分个体的数据只存在于验证集中。
优缺点:
- 对于来自于不同个体组成的数据来说,采用groupKFold能够更加严谨地评估模型的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号