


论文学习——《Good View Hunting: Learning Photo Composition from Dense View Pairs》
论文链接:http://www.zijunwei.org/papers/cvpr18-photo-composition.pdf
代码及数据集链接:https://www3.cs.stonybrook.edu/~cvl/projects/wei2018goods/VPN_CVPR2018s.html
本文贡献
1.建立了一个大型数据集——Comparative Photo Composition (CPC) dataset;
2.提出了一个新颖的知识转移框架来训练基于锚框的实时VPN模型(view proposal model);
首先使用Siamese架构在视图对上训练一个视图评估模型,然后我们将这个模型作为一个老师来对各种图像上的候选锚盒进行评分,这些教师评分将视VPN训练为学生模型,以输出相同的锚框评分排名。为了训练学生,我们提出了平均两两误差(MPSE)损失。
VPN模型:以图像作为输入,并输出与预定义锚框列表相对应的分数。
训练View Proposal Networks
本文提出一个知识转移框架,在教师模型VEN(View Evaluation Net)的监督下将View Proposal Net(VPN)训练为学生模型。 VEN,它需要一个视图作为输入,并预测组成的分数,因此这可以直接在我们的CPC数据集训练。 为了转移知识,我们在给定图像的锚点框上运行VEN,然后使用预测的分数、新颖的平均成对平方误差(MPSE)损失训练VPN。
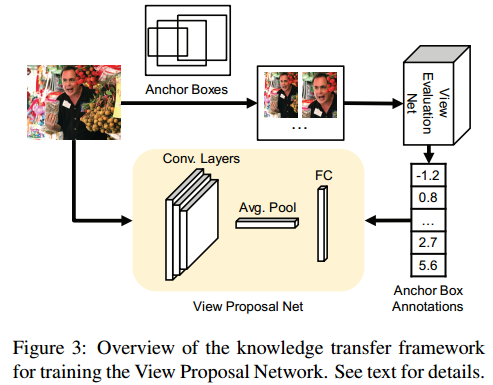
VPN:SSD+MultiBox
骨干网络是基于SSD(Conv9之后被截)的,在骨干网的顶部,我们添加了一个卷积层、一个平均池化层和一个全连接层,输出N个分数,对应于N个预定义的锚盒。我们通过在不同比例和长宽比的标准化图像上密集滑动来预先定义锚盒集,结果得到一组N = 895个预定义锚盒。
VEN:Siamese结构
我们采用Siamese结构训练VEN,Siamese结构是由两个共享权重的VEN组成,每个输出输入图像对中对应图像的分数。本文VEN是基于VGG16(在最后一个最大池化层之后截断)的,其中包含两个新的全连接(FC)层和一个新的输出层。由于我们的模型只输出一个排名分数,而不是1000多个类的概率分布,所以我们将FC层的通道分别减少到1024和512。
训练网络trick——知识蒸馏
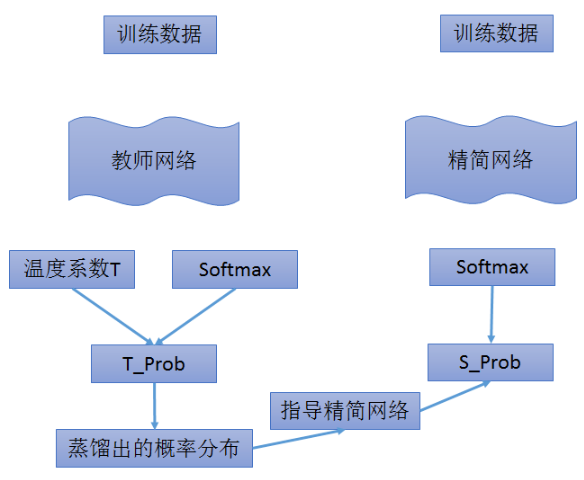
教师网络:大规模,参数量大的复杂网络模型。难以应用到设备端的模型。
学生网络:小规模,参数量小的精简网络模型。可应用到设备端的模型,俗称可落地模型。
参考博客:https://blog.csdn.net/qiu931110/article/details/88085540
