
python爬虫框架scrapy开坑
最近对爬虫产生了兴趣,在知乎上闲逛时发现都说scrapy不错,于是学习一波。
安装参考https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/install.html#scrapy,我唯一遇到的坑就是没有没有安装对应版本的pywin32。
首先上个scrapy的结构图
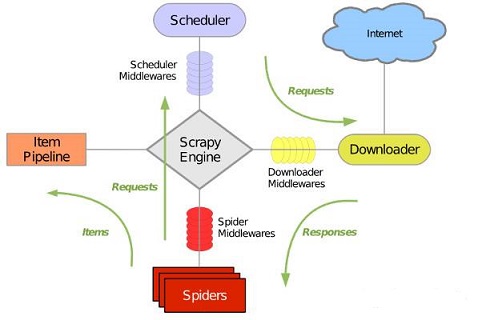
组件的作用:
- Scrapy Engine负责各个组件的调度
- Item Pipeline负责处理Spider提取出的item,如进行数据清洗等
- Spiders负责分析并提取item或继续执行其他任务
- Downloader负责将数据提供给引擎再传递给Spider解析
- Scheduler从引擎那里接受Request请求并将其放入队列中
数据流动:
Scrapy Engine将第一个request请求放在Scheduler中,发起request请求,Downloader组件下载数据并将结果返回给Spiders,Spiders将已下载的item发送给Item Pipeline,而还需要继续的请求(如访问下一页的内容)发送给引擎,再次进行上述过程。
大概的了解了之后让我们开始愉快的使用scrapy吧!
动力总是来自于兴趣,有请"受害者"P站。知道P站的应该都会收藏不少好图,但要一个个下载太麻烦,我们就用爬虫解决这个问题。
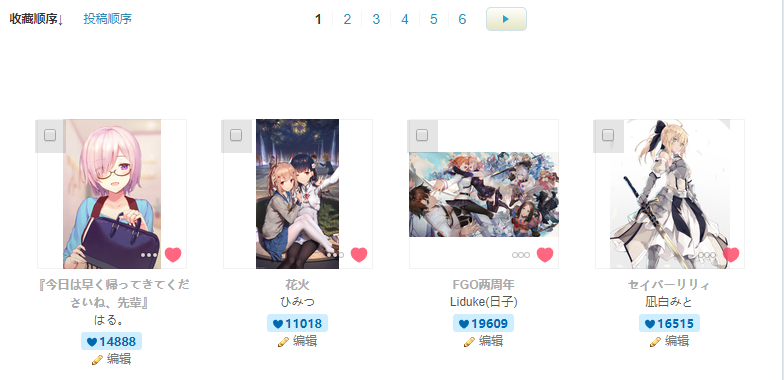
我们先分析这些图片的数据是从哪来的,查看网络请求
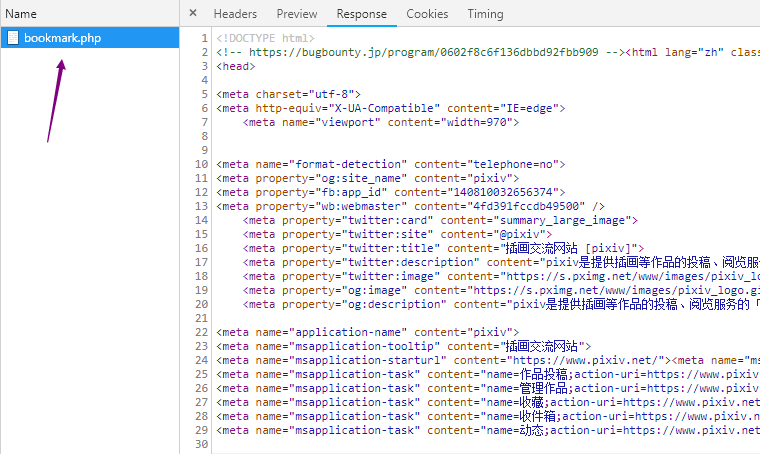
通过分析我们发现图片的地址和名字都在返回的html中,也省却了些麻烦。不过由于被墙了所以我们需要使用代理,弄个VPN还是必须的。
输入命令:scrapy startproject pixivbook创建项目
目录文件夹:
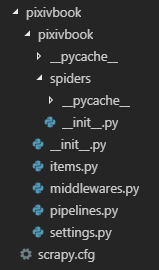
现在是没有爬虫脚本的,再通过命令scrapy genspider pixiv www.pixiv.net创建名字为pixiv.py,目标地址为www.pixiv.net的爬虫。这里不要自己新建个爬虫脚本,必须使用命令创建不然引擎会找不到爬虫。并且爬虫的名字不能和项目的名字相同。。。。。。
说了这么多我们编写items.py吧
import scrapy
class PixivbookItem(scrapy.Item):
# 存储图片名字
name = scrapy.Field()
# 存储图片url
url = scrapy.Field()
pass
接着编写spider脚本(pixiv.py)。
这里由于我不是很熟悉配置所以重写了首次的request
def start_requests(self):
start_urls = 'https://www.pixiv.net/bookmark.php'
yield Request(url = start_urls,cookies = {},callback=self.parse) #为了保护我的图就没有cookie haha
不过毕竟是个知名的网站,因此对于user-agent头进行了检验,所以我们在middlewares.py中需要添加随机的user-agent头,也比较简单。而且这个网站被墙了所以需要使用VPN之类的。(这里我用的vpn软件做了全局代理,因此代理IP为127.0.0.1)
class my_proxy(object):
def process_request(self, request, spider):
request.meta['proxy'] = 'https://127.0.0.1:25378'
class my_requestheader(object):
def process_exception(self, request, exception, spider):
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'
]
agent = random.choice(USER_AGENT_LIST)
request.headers['user-agent'] = agent
配置好之后将这两个中间件放在settings.py文件中,由于会验证cookie所以还需要开启cookie
DOWNLOADER_MIDDLEWARES = {
'pixivbook.middlewares.my_proxy': 543,
'pixivbook.middlewares.my_requestheader': 544
}
COOKIES_ENABLED = True
这里后面的数字越小优先级越高,具体的顺序要正确。
让我们回到爬虫脚本中,初始请求已经发出,我们需要做的是对返回的数据进行处理。获取元素内容用的是xpath,不了解的可以去https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html?highlight=xpath看看。这部分我们需要将返回的数据存在item中并判断是否还需要进行后续的爬取。
def parse(self, response):
picture_list = response.xpath("//div[@class='display_editable_works']//li[@class='image-item']")
for i_item in picture_list:
pixiv_item = PixivbookItem()
pixiv_item['name'] = i_item.xpath(".//a[2]/h1[@class='title']/text()").extract_first().replace('\\','')
pixiv_item['url'] = [i_item.xpath(".//div[@class='_layout-thumbnail']/img[@class='ui-scroll-view']/@data-src").extract_first().replace('c/150x150/','')]
yield pixiv_item
next_link = response.xpath("//div[@class='pager-container']/span[@class='next']/a[@class='_button']")
if next_link:
next_link = next_link[0].xpath("./@href").extract_first()
yield scrapy.Request('https://www.pixiv.net/bookmark.php'+next_link,callback=self.parse)
这里有两个坑:
- items.py里面的字段是用来发送request请求的,必须得是list类型,因此要加上[]符号,卡这里好久。。。。。。
- next_link必须是str类型才能拼接,所以必须执行next_link = next_link[0].xpath("./@href").extract_first(),直接用next_link会报错
还有就是通过xpath直接获取的url地址是缩略图,需要将地址中的"c/150x150/"替换为空。对比小图和点开图片后的大图地址就知道了。通过判断类名为next_link的按钮是否存在就能判断还有没有图片。
要想获得数据还需要在settings.py里将ITEM_PIPELINE启用。顺便加上图片存储的路径。
ITEM_PIPELINES = {
'pixivbook.pipelines.PixivbookPipeline': 300,
'pixivbook.pipelines.DownloadImagesPipeline': 5
}
IMAGE_STORE = r'' #自己加上保存的路径
这里我是用scrapy的ImagesPipeline下载十分方便,不过它会把图片名字命名为图片地址的MD5加密形式,而我希望能保存图片本来的名字,所以查阅了一些资料后知道可以通过重写file_path和get_media_requests函数实现。另一种方法是在item_completed函数中改名,不过我总是遇到路径问题就先用上一种简单的。
我们再编写一个DownloadImagePipeline中间件,它继承了ImagesPipeline,改写相应的方法
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
from scrapy.exceptions import DropItem
import os
class PixivbookPipeline(object):
def process_item(self, item, spider):
return item
class DownloadImagesPipeline(ImagesPipeline):
def get_media_requests(self,item,info):
for image_url in item['url']:
#PHPSESSID,device_token,login_ever填上对应的值即可
yield Request(image_url,cookies = {'PHPSESSID':'','device_token':'','login_ever':''},meta={'name': item['name']})
def file_path(self,request,response=None,info=None):
name = request.meta['name'] + '.jpg'
return name
这里通过在get_media_requests函数中Request时添加了一个meta数据,在file_path中可以获取到它,直接返回图片名字即可。上次编写时就知道必须要加上refer头才行,所以我们在settings.py中再配置一下
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'referer': 'https://www.pixiv.net/ranking.php?mode=daily&content=illust'
}
REFERER_ENABLED = True
到这就大功告成了,输入scrpy crawl pixiv命令运行即可。
tips:
1.scrpy crawl pixiv -o test.csv 将items.py中存储的数据导出到test.csv文件中
2.scrpy crawl pixiv -o test.json 将items.py中存储的数据导出到test.json中,保存为unicode编码格式
可能还有些地方说得不够清楚,有问题可以看看这里https://github.com/yuehenying/python/tree/master/pixivbook,留言也行,欢迎大家交流

