
第一次个人项目
| 这个项目属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/ |
|---|---|
| 作业要求 | 论文查重 |
| github | https://github.com/zhong3120004997/zhong3120004997/blob/main/3120004997 |
一、PSP表格。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 80 |
| Estimate | · 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | 200 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 90 | 120 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 60 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 90 |
| · 合计 | 1070 | 1340 |
二、需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
三、设计思路;
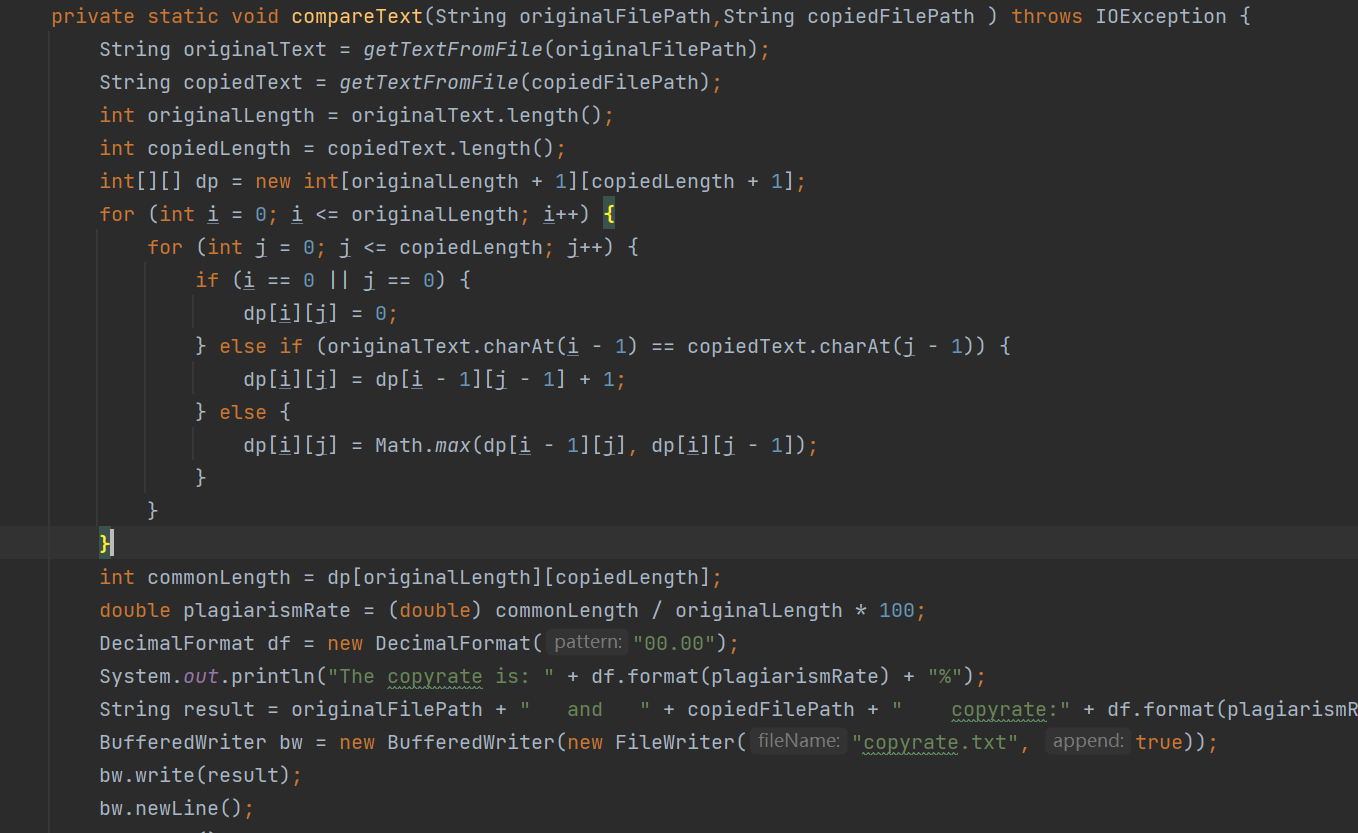
从命令行中输入需要比较的文本的地址,使用动态规划来比较两个文本的相似度,首先将原始文本和剽窃文本转换为字符串。然后创建一个二维数组dp,用来保存原始文本和剽窃文本的匹配长度。接着使用两层循环遍历原始文本和剽窃文本的每个字符,并根据字符是否相同来更新dp数组的值。最后通过计算匹配长度和原始文本长度的比值来得出剽窃率。
四、性能分析。
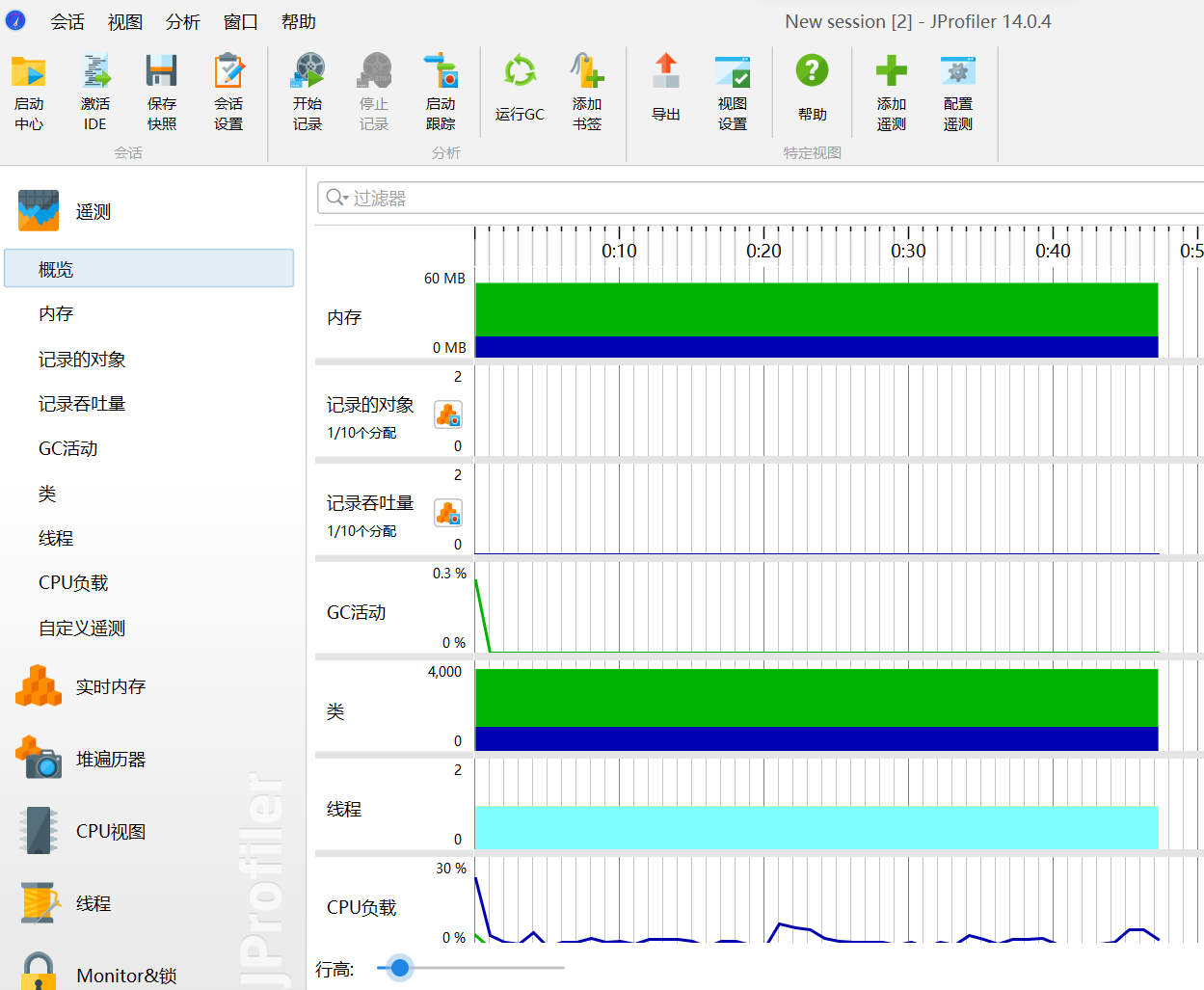

消耗最大的函数方法为文本比对
五、程序部分。
主要有两个方法,一是从文本地址取出文本内容的方法getTextFromFile(String filePath),二是两个文本内容进行对比比较的获取重复率的方法compareText(String originalFilePath,String copiedFilePath );
命令窗口执行结果如下(与idea内运行结果有出入,不知是何原因待改进):

程序中主要出现IO输入异常以及文本获取异常,比如输入的参数有误或者不符合要求,或者在程序运行中找不到文件所在地址等,这时我们尽量输入的是文件的绝对路径来防止出现异常。


