Robotics Lab3 ——图像特征匹配、跟踪与相机运动估计
Robotics Lab3 ——图像特征匹配、跟踪与相机运动估计
图像特征匹配
图像特征点
- 携带摄像头的机器人在运动过程中,会连续性地获取多帧图像,辅助其感知周围环境和自身运动。时间序列上相连的两幅或多幅图像,通常存在相同的景物,只是它们在图像中的位置不同。而位置的变换恰恰暗含了相机的运动,这时就需要相邻图像间的相似性匹配。
- 选取一大块图像区域进行运动估计是不可取的。已知图像在计算机内部是以数字矩阵的形式存储的,[如灰度图的每个元素代表了单个像素的灰度值]。而对于点的提取和匹配较为方便,且和数字值对应,所以引入图像特征点辅助估计相机的运动。
- 理解:以灰度值存储的图像矩阵,单个图像像素即为图像中的点,但不一定是图像中的特征点,因为灰度值受光照、形变、物体材质等的影响严重,在不同图像间的变化大,不够稳定。而图像的特征点一定是具有代表性的点,其在相邻的图像间保持稳定,一般选择图像的角点作为特征点,具有稳定性、易辨认的特征。
- 特征点组成:特征点包括关键点(Keypoint)和描述子(Descriptor)两部分。对特征点作处理时,涉及关键点的提取和描述子的计算。其中,关键点表示该特征点在图像中的位置、朝向、大小等信息;描述子通常为一个向量,描述该关键点周围像素的信息,是加以对比的信息。如果两个特征点的描述子向量之间的距离较小,则可以认为这两幅图像中的特征点是同一个。
- 人工特征点:朴素的角点在相机移动或旋转时会发生变化,因此人为地设计了更加稳定的局部图像特征:SIFT,SURF,FAST,ORB等。
- SIFT充分考虑了光照、尺度、旋转等信息,计算量很大。
- FAST没有描述子,不具有方向性,计算速度极快。
- ORB:关键点(Oriented FAST)为改进的FAST角点,其计算了特征点的主方向,为其描述子增加了旋转不变特性。描述子(BRIEF)采用二进制,计算速度快。
特征点提取
特征点的提取是与关键点和描述子紧紧关联的;
这里以ORB为例展示特征点的提取过程。
- FAST关键点:灰度图中,局部像素灰度值变化明显的地方极有可能是一个物体的边缘,角点存在于其中,为与其邻域像素值差别较大的像素点。角点的检测(即是否为特征点的判断)分为以下五个步骤(针对整幅图像)——来自视觉SLAM十四讲:
- 在图像中选取像素 p,假设它的亮度为 Ip。
- 设置一个阈值 T (比如 Ip 的 20%)。
- 以像素 p 为中心, 选取半径为 3 的圆上的 16 个像素点。
- 假如选取的圆上,有连续的 N 个点的亮度大于 Ip + T 或小于 Ip - T,那么像素 p
可以被认为是特征点 (N 通常取 12,即为 FAST-12。其它常用的 N 取值为 9 和 11,
他们分别被称为 FAST-9, FAST-11)。
- 循环以上四步,对每一个像素执行相同的操作 。
下图较为清晰的描述了角点的检测:

为了提高算法效率,可以跳跃式检测每个像素邻域圆上的像素值,如第1,5,9,13个。
为了避免角点集中,需采用非极大值抑制,即在一定区域内仅保留响应极大值的角点。
-
Oriented FAST关键点:由于FAST角点存在一定的问题,ORB关键点对其进行了改进。
- FAST特征点数量大且不确定。
我们往往希望对图像提取固定数量的特征,这样易于计算和匹配。改进的方式为:指定最终要提取的角点数量N,对原始提取的FAST角点分别计算Harris响应值,然后选取前N个具有最大响应值的角点。
- FAST角点不具有方向信息,而且选取半径为3的邻域圆也存在尺度问题。
ORB关键点添加了对尺度和旋转的描述。其中,尺度不变性通过构建图像金字塔 [ 同一图像的不同分辨率表示 ],在每一层进行角点检测;
旋转不变性采用灰度质心法实现,质心是指以图像块灰度值作为权重的中心,其具体步骤如下——来自视觉SLAM十四讲:
-
在一个小的图像块 B 中,定义图像块的矩为:
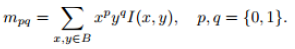
这里的矩实际为HU矩中的原点矩。其一般用来识别图像中大的物体,能够较好地描述物体的形状,要求图像的纹理特征不能太复杂。
-
通过矩可以找到图像块的质心:
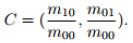
-
连接图像块的几何中心 O 与质心 C,得到一个方向向量
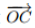 ,于是特征点的方向可以定义为:
,于是特征点的方向可以定义为:
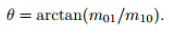
这里θ即为旋转的角度描述。
知识点拓展:图像的几何矩
- 在数学中,矩的本质是数学期望,即:
\[\int x · f(x) dx \] 其中f(x)代表x的概率密度。
-
在灰度图像中,每个像素点的值可以看成该处的密度。对某个像素点的值求期望即得到了图像在该点处的矩。矩有原点矩(零阶矩)、一阶矩、二阶矩;由零阶矩和一阶矩可以计算某个形状的重心,而二阶矩可以计算形状的方向。
\[零阶矩:M_{00} = \sum_{x,y} I(x,y) \]\[一阶矩:M_{10} = \sum_{x,y} x·I(x,y);M_{01} = \sum_{x,y}y·I(x,y) \]\[推出图像的重心(质心)坐标:x_c = \frac{M_{10}}{M_{00}};y_c = \frac{M_{01}}{M_{00}} \]这种质心计算方法的优点为:对噪声不敏感。
\[二阶矩:M_{20} = \sum x^2 · I(x,y);M_{02} = \sum y^2 · I(x,y);M_{11}=\sum x·y·I(x,y) \]\[ 则物体的形状方向:θ = \frac{1}{2}arctan(\frac{2b}{a-c}),θ∈[-90°,90°] \]\[ 其中,a=\frac{M_{20}}{M_{00}}-x_c^2;b=\frac{M_{11}}{M_{00}}-x_cy_c;c=\frac{M_{02}}{M_{00}}-y_c^2; \]图像的矩具有旋转、平移、尺度等的不变性,又称为不变矩。
-
BRIEF描述子:一种二进制描述子,向量由多个0和1组成,这里0和1表示关键点附近的两个像素(如p,q)的大小关系——p>q,取1;p<q,取0。而p和q的选取是按照某种概率分布随机选取。
优点:速度快,存储方便;适用于实时的图像匹配。
-
改进BRIEF描述子(rBRIEF):加入旋转因子,改进旋转不变性;改进特征点描述子的相关性(即可区分性),对误匹配率影响较大。
特征匹配
特征匹配实际上描述的是连续的两张图像中景物的对应关系,以此来估计相机的运动。
-
匹配方法:
-
暴力匹配。即图像1中取特征点集合A,图像2中取特征点集合B,对A中的每一个特征点,依次与B中所有的特征点测量两者描述子的距离,然后排序,取距离最近的作为匹配的两个特征点。
这里,描述子距离表示了两张图片两个特征点之间的相似程度,在实际应用中可以取不同的距离度量范数。如:对于浮点类型,使用欧氏距离;对于二进制类型,使用汉明距离[即两个二进制串之间不同位数的个数]。
缺点:计算量随特征点数量增大呈递增趋势。
-
快速近似最近邻(FLANN)。集成于OpenCV,适合于匹配点数量极多的情况。
-
双目图像中ORB特征点的提取和匹配代码分析
注释写在了源代码里。
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace std;
using namespace cv;
int main ( int argc, char** argv )
{
if ( argc != 3 )
{
cout<<"usage: feature_extraction img1 img2"<<endl;
return 1;
}
//-- 读取图像,以RGB格式读取
Mat img_1 = imread ( argv[1], CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );
//-- 初始化
/*
* 1. FeatureDetector特征检测器类,通过创建该类对象来使用多种特征检测方法。【用于检测指定特征点的角点位置】
OpenCV2.4.3中提供了10种特征检测方法:FAST,SIFT,SURF,ORB,HARRIS,SimpleBlob,STAR,MSER,GFTT,Dense。
这里使用ORB特征检测方法
* 2. DescriptorExtractor特征描述子提取类,提供了一些特征描述子提取的算法。
其可以针对图像关键点,计算其特征描述子,其可以被表达成密集(dense),即固定维数的向量。
其计算方式为每隔固定个像素计算。
一个特征描述子是一个向量,特征描述子的集合为Mat格式,每一行是一个关键点的特征描述子。
OpenCV支持四种类型的特征描述子提取方法:SIFT,SURF,ORB,BRIEF。
* 3. DescriptorMatcher特征匹配类,提供了一些特征点匹配的方法。
该类主要包含图像对之间的匹配以及图像和一个图像集之间的匹配。
OpenCV2中的特征匹配方法都继承自该类。
对于误匹配情况,提供了KNNMatch方法。
*/
std::vector<KeyPoint> keypoints_1, keypoints_2; // 声明存放两张图片各自关键点的向量
Mat descriptors_1, descriptors_2; // 两张图片特征点的描述子,形式为向量
Ptr<FeatureDetector> detector = ORB::create(); // 创建FeatureDetector类型的指针detector
Ptr<DescriptorExtractor> descriptor = ORB::create(); // ORB特征描述子提取指针
// Ptr<FeatureDetector> detector = FeatureDetector::create(detector_name);
// Ptr<DescriptorExtractor> descriptor = DescriptorExtractor::create(descriptor_name);
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create ( "BruteForce-Hamming" ); // 匹配时计算描述子之间的距离使用汉明距离
//-- 第一步:检测 Oriented FAST 角点位置,使用detect方法,将其存入Keypoints变量中
detector->detect ( img_1,keypoints_1 );
detector->detect ( img_2,keypoints_2 );
//-- 第二步:根据角点位置计算 BRIEF 描述子,使用compute方法,将其存入descriptors变量中
descriptor->compute ( img_1, keypoints_1, descriptors_1 );
descriptor->compute ( img_2, keypoints_2, descriptors_2 );
/*
* 绘制第一幅图像的ORB特征点,注意这里要把图片的名称全改为英文才能正常显示。
*/
Mat outimg1;
drawKeypoints( img_1, keypoints_1, outimg1, Scalar::all(-1), DrawMatchesFlags::DEFAULT );
imshow("ORB features.jpg",outimg1);
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
/*
* Brute-Force(BF)匹配器,取第一个集合里一个特征的描述子并与第二个集合里所有特征的描述子计算距离,返回最近的特征点。
其有两个方法:BFMatcher.match()和BFMatcher.knnMatch(),前者返回最匹配的特征点(仅一个),后者返回k个最匹配的特征点,k由用户指定。
*/
vector<DMatch> matches; // DMatch类型的向量。
//BFMatcher matcher ( NORM_HAMMING );
matcher->match ( descriptors_1, descriptors_2, matches ); // 使用match方法,获取最匹配的两个特征点(匹配的特征点可以有多对,均存放在matche中)
//-- 第四步:匹配点对筛选
double min_dist=10000, max_dist=0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
/*
* descriptors的每行为一个特征点的描述子向量;图像1中有多少个特征点,matches中存储多少个匹配的图像2的特征点相关类型
*/
for ( int i = 0; i < descriptors_1.rows; i++ )
{
double dist = matches[i].distance; // 得出每对匹配的描述子间的距离
if ( dist < min_dist ) min_dist = dist;
if ( dist > max_dist ) max_dist = dist;
}
// 仅供娱乐的写法
min_dist = min_element( matches.begin(), matches.end(), [](const DMatch& m1, const DMatch& m2) {return m1.distance<m2.distance;} )->distance;
max_dist = max_element( matches.begin(), matches.end(), [](const DMatch& m1, const DMatch& m2) {return m1.distance<m2.distance;} )->distance;
printf ( "-- Max dist : %f \n", max_dist );
printf ( "-- Min dist : %f \n", min_dist );
/*
* 对于误匹配情况采取的措施
*/
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
std::vector< DMatch > good_matches;
for ( int i = 0; i < descriptors_1.rows; i++ )
{
if ( matches[i].distance <= max ( 2*min_dist, 30.0 ) )
{
good_matches.push_back ( matches[i] );
}
}
//-- 第五步:绘制匹配结果,数量分别为matches和good_matches
Mat img_match;
Mat img_goodmatch;
drawMatches ( img_1, keypoints_1, img_2, keypoints_2, matches, img_match );
drawMatches ( img_1, keypoints_1, img_2, keypoints_2, good_matches, img_goodmatch );
imshow ( "all match features.jpg", img_match ); // 注意这里图片名要改成英文
imshow ( "good match features.jpg", img_goodmatch );
waitKey(0);
return 0;
}
相机姿态运动求解
基于特征点法的视觉里程计
- 视觉SLAM主要分为视觉前端和优化后端,前端即视觉里程计(VO),其作用是根据相邻图像的信息,估计相机运动,提供初始值给后端。
- 根据是否需要提取特征,VO分为特征点法和直接法。
- 特征点法的缺点:1. 关键点的提取与描述子的计算非常耗时;2.容易忽略除特征点以外的所有信息;3.相机有时候会运动到特征缺失的地方,往往这些地方没有明显的纹理信息。
ICP问题
用于3D-3D的位姿估计,即两张图像为3D图像(如RGB-D相机获取的图像),其中的3D特征点集合已经提取和匹配好。
-
ICP即为迭代最近点,仅考虑两组3D点之间的变换,此时和相机无关。特征点方法正好为我们提供了两张图像之间良好的匹配关系,ICP可以据此进行运动估计。
-
利用线性代数方法的求解(SVD):由两张图片,得到两组匹配好的3D特征点集合,这两组一一对应的点之间具有欧氏变换关系,即集合1中的点能由集合2中的点通过变换矩阵得到,即有R和T表示两个点之间的关系。
匹配好的特征点对会存在一定的误差,定义误差项,由误差项构建最小二乘问题,即表示误差平方和,求一个最优化问题,这里是求使误差平方和达到极小的R,t。
【理解:因为ICP问题求解的目的是得出相机的位姿估计,可以理解为当拍摄到第二帧图像时相机的位置与拍摄第一帧图像时相机原位置的变换关系,而变换关系可以用欧氏矩阵R和t描述,而由匹配的特征点对可以描述多个相机位姿,这里就涉及一个最优化问题,即构建最小二乘,求解使相机位姿相对最精确的R和t。】
[注:但是具体的求解数学公式没看懂。]
-
利用非线性优化方法的求解:以迭代的方式找最优值。[同样数学式没看懂。]
ICP法相机姿态估计代码分析
源代码提供了SVD和非线性优化两种方法。
添加了一点关键注释。
void find_feature_matches (
const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches ); // 获得两幅图像中匹配好的特征点信息
// 像素坐标转相机归一化坐标
Point2d pixel2cam ( const Point2d& p, const Mat& K );
void pose_estimation_3d3d (
const vector<Point3f>& pts1,
const vector<Point3f>& pts2,
Mat& R, Mat& t
);
void bundleAdjustment(
const vector<Point3f>& points_3d,
const vector<Point3f>& points_2d,
Mat& R, Mat& t
);
// g2o edge
/*
* g2o是一个图优化库,图优化的本质仍然是非线性优化,而用图的方式表示,可以使问题可视化。
*/
class EdgeProjectXYZRGBDPoseOnly : public g2o::BaseUnaryEdge<3, Eigen::Vector3d, g2o::VertexSE3Expmap>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
EdgeProjectXYZRGBDPoseOnly( const Eigen::Vector3d& point ) : _point(point) {}
virtual void computeError()
{
const g2o::VertexSE3Expmap* pose = static_cast<const g2o::VertexSE3Expmap*> ( _vertices[0] );
// measurement is p, point is p'
_error = _measurement - pose->estimate().map( _point );
}
virtual void linearizeOplus()
{
g2o::VertexSE3Expmap* pose = static_cast<g2o::VertexSE3Expmap *>(_vertices[0]);
g2o::SE3Quat T(pose->estimate());
Eigen::Vector3d xyz_trans = T.map(_point);
double x = xyz_trans[0];
double y = xyz_trans[1];
double z = xyz_trans[2];
_jacobianOplusXi(0,0) = 0;
_jacobianOplusXi(0,1) = -z;
_jacobianOplusXi(0,2) = y;
_jacobianOplusXi(0,3) = -1;
_jacobianOplusXi(0,4) = 0;
_jacobianOplusXi(0,5) = 0;
_jacobianOplusXi(1,0) = z;
_jacobianOplusXi(1,1) = 0;
_jacobianOplusXi(1,2) = -x;
_jacobianOplusXi(1,3) = 0;
_jacobianOplusXi(1,4) = -1;
_jacobianOplusXi(1,5) = 0;
_jacobianOplusXi(2,0) = -y;
_jacobianOplusXi(2,1) = x;
_jacobianOplusXi(2,2) = 0;
_jacobianOplusXi(2,3) = 0;
_jacobianOplusXi(2,4) = 0;
_jacobianOplusXi(2,5) = -1;
}
bool read ( istream& in ) {}
bool write ( ostream& out ) const {}
protected:
Eigen::Vector3d _point;
};
int main ( int argc, char** argv )
{
if ( argc != 5 )
{
cout<<"usage: pose_estimation_3d3d img1 img2 depth1 depth2"<<endl;
return 1;
}
//-- 读取图像
Mat img_1 = imread ( argv[1], CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );
vector<KeyPoint> keypoints_1, keypoints_2;
vector<DMatch> matches;
find_feature_matches ( img_1, img_2, keypoints_1, keypoints_2, matches );
cout<<"一共找到了"<<matches.size() <<"组匹配点"<<endl;
// 建立3D点
Mat depth1 = imread ( argv[3], CV_LOAD_IMAGE_UNCHANGED ); // 深度图为16位无符号数,单通道图像
Mat depth2 = imread ( argv[4], CV_LOAD_IMAGE_UNCHANGED ); // 深度图为16位无符号数,单通道图像
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 ); // 理解这里的K为相机内参
vector<Point3f> pts1, pts2;
for ( DMatch m:matches )
{
ushort d1 = depth1.ptr<unsigned short> ( int ( keypoints_1[m.queryIdx].pt.y ) ) [ int ( keypoints_1[m.queryIdx].pt.x ) ];
ushort d2 = depth2.ptr<unsigned short> ( int ( keypoints_2[m.trainIdx].pt.y ) ) [ int ( keypoints_2[m.trainIdx].pt.x ) ];
if ( d1==0 || d2==0 ) // bad depth
continue;
Point2d p1 = pixel2cam ( keypoints_1[m.queryIdx].pt, K ); // 通过相机内参将两幅图像特征点的像素坐标转化为相机坐标
Point2d p2 = pixel2cam ( keypoints_2[m.trainIdx].pt, K );
float dd1 = float ( d1 ) /5000.0; // 深度值尺度缩放
float dd2 = float ( d2 ) /5000.0;
pts1.push_back ( Point3f ( p1.x*dd1, p1.y*dd1, dd1 ) ); // 得到特征点的3D坐标
pts2.push_back ( Point3f ( p2.x*dd2, p2.y*dd2, dd2 ) );
}
cout<<"3d-3d pairs: "<<pts1.size() <<endl;
Mat R, t;
pose_estimation_3d3d ( pts1, pts2, R, t ); // 求得最优的R和t
cout<<"ICP via SVD results: "<<endl;
cout<<"R = "<<R<<endl;
cout<<"t = "<<t<<endl;
cout<<"R_inv = "<<R.t() <<endl;
cout<<"t_inv = "<<-R.t() *t<<endl;
cout<<"calling bundle adjustment"<<endl;
bundleAdjustment( pts1, pts2, R, t ); // 非线性优化方法求解ICP问题
// verify p1 = R*p2 + t
for ( int i=0; i<5; i++ )
{
cout<<"p1 = "<<pts1[i]<<endl;
cout<<"p2 = "<<pts2[i]<<endl;
cout<<"(R*p2+t) = "<<
R * (Mat_<double>(3,1)<<pts2[i].x, pts2[i].y, pts2[i].z) + t
<<endl;
cout<<endl;
}
}
还有feature_extraction.cpp中的特征点提取、匹配和跟踪的代码,这个上边已经分析过了。
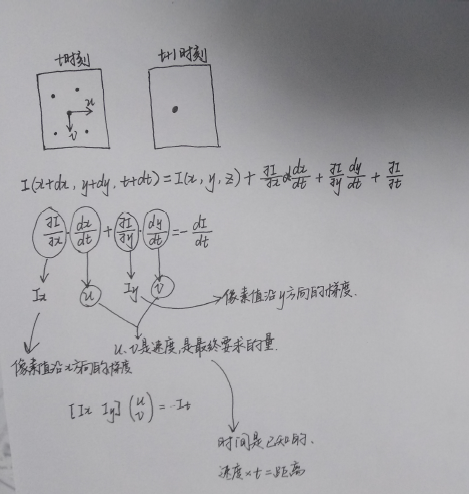
基于光流法的视觉里程计
绘制了光流法的原理图