

2017年9月15日-2017年10月20日 大型openstack项目运维笔记
1、三个ceph monitor节点clock skew时钟偏移问题?
解决:(1)其他控制节点更改ntp.conf与controller01进行同步,如果ntpd不生效,使用date -s "10:24:25"命令强制更改。
(2)[root@node-3 ~]# ceph health detail
mon.node-3 addr 192.168.15.4:6789/0 clock skew 14.5967s > max 5s (latency 0.0261497s)
[root@node-3 ~]# vim /etc/ceph/ceph.conf
mon_clock_drift_allowed = 15 ##注意上面的14.567秒,必须大于这个值才行,当然前提是NTP已经同步,date时间相同
mon_clock_drift_warn_backoff = 30
[root@node-3 ~]# ceph-deploy --overwrite-conf admin node-1 node-2
[root@node-3 ~]# systemctl restart ceph-mon@node-3.service
然后,登陆到node-1、node-2分别只需要重启mon服务,不需要重启存储节点的osd服务,一个节点运行systemctl restart ceph-mon.target应该也行,会重启所有Mon,实验结果好像不行,还是单独到每个节点重启吧。
[root@node-1 ~]# systemctl restart ceph-mon@node-1.service
[root@node-2 ~]# systemctl restart ceph-mon@node-2.service
2、监控节点运行ceph -s命令发现too many PGs per OSD(896 > max 300),并出现集群健康告警?
解决:(1)[root@node-3 ~]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.97198 root default
-2 0.06580 host node-2
0 0.06580 osd.0 up 1.00000 1.00000
-3 0.45399 host node-4
1 0.45399 osd.1 up 1.00000 1.00000
-4 0.45219 host node-5
2 0.45219 osd.2 up 1.00000 1.00000
问题原因为集群osd 数量较少,测试过程中建立了大量的pool
(2)在Mon节点,[root@node-3 ~]# vim /etc/ceph/ceph.conf
mon_pg_warn_max_per_osd = 1000
[root@node-3 ~]# ceph-deploy --overwrite-conf admin node-1
[root@node-3 ~]# systemctl restart ceph-mon@node-3.service
[root@node-1 ~]# systemctl restart ceph-mon@node-1.service
3、启动OpenStack虚拟机失败,控制台显示no bootable device?
解决:镜像不应该为qcow2格式,应该为raw格式,raw格式的镜像能对接后端ceph存储。
# qemu-img convert image.qcow2 -O raw image2.raw
# glance image-create --name CentOS-20171025 --disk-format raw --container-format bare --os-distro centos --visibility public --file=file.raw –progress
4、roller的web界面部署ceph集群error现象?
解决:[root@roller ~]# roller task
[root@roller ~]# roller task delete -f --task 【任务ID】
[root@roller ~]# roller node --node-id 【error的节点序列号】--deploy --env 1 //重复执行执行error节点个数对应的相应次数
5、部署节点无法ssh到所有控制节点?
答:(1)默认是Public key登陆,已经把控制节点的ssh配置文件改为password auth还是不行。
(2)把部署节点的/root/.ssh/known_hosts的对应控制节点IP记录删除即可。
6、存储节点所有osd都down掉?(耗时最长的问题)
最终解决(NTP问题):起初,控制节点systemctl status ceph-mon@3.service正常,存储节点systemctl status ceph-osd@1.service状态均为active,但是osd就是起不来。
最开始尝试过几种方式排错,但没啥结果:
第一种(失败):观察到PG一直处于creating状态,参考网上资料说是crushmap的问题?
未解决:(1)# ceph osd getcrushmap -o crush.map
# crushtool -d crush.map -o crush.txt //反编译才能看的懂文件
# vim crush.txt //在ruleset中修改
step set_choose_tries 100
# crushtool --compile crush.txt -o better.crush.map
# ceph osd setcrushmap -i better-crush.map
参考文档:http://blog.csdn.net/u012320882/article/details/46553961
(2)PG一直处于creating的原因就是无法与osd进行关联,一旦互联完成,归置组状态应该变为 active+clean,从而客户端无法读写数据,那么问题应该放在OSD上面,而不是PG上面了。OSD异常是因为PG的状态是果。
第二种方式(失败):一度发现osd进程起不来,说是启动进程的请求太快了
(1)# service ceph status osd.0 或则systemctl restart ceph-osd@0.service 发现服务起不来
解决重启osd服务失败:Start request repeated too quickly启动请求太快了
# vim /etc/systemd/system/ceph-osd.target.wants/ceph-osd@0.service
----------
注释 StartLimitInterval = 30min
-------
# systemctl daemon-reload
# systemctl restart ceph-osd.target //启动本机上所有osd进程
存储节点执行# systemctl status ceph-osd@0.service,服务起来了,但是osd依然是down的状态,应该需要在控制节点的Mon服务上下功夫,osd进程好了后,需要向Mon进行报告,如果不报告,那么Mon依然认为osd挂了。
参考文档:http://www.cnblogs.com/wuyuxin/p/7041364.html
(2)但是ceph osd tree发现所有节点依然down掉,服务虽然起来了。执行ceph health detail发现
pg is stuck inactive ,current state creating,last acting 基本上可以定位ceph创建PG失败
根据第第一种方式的思考,发现PG状态是结果但不是原因。
(3)重启控制节点的mon服务试试,没用。
(4)在各个osd节点,执行ceph-disk activate-all无济于事
参考文档:https://www.2cto.com/net/201704/633243.html
控制节点ceph-deploy osd activate ceph01:/dev/sdb1 ceph02:/dev/sdb1激活也没用,注意权限最好为chown ceph:ceph /dev/sdb1
(5)在存储节点dmesg |grep scsi查看硬盘是否错误。或dmesg |less 查看内核错误
参考文档:http://docs.ceph.org.cn/rados/troubleshooting/troubleshooting-osd/
第三种方式(成功): 因为有人的提醒,我才关注NTP不对时问题。
(1)起初改了ntp.conf,重启ntpd服务,依然不对时。
(2)控制节点因为改了BIOS,硬件时钟是与10.109.192.5的NTP服务器互通,但是存储节点是私网地址无法与NTP互通,于是更改存储节点的/etc/ntp.conf,把server字段改为控制节点10.10.1.5,重启完ntpd服务,执行ntpq -p命令后,执行date命令但是时间依然不同步。
(3)无奈之下,date -s 10:28:12 强制临时改时间,而后,发现某个存储节点与控制节点能稍微同步,于是改其他存储节点与能同步的节点,重新再ntp.conf中定义,osd终于up了,如释重负。
(4)写入系统时钟,hwclock -w
7、因为交换机都是trunk模式,需要部署节点打vlan标签访问Horzion?
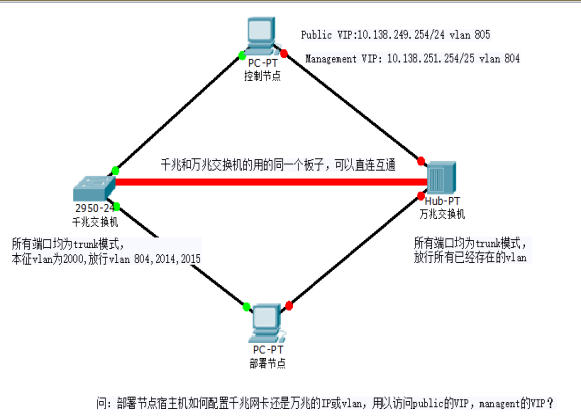
事先下载vconfig的rpm包,然后modprobe 8021q
解决:# vconfig add ensp0f0 805
# ifconfig ensp0f0.805 10.138.249.249/24 up
# ping 10.138.249.254
# ip r add 10.138.0.0/16 via 10.138.249.254 dev ensp0f0.805
8、无法ping通业务网络的VIP,进而无法访问云操web界面?
解决:(1)怀疑是不是刚改了haproxy的配置文件,而后重启crm resource p_haproxy服务的问题。
(2)ping不通VIP,但是可以ping通控制节点的业务网络IP。
(3)tail /var/log/messages 发现rabbitmq inet error,于是我重启rabbitmq-server无果
(4)而后,想执行neutron agent-list发现managent vip也不通,于是怀疑是harproxy的问题了。
(5)移走之前容器部署更改的haproxy配置文件,crm resource restart p_haproxy,发现可以Ping通VIP了。
(6)ip netns exec haproxy bash ip a,可以在某一个节点看到VIP,同时注意到其他节点并没有VIP,当其他节点正常之后,VIP也不会飘逸到其他节点上去。
最后,检查配置文件发现在1002-rabbitmq-api.cfg中,监听端口少写了个数字。
9、如何知道一个OpenStack虚拟机运行在哪台计算节点上面?
解决:# nova list --all-tenants
# nova show 【虚拟机的UUID】
10、如何用命令查看控制节点br-storage、br-ex、br-roller等网桥的走哪些网卡?
解决:ovs-vsctl show
11、如何判断服务器接口所连的交换机端口是哪个?
解决:[root@node-3 ~]# dhclient eth1
SWitch# show mac address_table |include ABCD ##ABCD是eth1网卡的后4位MAC地址,华为是display mac address_table
SWitch# conf t
SWitch# interface te1/0/1
SWitch# switchport mode trunk
SWitch# switchport trunk allowed vlan add 401-410,166
SWitch# show running-config interfaces te1/0/1
[root@node-3 ~]# ethtool eth1
SWitch# interface te1/0/1
SWitch# shutdown
[root@node-3 ~]# ethtool eth1 ##观察状态
12、服务器Ping不通交换机的vlan子接口的IP地址172.16.161.254?
解决:(1)交换机进行配置该eth3网卡所连交换机端口的所属vlan
SW# int te1/0/5 ## show running-config interface te1/0/5
SW# switchport mode access
SW# switchport access vlan 161 //是172.16.161.253所在vlan,用show running-config
SW# show mac_address_table
(2)[root@node-1 ~]# ifconfig eth3 172.16.161.162/25 up
[root@node-1 ~]# ip r add default via 172.16.161.254 dev eth3 ##添加默认路由
[root@node-1 ~]# ping 172.16.161.254 -I eth3 ##指定发包的源接口
[root@node-1 ~]# ovs-vsctl show |grep br-eth3
[root@node-1 ~]# ovs-vsctl del-port br-eth3 eth3
[root@node-1 ~]# ping 172.16.161.254 -I eth3
(3)原因是,eth3网卡连上了一个br-eth3网桥,而网桥又连着交换机,发包的时候,网桥不知道去向哪儿,可以增加br-eth3的IP地址,也可以删除网桥即可
13、搭建http形式的远程yum仓库,用于解决在多台openstack虚拟机上没有光驱镜像的yum仓库的问题。
节点一(ip为192.168.43.129)配置如下:
[root@node-1 ~]# yum install httpd -y ##物理节点的光盘里有httpd,或者把ISO文件拷贝到某个虚拟机上面也行
[root@node-1 ~]# mkdir /var/www/html/http_yum
[root@node-1 ~]# mount /dev/sr0 /var/www/html/http_yum
[root@node-1 ~]# systemctl stop firewalld && systemctl enable httpd && systemctl start httpd
节点二(ip为192.168.43.128)配置如下:
[root@node-2 ~]# cd /etc/yum.repos.d/
[root@node-2 yum.repos.d]# rename repo repo.bak *.repo
[root@node-2 yum.repos.d]# vim node-1.repo
[node-1]
name=node-1-httpd
baseurl=http://192.168.43.129:/http_yum
enabled=1
gpgcheck=0
[root@node-2 yum.repos.d]# yum repolist
[root@node-2 yum.repos.d]# yum list all|grep NetworkManager
14、ansible批量查看16台节点的网卡名称,MAC信息,千兆万兆带宽
(1)在一台可以上网的机器安装ansible软件
[root@ceph ~]# vim /etc/yum.conf
keepcache=1
[root@ceph ~]# yum clean all
[root@ceph ~]# yum install ansible createrepo -y
[root@ceph ~]# cd /var/cache/yum/x86_64/7/
[root@ceph ~]# cp base/packages/* /srv/ansible_repo
[root@ceph ~]# cp extras/packages/* /srv/ansible_repo
[root@ceph ~]# scp /srv/ansible_repo root@noode-2:/mnt/ansibe_repo
(2)在一台不能上网的机器配置ansible源
[root@node-2 ~]# cd /mnt/ansible_repo
[root@node-2 ~]# rpm -ivh createrepo*.rpm
[root@node-2 ~]# cd ..
[root@node-2 ~]# createrepo ansible_repo
[root@node-2 ~]# vim /etc/yum.repos.d/ansibl.repo
[ansible]
name=local ansible yum
baseurl=file:///mnt/ansible_repo
enabled=1
gpgcheck=0
[root@node-2 ~]# yum repolist
[root@node-2 ~]# yum install ansible -y
[root@node-2 ~]# vim /etc/ansible/hosts
[test]
node-01 ansible_ssh_pass=passw0rd
node-16 ansible_ssh_pass=passw0rd
------------------------------------
[root@node-2 ~]# ansible test -m -a "ifconfig |grep eth[0-9]|awk -F: '{print $1}"
node-1 | SUCCESS | rc=0 >>
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
[root@node-2 ~]# ansible test -m -a "ifconfig |grep ether|awk '{print $2}'"
node-1 | SUCCESS | rc=0 >>
ether 00:0c:29:19:80:06 txqueuelen 1000 (Ethernet)
ether 00:0c:29:19:80:10 txqueuelen 1000
[root@roller mnt]# ansible test -m shell -a "ethtool eth0|grep -i speed"
node-1 | SUCCESS | rc=0 >>
Speed: 1000Mb/s(Ethernet)
[root@roller mnt]# tar zcvf ansible.tar.gz ansible_repo/ ##把这个压缩包下载下来,防止无法连外网而无法安装ansible
15、为什么我明明使用1T的系统盘,但是进入lsblk一看,只有几个G左右的LVM,我以为是没分完区,再fdisk /dev/vda,分是能分成功,但是df和lsblk发现vda3只有1K?
解决:(最终发现是虚拟机模板镜像不合适)就是无论你分配多大配额上去,每个虚拟机的系统盘默认可用的就只有8G,但是并不是说系统盘只有8G,需要把没分配完的分区,然后扩展到LVM当中。
[root@host-172-16-1-229 ~]# lsblk
[root@host-172-16-1-229 ~]# fdisk /dev/vda
【一直回车,并且使用主分区,不使用扩展分区,w保存退出】
[root@host-172-16-1-229 ~]# partprobe
[root@host-172-16-1-229 ~]# pvcreate /dev/vda3
[root@host-172-16-1-229 ~]# vgextend centos /dev/vda3
[root@host-172-16-1-229 ~]# lvextend -L +192G /dev/centos/root ##192G是lsblk看到未分配的容量
[root@host-172-16-1-229 ~]# xfs_growfs /dev/centos/root
[root@host-172-16-1-229 ~]# df -Th
16、对更改配置(比如调整系统盘)后的openstack虚拟机做快照后,保存为glance模板镜像,而后,再创建新的虚拟机,主要用来解决新创建的虚拟机默认系统盘只有8G的问题。
解决:(1)在web界面,对扩展LVM后的云主机做快照
(2)在控制节点glance image-list可以看到快照的ID
(3)glance image-download 【快照ID】 --file centos72.raw
(4)glance image-create -name centos72 --visibility public --disk-format raw --os-distro centos --container-format bare --progress --file=centos72.raw
(5)在web界面使用新镜像创建新的虚拟机。
17、如何获取token?
解决:# source openrc
# keystone token-get //得到很长的ID便是
18、刚部署docker集群的时候,启动docker失败?
10月 16 15:12:07 bogon systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE
10月 16 15:12:07 bogon systemd[1]: Failed to start Docker Application Container Engine.
10月 16 15:12:07 bogon systemd[1]: Unit docker.service entered failed state.
解决:第一种情况:[root@bogon docker]# vim /etc/docker/daemon.json
{ "storage-driver": "devicemapper" }
[root@bogon docker]# systemctl restart docker
第二种万不得已的情况:[root@bogon docker]# yum remove docker //重新下载
第三种情况:[root@bogon docker]# rm -f /var/run/docker.sock
[root@bogon docker]# systemctl restart docker
先写这么多,后续还有更多的笔记需要补充....
