mysql索引
解决的问题
-
索引如何加快查询速度
-
B树的结构体
-
mysql有哪些索引
3.1 MySQL聚集索引和非聚集索引
3.2 B树索引, hash, fulltext, r-tree
3.3 创建索引 -
为什么选择B树做索引
-
innodb的索引模型
5.1 回表
5.2 覆盖索引what
5.3 覆盖索引优化实例
创建联合索引,形成覆盖索引,避免了回表,提高了查询效率。(身份证+姓名) -
myisam的索引模型
-
最左前缀原则
索引如何加快查询速度的
- 数据库的数据是存储在磁盘上的文件。比如innodb是存储在独立表空间的idb文件,myisam是存储在myi和myd文件。
文件系统的中文件在物理上存放的位置是[柱面,磁道,扇区],如果更快速的定位到数据所在是磁道和扇区,就能提高定位数据的速度。
B树索引
底层以B+树作为存储结构
Q:如何衡量索引好不好
A:IO渐进复杂度。当存放的数据越来越多,索引是否还更高效。
-
图解不同的树的插入和查询情况,理解为什么选择B树做索引,因为其IO复杂度随着数据规模增加变化不大(也就是IO次数增长不快)。
假设每1个节点读取数据都需要一次IO操作,那么层高增长太快的数据结构IO次数增长很快,层高固定的数据结构IO次数增长则不快。
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html -
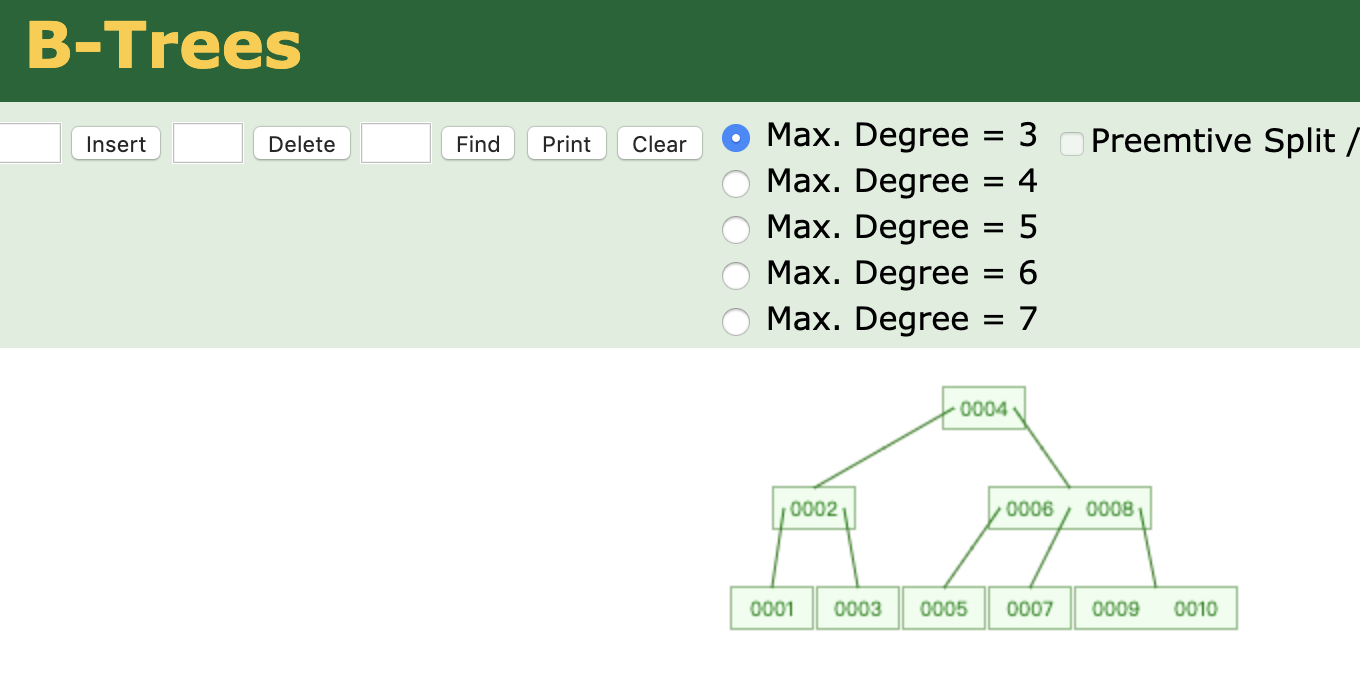
B-Trees
可以指定层高。
每个节点都会存放部分数据,没有冗余的数据存储。
不同子树的叶子不联通。
![]()
-
B+ Trees
在B-Trees基础上,增加了叶子节点的数据存储和叶子节点的关联。所有数据都放在叶子节点,并且叶子节点相关联。
![]()
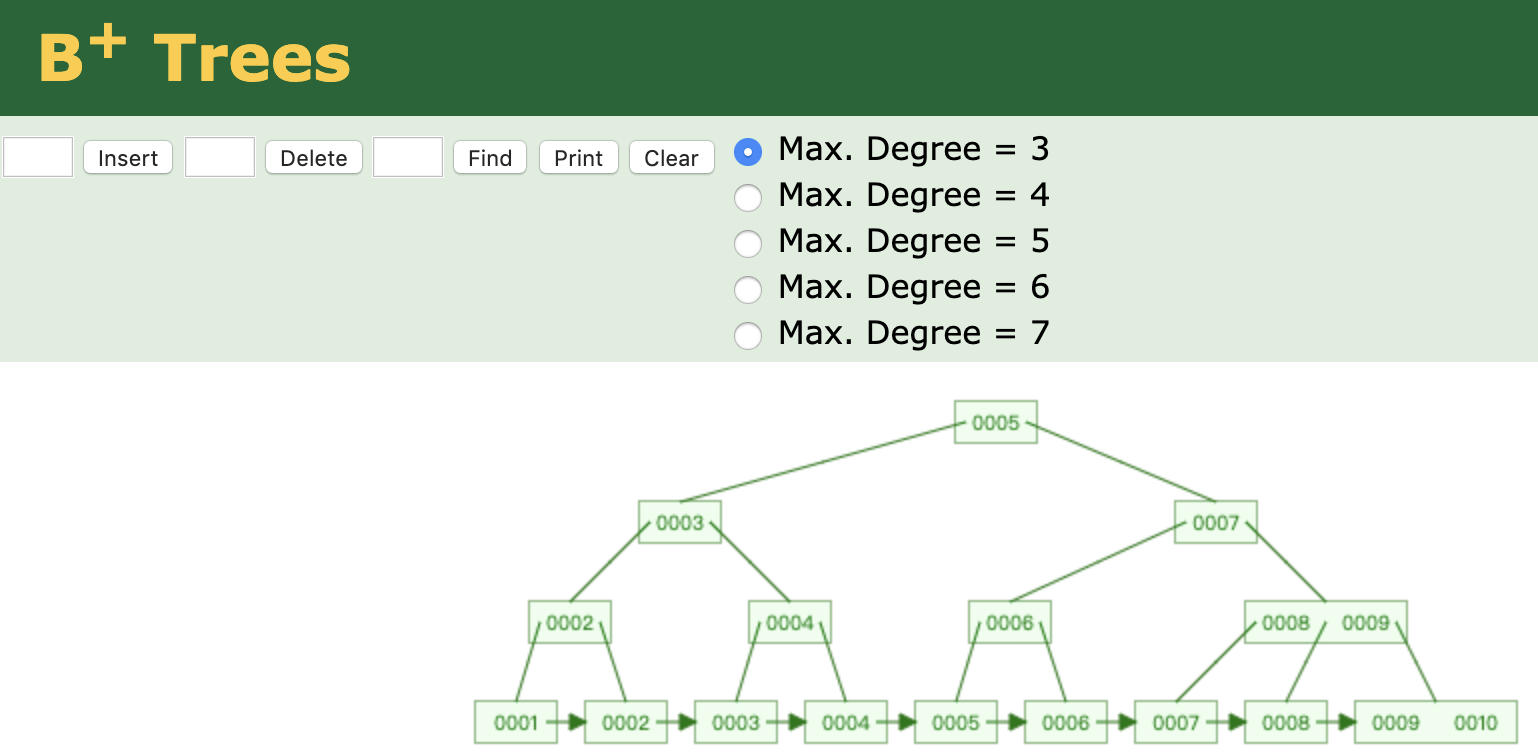
B+树比B树优势有三个:1.IO次数更少;2.查询性能更稳定;3.范围查询简便
附录1
mysql中索引的存储结构
- myisam的存储结构
一个表2列,id和name,id上加了索引(估计是主键索引),name加了普通索引。
0x123地址就是某一行数据在myd文件中的地址。如果没有索引,就需要遍历整个myd文件来查找数据。以下2句sql利用索引的过程
select * from table where id = 1
select * from table where name = 'james'
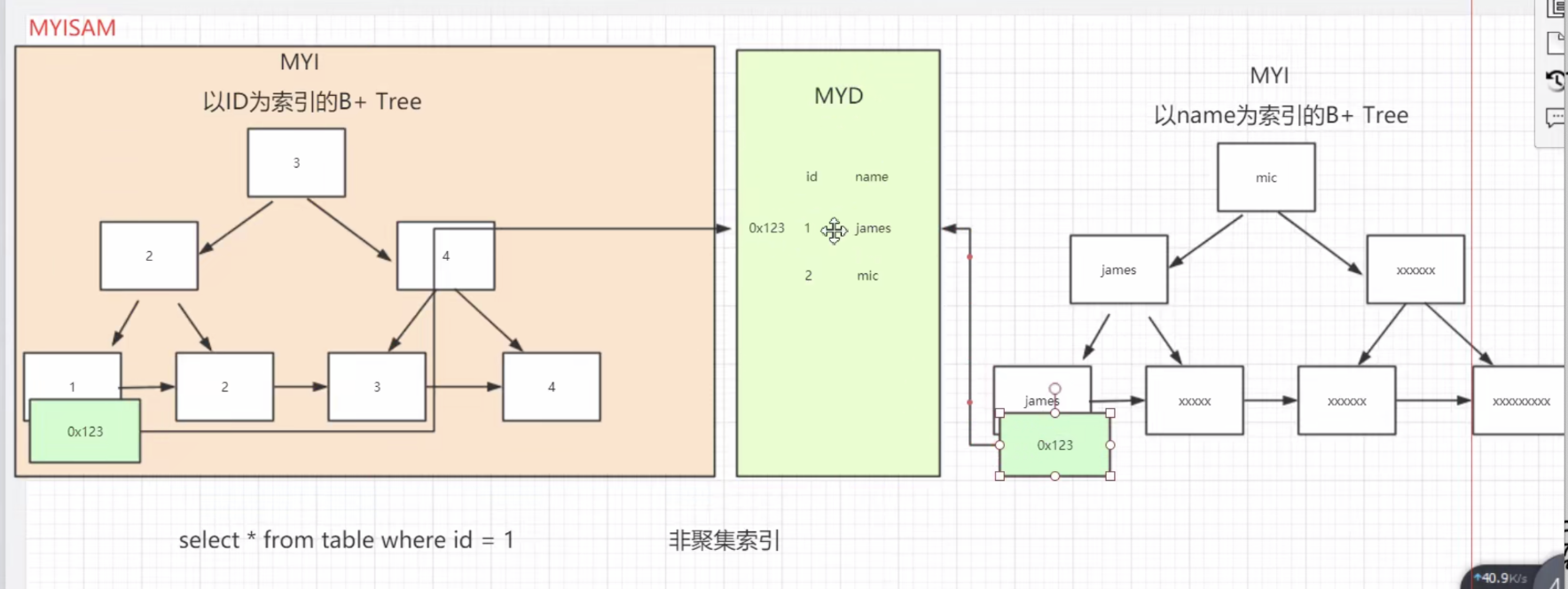
id和name都是非聚集索引。
- innodb中索引的存储结构
![]()
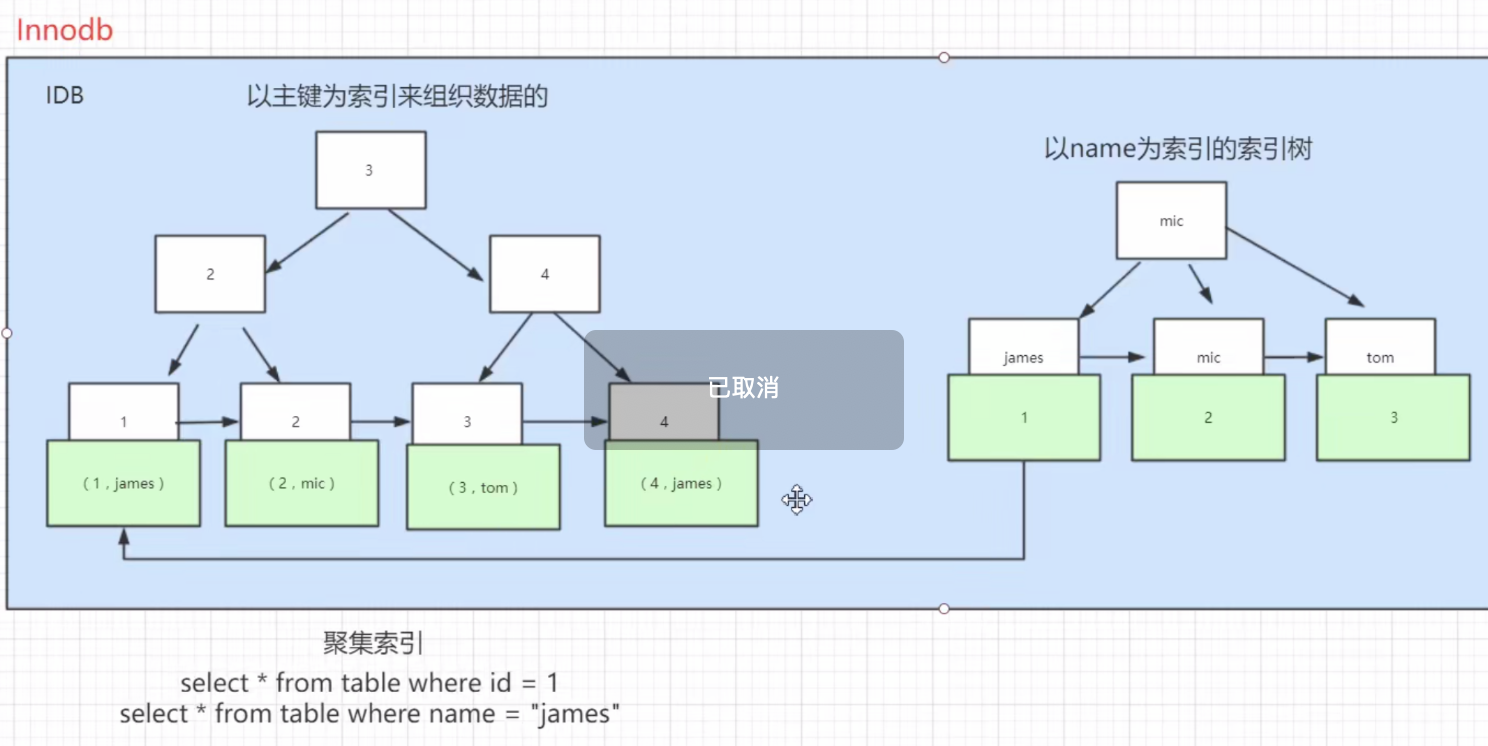
id是聚集索引,name是非聚集索引。
- 在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针或指向主键。
怎么理解呢?
聚簇索引的顺序,就是数据在硬盘上的物理顺序。一般情况下主键就是默认的聚簇索引。 - 一张表只能有一个聚集索引。聚集索引的顺序就是数据物理存储的顺序。
自己理解: 相邻的id,其对应的磁盘数据也相邻。相邻的name,对应的磁盘数据却几乎不会相邻。
联合索引和最左前缀匹配原理
- 联合索引的默认排序情况
Hash索引
不能做范围查询
FullText索引
R-Tree索引
空间索引
innodb和myisam的对比

索引的种类
参考附录2
[创建索引的语句](https://www.runoob.com/mysql/mysql-index.html
参考
-
MySQL之B树和B+树
InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万

 浙公网安备 33010602011771号
浙公网安备 33010602011771号